
scrapy
scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
安装scrapy
scrapy支持Python2.7和Python3.4。你可以通过pip安装scrapy。
pip install scrapy
创建scrapy应用
创建scrapy应用非常简单。首先进入到你想创建scrapy工程的目录,然后在终端执行:
scrapy startproject your-project-name
然后它会创建如下目录及文件:
your-project-name/
scrapy.cfg # 配置文件
your-project-name/ # python模块
__init__.py
items.py # model定义文件
middlewares.py # 中间件文件
pipelines.py # 管线文件
settings.py # 设置文件
spiders/ # 防止爬虫文件的目录
__init__.py
接着你进入到你创建的工程目录中执行以下命令来创建爬虫文件
scrapy genspider xxx xxx.xxx.com #第一个参数为爬虫文件的名称,第二个参数为需要爬取的域名
这样,基本的框架就搭好了。
scrapy架构
下图展示了scrapy的架构,包括组件及在系统中发生的数据流转。
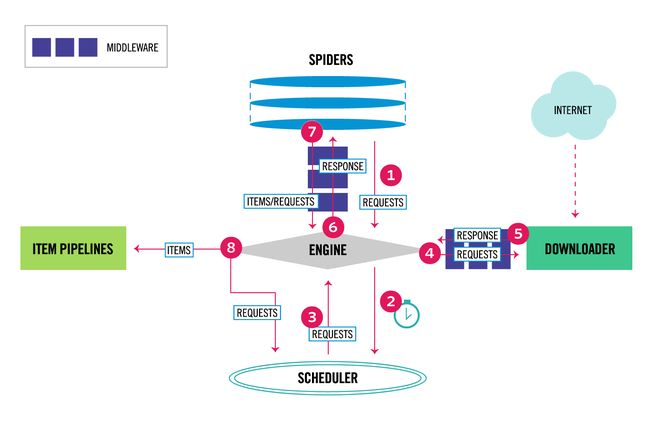
1.引擎从spider中获取初始的爬取请求;
2.引擎把这个请求放入到Scheduler组件的队列中,并且去获取下一个爬取请求;
3.Scheduler从队列中获得下一个请求返回给引擎;
4.引擎通过Downloader中间件把请求发送给Downloader组件;
5.一旦页面完成下载,Downloader产生一个响应并通过Downloader中间件发送给引擎;
6.引擎收到来自Downloader的响应,通过Spider中间件发送给spider;
7.spider处理这个响应并返回item,接着通过Spider中间件发送下一个爬取请求给引擎;
8.引擎发送处理过的item给Item Pipelines,接着向Scheduler索取下一个请求;
9.程序不停的从步骤一开始重复,直到Scheduler中没有请求为止。
scrapy例子
以安居客的二手房为例子,我们来做一个爬虫demo。
1.创建一个scrapy工程。
scrapy startproject Anjuke
2.进入工程创建爬虫文件。
scrapy genspider anjuke hangzhou.anjuke.com
3.创建一个初始request请求。打开anjuke.py,加入以下代码
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://hangzhou.anjuke.com/sale/'
yield scrapy.Request (url=url, headers=self.headers)
4.定义item。打开items.py,定义需要解析的字段(item相当于model)。
name = scrapy.Field() ##小区
address = scrapy.Field() ##位置
totalPrice = scrapy.Field() ##总价
unitPrice = scrapy.Field() ##单价
size = scrapy.Field() ##大小
floor = scrapy.Field() ##楼层
roomNum = scrapy.Field() ##房间数
buildTime = scrapy.Field() ##建造时间
publisher = scrapy.Field() ##发布人
5.解析item。回到anjuke.py,解析返回的reponse,并赋值给item。xpath是一种用来确定XML文档中某部分位置的语言。可以通过chrome的开发者工具中的copy xpath快速给出所需信息的路径。这边解析了前面50个页面。
page = 1
def parse(self, response):
houseList = response.xpath ('//*[@id="houselist-mod-new"]/li')
for div in houseList:
item = {}
houseDetails = div.xpath ('./div[@class="house-details"]')
commAddress = houseDetails.xpath ('./div[3]/span/@title').extract_first ()
item['name'] = commAddress.split ()[0]
item['address'] = commAddress.split ()[1]
item['roomNum'] = houseDetails.xpath('./div[2]/span[1]/text()').extract_first()
item['size'] = houseDetails.xpath('./div[2]/span[2]/text()').extract_first()
item['floor'] = houseDetails.xpath ('./div[2]/span[3]/text()').extract_first ()
item['builtTime'] = houseDetails.xpath ('./div[2]/span[4]/text()').extract_first ()
item['publisher'] = houseDetails.xpath ('./div[2]/span[5]/text()').extract_first ()
proPrice = div.xpath('./div[@class="pro-price"]')
item['totalPrice'] = proPrice.xpath('./span[@class="price-det"]/strong/text()').extract_first() +\
proPrice.xpath('./span[@class="price-det"]/text()').extract_first()
item['unitPrice'] = proPrice.xpath('./span[@class="unit-price"]/text()').extract_first()
yield item
if self.page <= 50:
self.page += 1
next_url = response.xpath('//div[@class="multi-page"]/a[last()]/@href').extract_first()
yield scrapy.Request(url=next_url,callback=self.parse,dont_filter=True)
6.存储item。这边使用了mysql来存储爬取的数据。打开pipelines.py。首先在open_spider函数中打开数据库,删除原先的表,并新建一张houseinfo表。接着在process_item函数中处理一下item,并把数据插入到表中,最后返回item。
def open_spider(self, spider):
self.conn = pymysql.connect(
host="127.0.0.1",
user="root",
password="",
database="anjuke",
charset='utf8',
cursorclass=pymysql.cursors.DictCursor )
self.cursor = self.conn.cursor()
self.cursor.execute("drop table if exists houseinfo")
createsql = """create table houseinfo(name VARCHAR(32) NOT NULL,
address VARCHAR(32) NOT NULL,
totalPrice VARCHAR(32) NOT NULL,
unitPrice VARCHAR(32) NOT NULL,
size VARCHAR(32) NOT NULL,
floor VARCHAR(32) NOT NULL,
roomNum VARCHAR(32) NOT NULL,
buildTime VARCHAR(32) NOT NULL,
publisher VARCHAR(32) NOT NULL,
area varchar(8) not null)"""
self.cursor.execute(createsql)
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
def process_item(self, item, spider):
item['totalPrice'] = item['totalPrice'].split('万')[0]
item['unitPrice'] = item['unitPrice'].split('元')[0]
item['builtTime'] = item['builtTime'].split('年')[0]
item['size'] = item['size'].split('m')[0]
area = item['address'].split('-')[0]
insertsql = 'insert into houseinfo(name, address,totalPrice, unitPrice, size, floor, roomNum, \
buildTime, publisher,area) \
VALUES ("%s", "%s","%s", "%s","%s", "%s","%s", "%s","%s","%s")' % \
(item['name'], item['address'], item['totalPrice'], item['unitPrice'], item['size'], item['floor'], item['roomNum'], item['builtTime'], item['publisher'],area)
try:
self.cursor.execute(insertsql)
self.conn.commit()
except Exception as e:
self.conn.rollback()
print(e)
return item
7.最后设置一下爬取的策略及配置。打开settings.py。这边设置了user_agent,robotstxt_obey,download_delay等参数来进行初步的反扒策略。
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Anjuke.pipelines.AnjukePipeline': 300,
}
这样,一个简单的爬虫程序就完成了。详细的代码可以查看https://github.com/bigjar/Anjuke.git。
参考
1.Scrapy 1.5 documentation