1.OID和主键生成策略
1.1.主键(Primary key):
在数据库表中能够唯一识别每一行记录的一个字段或者多个字段的组合.
主键特点:
非空且唯一,简单.一般的使用一个列来表示主键.
主键分类:
| 名称 | 区别 |
|---|---|
| 自然主键 | 主键具有业务含义,比如身份证号码,必须要收到输入. |
| 代理主键 | 主键没有业务含义,仅仅起唯一标识,一般由数据库服务器自动生成. |
| 单字段主键 | 在一张表中使用某一列作为主键. |
| 复合主键 | 在一张表中使用多列一起,联合作为主键. |
1.2.OID
1.在hibernate中,一个对象必须要有一个id,这个id对应数据库的主键;
2.在hibernate当中,把对象中对应数据表主键的属性,对象标识符(OID).
3.OID可以是单个属性,也可以使多个属性(复合主键的映射)
-
4.OID的重要作用:
1.OID在Hibernate中唯一标识了一个对象(在数据库表中主键唯一的表示了一行数据);
2.在一级缓存中,Type+ID唯一标识了一级缓存中相同的数据 .
3.一般情况,在domain当中,需要用OID属性来重写equals和hashcode法方法 5.单个OID都使用
元素来映射,name代表OID属性的名称,column表示对应表中主键的列名. 6.id元素都有一个generator子元素,规定了主键的生成策略.
自然主键:assigned,在保存之前必须手动设置值,assigned只针对于自然主键

保存改对象的时候,必须手动输入该值.
1.3.代理主键的生成方式(让数据库生成或让hibernate生成):
- 1:uuid:使用uuid作为主键值 ,使用uuid这一种生成策略,此时主键必须是String类型.
- 2:increment:增长方式.
1,hibernate生成主键
2,先查询当前表id最大值,自增1后作为当前对象的id
3,主键类型可以递增;不能在集群(多个hibernate应用使用同一个数据库)的情况下使用; - 3:identity:
1,使用数据库本身的id生成策略:MySQL:auto_increment;
2,数据库本身必须支持id自动增长策略,Oracle不能使用. - 4:sequence:序列
1,使用序列生成id,如果只配置sequence,会创建一个默认的序列hibernate_sequence;
2,数据库本身必须支持序列
//可以通过sequence参数来指定表对应的序列生成器的名字
IDDOMAIN_SEQ
- 5:native:
1,使用数据库本地的主键生成策略
对于mysql:auto_increment;
对于oracle:使用默认的sequence; - 6:org.hibernate.id.enhanced.TableGenerator
1,相当于序列生成器,hibernate使用一张hibernate_seqences这样的表来模拟序列生成器
2,如果只配置org.hibernate.id.enhanced.TableGenerator,相当于所有的表都使用default这一个序列生成器
3,会造成很多额外的SQL
IDDOMAIN_SEQ
1.4.选择:
1,自然主键还是代理主键;
2,使用数据库来生成主键还是使用hibernate来生成主键(应用是否需要移植数据库)
是否在集群环境中使用
3,性能问题
4,一般来说,使用native就可以了.

2.Session中的方法
常用方法(已学):
Transaction beginTransaction():开启一个事务
Transaction getTransaction():获取一个事务
Serializable save(Object o):保存一个对象
void update(Object o):修改一个对象
void delete(Object o):删除一个对象
Object get(Class type,Serializable id):根据主键查询指定类型的对象
Query createQuery(String hql):根据hql创建一个查询对象
void close():关闭Session
void clear():清除一级缓存所有对象
void evict(Object o):清除一级缓存中制定的对象
按照方法的功能,把session的方法分为:
2.1.事务相关:
Transactionsession.beginTransaction():标记打开当前session绑定的事务对象。
Transactionsession.getTransaction():得到和当前session绑定的事务对象。
2.2.一级缓存相关:
session.clear():清除一级缓存中所有的对象。
boolean contains(Object entity):判断一级缓存中是否有给定的对象。
session.evict(Object entity):从一级缓存中清除指定的对象。
session.flush():把一级缓存中的脏数据同步到数据库中。
session.refresh(Objectentity):强制重新查询对象,相当于把数据库中的数据同步到一级缓存中。
2.3.持久化操作相关:
session.delete(Objectentity):从数据库中删除一个对象
session.update(Objectentity):更新一个对象
session.get(ClassentityType,Serializableid):根据主键查询一个对象
session.load(ClassentityType,Serializableid):根据主键加载一个对象
1.load方法是一个延迟加载(lazy-load)的方法;把对象的获取(SQL)延迟到了真正使用这个对象的时候才发送;
2.真正使用?当使用一个非主键属性的时候;
3.load实现原理?使用动态代理,为load的domain动态创建了一个子类,在这个子类中,复写所有非主键调用方法,在这些方法中,去发送.
session.save(Objectentity):保存一个对象
1.同步JPA的接口方法;
2.和save的区别:在没有事务环境下,save方法会发送INSERT SQL,persist不会;)
session.saveOrUpdate(Objectentity):如果对象没有保存到数据库,则保存,如果已经保存过,则更新。
session.merge(Objectentity):等同于saveOrUpdate方法。
1.同步JPA的接口方法;
2.和saveOrUpdate的区别:在没有事务环境下,saveOrUpdate方法会发送INSERT SQL,merge不会;
2.4.其他:
session.close():关闭session,相当于关闭了和session关联的connection对象。关闭session之后,就不能再使用这个session完成持久化相关的操作。
session.doWork(Workwork):Hibernate提供给程序员直接使用JDBC的一个途径。
session.doReturningWork(ReturningWork):Hibernate提供给程序员直接使用JDBC的一种途径。
Serializablesession.getIdentifier(Objectentity):得到一个对象的主键值
session 上面所有的方法都在促使对象的状态发生改变.
2.5.Hibernate中对象保存的方法:
persist和方法save方法都表示保存一个对象,但是persist方法必须运行在事务空间内.
save(e); //没有事务环境,也会发送INSERT INTO语句
persist(e);//没有事务环境,不会发送INSERT INTO语句.
Hibernate实现了JPA的规范,就得提供JPA中的方法,而在JPA中持久化操作的方法就叫做:persist.
建议使用persist方法.
2.6.保存或更新操作方法:
session.saveOrUpdate(Objectentity):如果对象没有保存到数据库,则保存,如果已经保存过,则更新。
- 如果对象存在OID,则update
- 如果对象不存在OID,则save.
merge方法相当于saveOrUpdate方法.必须运行在事务空间内,是JPA规范的方法.
2.7.加载或查询指定类型和IOD的一个对象:
Object obj = session.load(Classs type,Serializable id)
Object obj = session.get(Classs type,Serializable id)
- get方法返回的总是持久化状态的对象;get方法立刻发送一条SELECT语句,结果可以用if-null来判断.
- load方法并不会立刻发送一条SELECT语句去查询对象,而要到真正在使用(使用一个非主键属性)这个对象的时候,才会去发送SELECT语句,我们把这种方式叫做延迟加载(lazy-load/懒加载).
如果对象没有被加载过,则发送一条SELECT语句,去加载对象,再返回属性值.
load方法返回的对象永远不可能为空,所以不能使用ifnull来判断,如果load了一个不存在的id的对象,在使用的时候报错;
load方法返回的对象是持久化对象;
load方法也会从一级缓存中获取数据
load原理:
- 1).Hibernate框架的中的javassist组件创建了代理类以及对象.
- 2).该对象提供了非主键属性的getter方法和toString方法.
- 3):该对象存在是否加载完毕的状态,访问属性是先判断对象是否加载完毕,如是直接返回该属性之,否则发送SQL查询该对象.
如果在session关闭之前没有去实例化延迟加载对象,报错:
LazyInitializationException: could not initialize proxy - no Session.
LoadEventListener$LoadType类
一般的,load方法是Hibernate内部使用的,我们就使用get方法即可.

3.持久化对象的状态
3.1.通过三个问题,引出对象状态.
-
问题1: 主键生成策略不同,save操作时发生INSERT语句的时机不同.
native: 在执行save方法的时候发送INSERT SQL.
increment: 在提交事务的时候,才发送INSERT SQL. 问题2: 删除对象的时候,没有立刻发生DELETE语句,而是在提交事务的时候发送的.
问题3: 为什么在事务环境下,通过get方法得到的对象,只要修改了属性值,会发生UPDATE语句.
结论:
通过上述三个测试,我们发现Session中的方法和SQL的执行没有任何关系.
问题:那到底SQL的执行和什么有关系呢?有什么关系呢? ---->和对象的状态有关系.
3.2.持久化对象的状态有哪一些,怎么划分的?
划分的规则:
1):当前对象是否有OID(该对象在表中对应有一个id值.)
2):对象是否被Session所管理(对象是否在一级缓存中).
| 状态 | - | 特点 |
|---|---|---|
| 临时状态/瞬时态(transient) | 刚刚用new语句创建,没有被持久化,不处于session中。 | 没有oid,不在session当中. |
| 持久化状态(persistent) | 已经被持久化,加入到session的缓存中。 | 有oid,在session当中 |
| 脱管态/游离状态(detached) | 已经被持久化,但不处于session中。 | 有oid,不在session当中 |
| 删除状态(removed) | 对象有关联的ID,并且在Session管理下,但是已经计划被删除。 | 有oid,在session当中,最终的效果是被删除. |
判断规则:
对象是否有OID,判断对象是否与Session关联(被Hibernate管理)
3.3.状态的之间的转换:
- Transient(临时状态/瞬时状态):
特点,没有OID,不被Session所管理.情况1):new语句刚创建了一个对象.
情况2):删除状态的对象,在事务提交之后,对象处于临时状态.
临时状态是没有ID的,测试可以打印该对象的ID,发现存在ID.
--->设置hibernate.cfg.xml的属性:hibernate.use_identifier_rollback=true
-
Removed(删除状态):
特点:此时有OID,被Session所管理中,但是最终会被删除.情况1:delete方法让持久化状态和游离状态变成删除状态.
但是删除状态的对象必须等到session刷新(flush),事务提交时才真正从数据库中删除. -
Persistent(持久化状态):
特点:有OID,被Session所管理.情况1):save方法把临时状态转换为持久化状态.
情况2):save方法把游离对象变成另一个持久化状态.
保存一个对象之后,提交事务/关闭Session,此时对象处于游离状态,再创建新的Session来保存该对象.
情况3):get和load方法返回的是持久化对象.
情况4):Query.list方法返回的是持久化对象,在处理大数据量的时候,需要及时清理一级缓存(分页查询).
情况5):update方法把游离对象变成持久化对象. -
Detached(游离状态/托管状态):
特点:有OID,但是不被Session所管理(不在一级缓存中).情况1):session.close()方法把所有的持久化对象变成游离对象.
情况2):session.clear()方法把所有持久化对象变成游离对象.
情况3):session.evivt(Object)方法把制定的持久化对象变成游离对象.
情况4):使用new创建对象,并设置OID(数据库存在该ID);
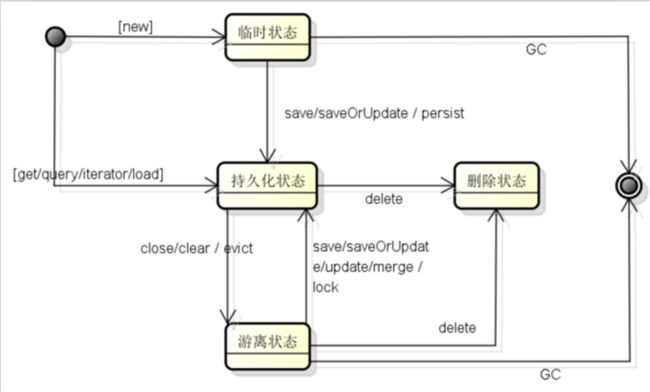
3.4.总结:
Session中的方法仅仅只是改变对象的状态,不负责发送SQL/默认情况下事务提交的时候发送SQL.
- 问题1: 主键生成策略不同,save操作时发生INSERT语句的时机不同.
native: 在执行save方法的时候发送INSERT SQL.
increment: 在提交事务的时候,才发送INSERT SQL.
原因是:save方法仅仅是把临时状态的对象转换为持久化状态,本身不负责发送SQL.
临时状态的对象没有IOD,调用save方法之后,变成持久化状态,就必须有OID.
此时:从临时状态转换为持久化状态,只需要获取OID即可.
native:表示数据库主键的自增长,只有发送SQL,才能获取主键,----->OID.
increment:先发送SELECT语句查询id,(拥有了OID),不需要发送INSERET来获取ID. - 问题2: 删除对象的时候,没有立刻发生DELETE语句,而是在提交事务的时候发送的.
原因是:delete方法仅仅是改变对象的状态,本身不负责发送SQL.
- 问题3: 为什么在事务环境下,通过get方法得到的对象,只要修改了属性值,会发生UPDATE语句.
原因是:通过get查询操作得到的对象处于持久化状态(有OID,存在于一级缓存中).
此时,修改了非IOD的属性值,发现一级缓存中的数据和快照区域的数据不同(脏数据),
Hibernate就会做比较(一级缓存和快照区),发送不同,就发送UPDATE语句,做数据同步.
session的flush方法,负责把一级缓存中的脏数据同步到数据库中去.
User u = new User(); //临时状态
u.setName("XX");
session.save(u);---->SELECT max(id) //持久化状态
//持久化状态可以被删除.
User u = session.get(User.class,1L);
session.delete(u);
User u = new User();
u.setId(1L);//游离状态
-----------------------------------

4.集合映射
之前对象中的属性:都是简单数据类型(一个类型对应一个值.String,Integer,Date)
属性是集合类型:
案例:根据一个用户有一个邮箱地址,分析表结构的设计.
因为此时:一个用户最多只有一个邮件地址,可以直接邮件作为用户表的一列.
如何一个用户有多个邮箱地址,分析表结构的设计.
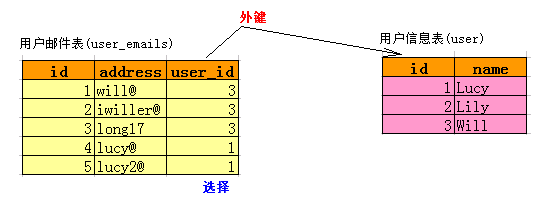

存储多个数据,此时只能使用集合.
Set/List/Map.
Set:不记录添加顺序,元素不能重复.
List:记录添加的顺序,元素运行重复.
Map:存储键值对,每次存储都要存储key和value.
在开发中灵活选用,根据各自的特点和具体的需求.
Set set = new HashSet();
List list = new ArrayList();
Map map = new HashMap();
集合属性只能以接口声明(当持久化某个实例时, Hibernate 会自动把程序中的集合实现类替换成 Hibernate 自己的集合实现类),

集合属性只能以接口声明(当持久化某个实例时, Hibernate 会自动把程序中的集合实现类替换成 Hibernate 自己的集合实现类
---->PersistentSet
---->PersistentList

选择:
如果集合类型使用Set,则使用
如果集合类型使用List,则使用
Hibernate对集合账号的原生支持两种排序方式(了解):
- 1:内存中排序,Hibernate把数据加载到内存中的Java集合中,根据集合自身的功能来排序(自然排序/定制排序).
- 2:数据库排序,Hibernate通过SELECT语句从数据库查询数据的时候,使用ORDER BY字句进行排序.
| 排序属性 | ||||
|---|---|---|---|---|
| sort属性 | 支持 | 不支持 | 不支持 | 支持 |
| order-by属性 | 支持 | 支持 | 不支持 | 支持 |
需求:根据邮件的地址逆序排序.
order-by="address DESC":
注意:address表示数据库表的列名.
5.对象之间的关系(写少量代码):
5.1.依赖关系:
如果A对象离开了B对象,A对象就不能正常编译,则A对象依赖B对象.
在A类使用到了B(调用了B的方法,调用了B的字段).
//依赖关系:
class B1{}
class B2{}
class A{
B2 b2;//A依赖B2
void doWork(){
B1 b1 = new B1();//A依赖于B1
}
}
5.2.关联关系:
A对象依赖B对象,并且把B对象作为A对象的一个字段,则A和B是关联关系.
class B{}
class A{
B b;//关联关系
}
class Deparment{
//一对多
List employees = new ...;
}
class Employee{
}
Deparment d = new ...();
Employee e1 = new ....();
Employee e2 = new ....();
Employee e3 = new ....();
d.getEmployess().add(e1);
d.getEmployess().add(e2);
d.getEmployess().add(e3);
class Deparment{}
class Employee{
//多对一
Department dept;
}
Deparment d = new ...();
Employee e1 = new ....();
Employee e2 = new ....();
Employee e3 = new ....();
e1.setDept(d);
e2.setDept(d);
e2.setDept(d);
按照多重性分:
| 关联关系 | 解释 | 例子 |
|---|---|---|
| 1).一对一 : | 一个A对象属于一个B对象; 一个B对象属于一个A对象. |
QQ号码对应一个QQ空间. |
| 2).一对多: | 一个A对象包含多个B对象. | 一个部门包含多个员工对象, 此时我们使用集合来封装B对象. |
| 3).多对一: | 多个A对象同属于一个B对象, 并且每个A对象只能属于一个B对象. 设计表的时候:外键在many这一方 在开发设计中:添加一个many方对象的时候, 往往通过下拉列表去选择one方. |
多个员工对象属于同一个部门. |
| 4).多对多 | 一个A对象属于多个B对象,一个B对象属于多个A对象. 通过中间表来表示关系. |
一个老师可以有多个学生, 一个学生可以有多个老师. |
按照导航性分:
如果通过A对象中的某一个属性可以访问该属性对应的B对象,则说A可以导航到B.
| - | - |
|---|---|
| 1).单向: | 只能从A通过属性导航到B,B不能导航到A. |
| 2).双向: | A可以通过属性导航到B,B也可以通过属性导航到A. |
判断方法:
1,判断都是从对象的实例上面来看的;
2,判断关系必须确定一对属性;
3,判断关系必须确定具体需求;
5.3.聚合关系:
表示整体和部分的关系,整体和部分之间可以相互独立存在,一定是有两个模块来分别管理整体和部分.
整体和部分可以分开.
5.4.组合关系:
强聚合关系,但是整体和部分不能独立存在,一定是在一个模块中同时管理整体和部分,生命周期必须相同.
单据和单据明显/购物车
5.5.泛化关系
:其实就是继承关系.