今天完成整理一篇学习笔记,有关BeatifulSoup和XPath使用比较。但是由于刚刚学习爬虫不久,许网页元素定位获取的方法和技巧还没有完全掌握,所以今天先按照自己的节奏跳过这篇作业,继续完成爬虫实战,等到对BeatifulSoup和XPath使用熟练后,再做一次深入详细的总结笔记。今天虽然不比较BeatifulSoup和XPath,但是我会在爬取中国天气网数据后,对爬取数据的三种储存方式(MySQL数据库、Mongo数据库和CSV文件)进行简单的比较。
1.作业要求:爬取中国天气网 你所在城市过去一年的历史数据
中国天气网URL:http://www.weather.com.cn/forecast/
2.思路分析:
中国天气网的数据是JS异步加载返回的,需要抓包获取数据,抓包后返回的数据结构是JSON形式,可以直接采用Python的json库中的json.loads()函数进行反序话转换成字典类型进行处理,具体分析步骤如图:
(1)具体获取数据的网址:http://www.weather.com.cn/weather40d/101060201.shtml
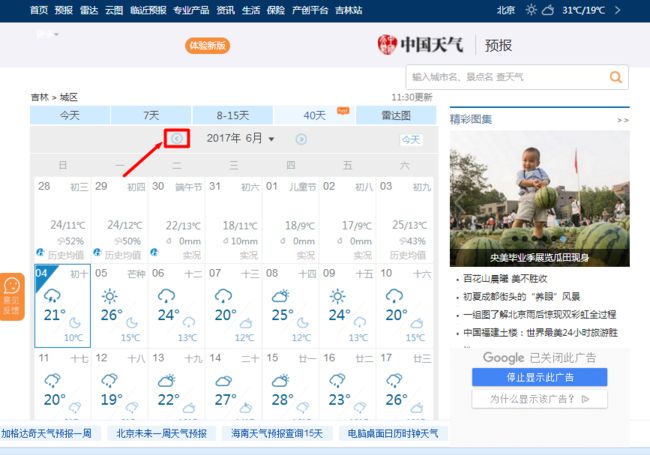
(2)点击切换月份按钮,查看不同月份天气,发现网页URL没有变化,判断为js异步加载数据
(3)按F12查看Network,点击切换月份,发现每次点击都有新的js加载出现:

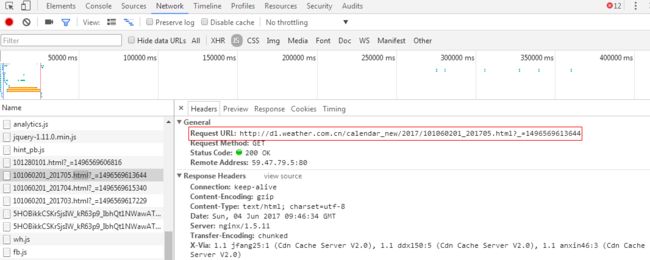
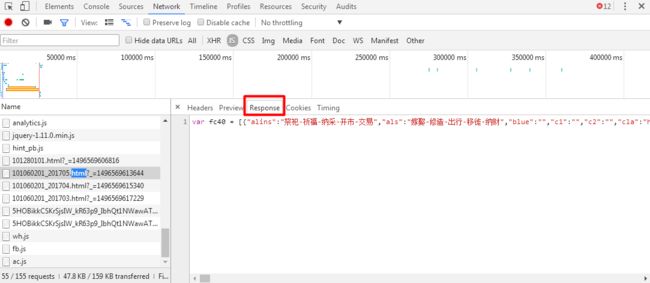
(4)分别查看动态加载的js的Headers和Response查看请求的URL规律和返回值。发现日期的变化包含在Request Url中,返回值即为json格式的天气数据。
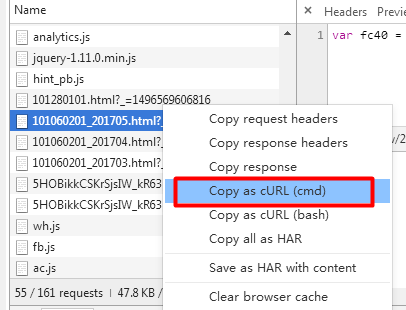
(5)Copy as cURL使用Postman发送请求测试,发现Headers中不携带Referer将返回403拒绝访问,所以在Headers请求中需携带Referer。

(6)程序代码1(存储到MySQL数据库):
import requests
import json
import pymysql
class WeatherSpider(object):
connect = pymysql.connect(
host='localhost',
user='root',
passwd='root',
db='test',
port=3306,
charset='utf8'
)
cursor = connect.cursor()
def __inti__(self):
pass
def request(self,url):
#请求头(不带Referer将返回403,用Postman测试)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'http://www.weather.com.cn/weather40d/101060201.shtml'
}
return requests.get(url,headers=headers)
def create_url(self):
year = '2016'
for i in range(1,13):
month = str(i) if i > 9 else "0" + str(i)
url = "http://d1.weather.com.cn/calendar_new/" + year + "/101060201_" + year + month + ".html"
self.get_data(url)
#关闭数据库链接,释放资源
self.connect.close()
def get_data(self,url):
respone = self.request(url).content
json_str = respone.decode(encoding='utf-8')[11:]
weathers = json.loads(json_str)
for weather in weathers:
self.cursor.execute("use test")
self.cursor.execute("insert into jilin_weather_tbl (date,week,hmax,hmin,hgl) values(%s,%s,%s,%s,%s)",(weather.get('date'),'星期'+weather.get('wk'),weather.get('hmax'),weather.get('hmin'),weather.get('hgl')))
self.connect.commit()
if __name__ == '__main__':
jl_weather = WeatherSpider()
jl_weather.create_url()
实现效果图:
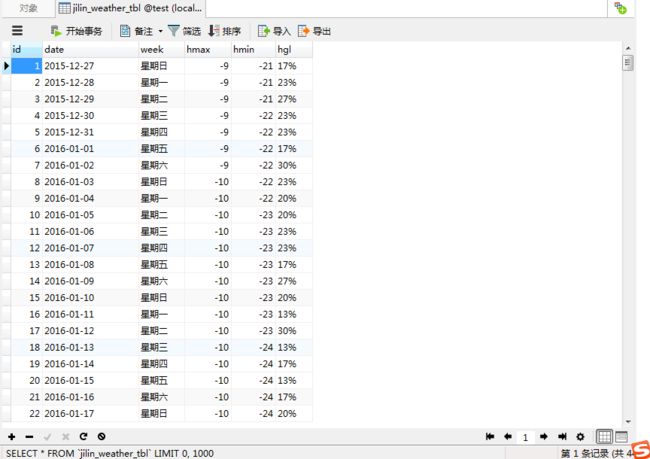
(7)程序代码2(存储到Mongo数据库)
import requests
import json
import pymongo
class WeatherSpider(object):
client = pymongo.MongoClient('localhost', 27017)
mydb = client['mydb']
jilin_weather = mydb['jilin_weather']
def __inti__(self):
pass
def request(self,url):
#请求头(不带Referer将返回403,用Postman测试)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'http://www.weather.com.cn/weather40d/101060201.shtml'
}
return requests.get(url,headers=headers)
def create_url(self):
year = '2016'
for i in range(1,13):
month = str(i) if i > 9 else "0" + str(i)
url = "http://d1.weather.com.cn/calendar_new/" + year + "/101060201_" + year + month + ".html"
self.get_data(url)
def get_data(self,url):
respone = self.request(url).content
json_str = respone.decode(encoding='utf-8')[11:]
weathers = json.loads(json_str)
for weather in weathers:
#构建插入Mongo数据库的字典data
data = {
'日期': weather.get('date'),
'星期': weather.get('wk'),
'最高温度':weather.get('hmax'),
'最低温度':weather.get('hmin'),
'降水概率':weather.get('hgl')
}
self.jilin_weather.insert_one(data)
if __name__ == '__main__':
jl_weather = WeatherSpider()
jl_weather.create_url()
实现效果图:
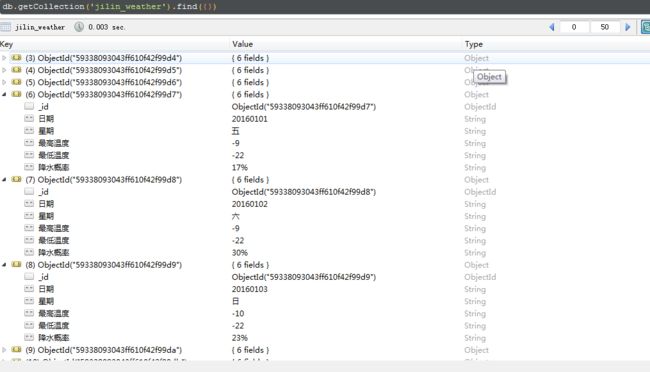
(8)程序代码3(存储到CSV文件)
import requests
import json
import csv
class WeatherSpider(object):
#csv文件表头
with open('jilin_weather.csv', 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(['日期', '星期', '最高温', '最低温', '降水概率'])
def __inti__(self):
pass
def request(self,url):
#请求头(不带Referer将返回403,用Postman测试)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'http://www.weather.com.cn/weather40d/101060201.shtml'
}
return requests.get(url,headers=headers)
def create_url(self):
year = '2016'
for i in range(1,13):
month = str(i) if i > 9 else "0" + str(i) #给一位数前加0
url = "http://d1.weather.com.cn/calendar_new/" + year + "/101060201_" + year + month + ".html"
self.get_data(url)
def get_data(self,url):
respone = self.request(url).content
json_str = respone.decode(encoding='utf-8')[11:]
weathers = json.loads(json_str)
for weather in weathers:
#构建插入csv文件的列表data
data = [weather.get('date'),weather.get('wk'),weather.get('hmax'),weather.get('hmin'),weather.get('hgl')]
with open('jilin_weather.csv', 'a') as f: #以a(append)的方式追加写入
f_csv = csv.writer(f)
f_csv.writerow(data)
if __name__ == '__main__':
jl_weather = WeatherSpider()
实现效果图:
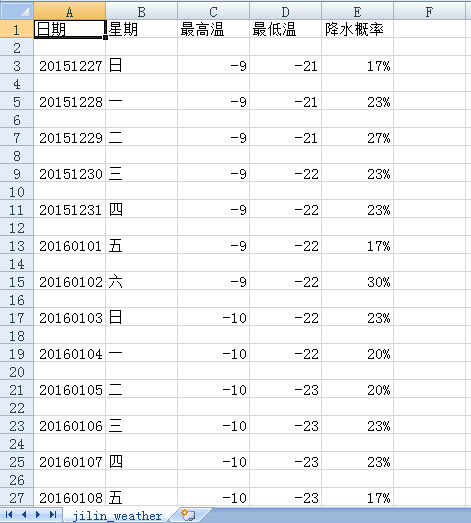
这三种数据的存储方式,代码分别引用了Python的pymysql库、pymongo库和csv库
1.使用MySQL数据库需要提前建立数据表,并设定好对应存储数据的字段,字段的类型(int、varchat、date......)以及字段的长度。
2.Mongo数据库我也是刚刚使用,但是对这个非关系型数据库比较有好感,因为使用它不必向MySQL数据库那样,要建立数据表和设定字段,给我的感觉就是直接将Python字典型数据直接“怼”进去既可以,比较方便。
3.将数据保存到csv文件的方式比较简单,比较适合没有搭建数据库环境和没有数据库基础的使用者,这种类似Excel表格的文件格式,在获取数据后可以转换为Excel文件,利用VBA和Excel函数进行数据的处理。
以上仅是个人近阶段学习的总结,可能存在着许多片面和理解不到位的地方,还请大家不吝赐教,批评指正。