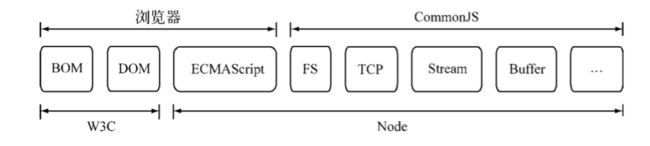
早在Netscape诞生不久后,JavaScript就一直在探索本地编程的路,Rhino是其代表产物。无奈那时服务端JavaScript走的路均是参考众多服务器端语言来实现的,在这样的背景之下,一没有特色,二没有实用价值。但是随着JavaScript在前端的应用越来越广泛,以及服务端JavaScript的推动,JavaScript现有的规范十分薄弱,不利于JavaScript大规模的应用。那些以JavaScript为宿主语言的环境中,只有本身的基础原生对象和类型,更多的对象和API都取决于宿主的提供,所以,我们可以看到JavaScript缺少这些功能:
JavaScript没有模块系统。没有原生的支持密闭作用域或依赖管理。
JavaScript没有标准库。除了一些核心库外,没有文件系统的API,没有IO流API等。
JavaScript没有标准接口。没有如Web Server或者数据库的统一接口。
JavaScript没有包管理系统。不能自动加载和安装依赖。
于是便有了CommonJS(http://www.commonjs.org)规范的出现,其目标是为了构建JavaScript在包括Web服务器,桌面,命令行工具,及浏览器方面的生态系统。
CommonJS制定了解决这些问题的一些规范,而Node.js就是这些规范的一种实现。Node.js自身实现了require方法作为其引入模块的方法,同时NPM也基于CommonJS定义的包规范,实现了依赖管理和模块自动安装等功能。
一,CommonJS的模块规范
Node借鉴CommonJS的Modules规范实现了一套模块系统,所以先来看看CommonJS的模块规范。
CommonJS对模块的定义十分简单,主要分为模块引用、模块定义和模块标识3个部分。
1. 模块引用
模块引用的示例代码如下:
var math = require('math');
在CommonJS规范中,存在require()方法,这个方法接受模块标识,以此引入一个模块的API到当前上下文中。
2. 模块定义
在模块中,上下文提供require()方法来引入外部模块。对应引入的功能,上下文提供了exports对象用于导出当前模块的方法或者变量,并且它是唯一导出的出口。在模块中,还存在一个module对象,它代表模块自身,而exports是module的属性。在Node中,一个文件就是一个模块,将方法挂载在exports对象上作为属性即可定义导出的方式:
// math.js
exports.add = function () {
var sum = 0, i = 0, args = arguments, l = args.length;
while (i < l) { sum += args[i++]; }
return sum;
};
在另一个文件中,我们通过require()方法引入模块后,就能调用定义的属性或方法了:
// program.js
var math = require('math');
exports.increment = function (val) { return math.add(val, 1);};
3.模块标识
模块标识其实就是传递给require()方法的参数,它必须是符合小驼峰命名的字符串,或者以.、..开头的相对路径,或者绝对路径。它可以没有文件名后缀.js。模块的定义十分简单,接口也十分简洁。它的意义在于将类聚的方法和变量等限定在私有的作用域中,同时支持引入和导出功能以顺畅地连接上下游依赖。每个模块具有独立的空间,它们互不干扰,在引用时也显得干净利落。
二,Node的模块实现

Node在实现中并非完全按照规范实现,而是对模块规范进行了一定的取舍,同时也增加了少许自身需要的特性。尽管规范中exports、require和module听起来十分简单,但是Node在实现它们的过程中究竟经历了什么,这个过程需要知晓。
在Node中引入模块,需要经历如下3个步骤。
1. 路径分析
2. 文件定位
3. 编译执行
在Node中,模块分为两类:一类是Node提供的模块,称为核心模块;另一类是用户编写的模块,称为文件模块。
• 核心模块部分在Node源代码的编译过程中,编译进了二进制执行文件。在Node进程启动时,部分核心模块就被直接加载进内存中,所以这部分核心模块引入时,文件定位和编译执行这两个步骤可以省略掉,并且在路径分析中优先判断,所以它的加载速度是最快的。
• 文件模块则是在运行时动态加载,需要完整的路径分析、文件定位、编译执行过程,速度比核心模块慢。
1.优先从缓存加载
与前端浏览器会缓存静态脚本文件以提高性能一样,Node对引入过的模块都会进行缓存,以减少二次引入时的开销。不同的地方在于,浏览器仅仅缓存文件,而Node缓存的是编译和执行之后的对象。不论是核心模块还是文件模块,require()方法对相同模块的二次加载都一律采用缓存优先的方式,这是第一优先级的。不同之处在于核心模块的缓存检查先于文件模块的缓存检查。
模块加载的优先级是:缓存模块 > 核心模块 > 用户自定义模块。
2.路径分析和文件定位
因为标识符有几种形式,对于不同的标识符,模块的查找和定位有不同程度上的差异。
a.模块标识符分析
Node基于一个模块标识符进行模块查找。模块标识符在Node中主要分为以下几类。
核心模块,如http、fs、path等。
.或..开始的相对路径文件模块。
以/开始的绝对路径文件模块。
非路径形式的文件模块,如自定义的connect模块
• 核心模块
核心模块的优先级仅次于缓存加载,它在Node的源代码编译过程中已经编译为二进制代码,其加载过程最快。如果试图加载一个与核心模块标识符相同的自定义模块,那是不会成功的。如果自己编写了一个http用户模块,想要加载成功,必须选择一个不同的标识符或者换用路径的方式。
• 路径形式的文件模块
以.、..和/开始的标识符,这里都被当做文件模块来处理。在分析路径模块时,require()方法会将路径转为真实路径,并以真实路径作为索引,将编译执行后的结果存放到缓存中,以使二次加载时更快。由于文件模块给Node指明了确切的文件位置,所以在查找过程中可以节约大量时间,其加载速度慢于核心模块。
• 自定义模块
自定义模块指的是非核心模块,也不是路径形式的标识符。它是一种特殊的文件模块,可能是一个文件或者包的形式。这类模块的查找是最费时的,也是所有方式中最慢的一种。
b.文件定位
从缓存加载的优化策略使得二次引入时不需要路径分析、文件定位和编译执行的过程,大大提高了再次加载模块时的效率。但在文件的定位过程中,还有一些细节需要注意,这主要包括文件扩展名的分析、目录和包的处理。
• 文件扩展名分析
CommonJS模块规范也允许在标识符中不包含文件扩展名,这种情况下,Node会按.js、.json、.node的次序补足扩展名,依次尝试。在尝试的过程中,需要调用fs模块同步阻塞式地判断文件是否存在。因为Node是单线程的,所以这里是一个会引起性能问题的地方。小诀窍是:如果是.node和.json文件,在传递给require()的标识符中带上扩展名,会加快一点速度。
require加载无文件类型的优先级:.js > .json > .node
• 目录分析和包
在分析标识符的过程中,require()通过分析文件扩展名之后,可能没有查找到对应文件,但却得到一个目录,此时Node会将目录当做一个包来处理。
在这个过程中,Node对CommonJS包规范进行了一定程度的支持。首先,Node在当前目录下查找package.json(CommonJS包规范定义的包描述文件),通过JSON.parse()解析出包描述对象,从中取出main属性指定的文件名进行定位。如果文件名缺少扩展名,将会进入扩展名分析的步骤。而如果main属性指定的文件名错误,或者压根没有package.json文件,Node会将index当做默认文件名,然后依次查找index.js、index.node、index.json。
如果在目录分析的过程中没有定位成功任何文件,则自定义模块进入下一个模块路径进行查找。如果模块路径数组都被遍历完毕,依然没有查找到目标文件,则会抛出查找失败的异常。
c.模块编译
在Node中,每个文件模块都是一个对象,它的定义如下:
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
if (parent && parent.children) {
parent.children.push(this);
}
this.filename = null;
this.loaded = false;
this.children = [];
编译和执行是引入文件模块的最后一个阶段。定位到具体的文件后,Node会新建一个模块对象,然后根据路径载入并编译。对于不同的文件扩展名,其载入方法也有所不同,具体如下所示。
• .js文件。
通过fs模块同步读取文件后编译执行。
• .node文件。
这是用C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件。
• .json文件。
通过fs模块同步读取文件后,用JSON.parse()解析返回结果。
• 其余扩展名文件。
它们都被当做.js文件载入。
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能。
JavaScript模块的编译
回到CommonJS模块规范,我们知道每个模块文件中存在着require、exports、module这3个变量,但是它们在模块文件中并没有定义,那么从何而来呢?甚至在Node的API文档中,我们知道每个模块中还有__filename、__dirname这两个变量的存在,它们又是从何而来的呢?如果我们把直接定义模块的过程放诸在浏览器端,会存在污染全局变量的情况。
事实上,在编译的过程中,Node对获取的JavaScript文件内容进行了头尾包装。在头部添加了(function (exports, require, module, __filename, __dirname) {\n,在尾部添加了\n});。一个正常的JavaScript文件会被包装成如下的样子:
(function (exports, require, module, __filename, __dirname) {
var math = require('math');
exports.area = function (radius) {
return Math.PI * radius * radius;
};
});
这样每个模块文件之间都进行了作用域隔离。包装之后的代码会通过vm原生模块的runInThisContext()方法执行(类似eval,只是具有明确上下文,不污染全局),返回一个具体的function对象。最后,将当前模块对象的exports属性、require()方法、module(模块对象自身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个function()执行。
三,包和NPM
在模块之外,包和NPM则是将模块联系起来的一种机制。
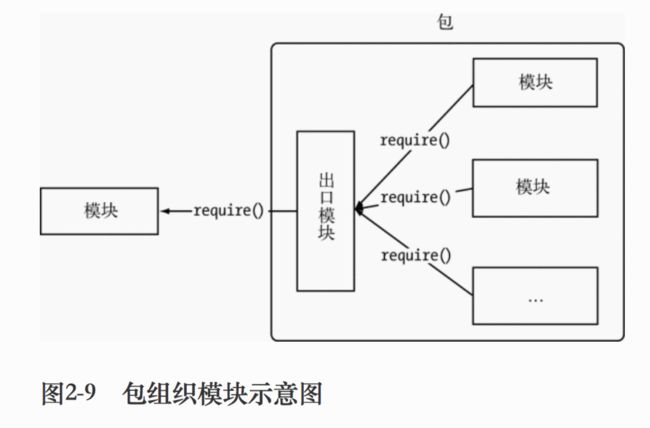
CommonJS的包规范的定义其实也十分简单,它由包结构和包描述文件两个部分组成,前者用于组织包中的各种文件,后者则用于描述包的相关信息,以供外部读取分析。
包结构
包实际上是一个存档文件,即一个目录直接打包为.zip或tar.gz格式的文件,安装后解压还原为目录。完全符合CommonJS规范的包目录应该包含如下这些文件。
package.json:包描述文件。
bin:用于存放可执行二进制文件的目录。
lib:用于存放JavaScript代码的目录。
doc:用于存放文档的目录。
test:用于存放单元测试用例的代码。
包描述文件
包描述文件用于表达非代码相关的信息,它是一个JSON格式的文件——package.json,位于包的根目录下,是包的重要组成部分。而NPM的所有行为都与包描述文件的字段息息相关。
这个可以看看NPM官网对package.json的定义规范。
可以通过npm adduser, npm publish把自己的package上传到npm仓库。
本文内容源自https://blog.csdn.net/u012422829/article/details/52760981,https://blog.csdn.net/qbian/article/details/79367500