来源:ACL2017
Joint extraction of entities and relations :监测实体和他们之间的关系,同时的,from unstructured text。
Open IE:relation words 从给定的句子中提取,relation words are extracted from a predefined relation set which may not appear in the given sentence.
过去的方法:pipelined manner,例如先提取实体,然后识别他们的关系。简单,灵活,但是忽视了两个任务之间的关系,每个任务都是独立的。 实体识别的结果会影响关系分类并导致错误。
joint learning framework:可以有效的集成实体和关系的信息。大多数现有的joint method are feature-based structured system。他们需要复杂的特征,依赖其他NLP toolkits,可能导致错误的propagation。
Miwa and Bansal, 2016提出一种端到端的实体和关系的提取,尽管实体和关系共享参数,它还是可以分别提取实体和关系。
本文提出:tagging schema 结合端对端的模型,转换成tagging problem。有监督学习方法。自己标注会很耗费精力和有错误,本文使用公开的数据集。
本文主要的contribution:(1)tagging scheme(2)tagging-based methods are better than most of the existing pipelined and joint learning methods(3)Furthermore,we also develop an end-to-end model with biased loss function to suit for the novel tags。It can enhance the association between related entities
Method:
本文提出一种tagging机制的端对端的模型,该模型有有偏的目标函数,联合提取实体和它们之间的关系。
如果一个句子中包含多个相同的关系类型,以就近原则结合两个实体。
BIES(Begin, Inside, End, Single):实体中的位置信息
An extracted result is represented by a triplet:(Entity1, RelationType, Entity2).
End-to-end Model:

包含一个Bi-LSTM层用来encode输入句子,和一个LSTM的decoding层,该层包含biased loss。Biased loss可以enhance实体tag之间的关系。
The Bi-LSTM encoding layer: 包含一个前向lstm层,一个后向lstm层和一个连接层(concatenate layer)。 word embedding层将词从1-hot representation转换成embedding vector。因此,一系列的词可以表示成:W = {w1, ... wt, wt+1, ... , wn}。 wt是一个d维词向量,word vector,代表句长为n的第t个词向量。
在word embedding layer之后,有两个平行的LSTM层:前向LSTM和后向LSTM
BiLSTM:

前向LSTM层encode w1到wt上下文的信息,后向LSTM层encode wn到wt的上下文信息。最后的encoding信息是:
LSTM decoding层:
作为生成tag序列,decoding层的输入是,从Bi-LSTM获取的ht,之前预测的tag embedding,Tt-1,之前的单元值c(t-1),和decoding层之前的h(t-1) 。
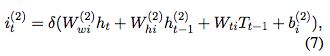
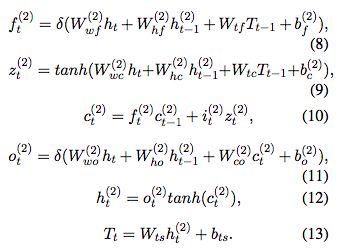
最终的softmax层可以计算归一化的实体tag概率,基于tag预测向量Tt:
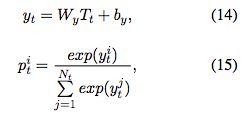
Bias Objective Function:
最大化数据的对数似然,优化方法是用RM-Sprop,由Hinton提出的,目标函数:

该函数中 |D|是整个训练集的大小,Lj是句子xj的长度,yt(j)是句子xj中t位置的label。pt(j)是公式15定义的归一化的tag的概率。除此之外,I(O)是区别tag"O"和关系tag之间的loss的
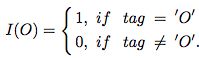
a是一个有偏的权重,a越大,关系tag对模型的影响越大。
Evaluation:
Precision, Recall,F1。与经典方法不同的是,我们的方法可以在不知道实体类型的情况下提取三元组,也就是说我们不需要使用实体类型,所以在evaluation时也不需要考虑实体类型。如果关系类型和两个实体都是正确的,这个三元组才正确 ???