- 前言
之前在做大众点评网数据的时候,发现数据在前端显示是用标签来替换。这样爬虫采集到的就是一堆标签加一点内容所混杂的脏数据,同时发现标签中的值也是随时改变的。所以这次也是花了一点时间来整理关于大众点评JS加密的内容,给大家简单讲解一下,以此来学习借鉴如何有效安全的防范爬虫。仅供学习参考,切勿用于商业用途
一、介绍
首先随便打开大众点评网一家店,看到数据都是正常状态如图1-1,然后我们用开发者工具定位到元素上会发现如图1-2所示:

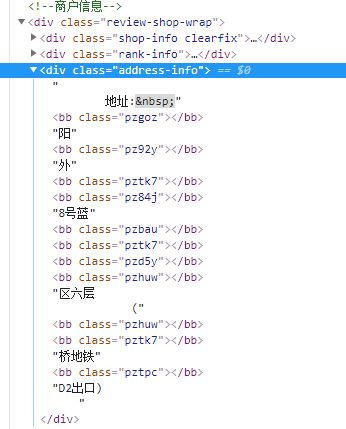
我们可以看到数据都是用


店面基础信息用
二、页面分析
我们随便查看一个被替换了的标签元素,发现它对应了一个文件如图2-1所示:

可以看到标签一些基本信息,长度高度还有和它相关的一个链接,打开这个链接,我们可以发现是一个乱序的中文数据表格。如图2-2所示:

基本上我们就可以推测出来,数据被隐藏替换的大概原理,通过标签来对应表格文字,其中class的值我们可以理解为被替换数据内容的key,标签类型就好比对应的数据表,这里有三种类别标签就是对应三张不同的数据表,这样我们还需要解决的问题是:
- (1)不同种类的标签如何对应不同的表;
-
(2)如何通过标签的class值去对应被替换的数据。
所以到这一步,我们还少一些关键的线索,我们继续看到之前页面,发现图表链接包含在一个css表中 如图2-3所示:
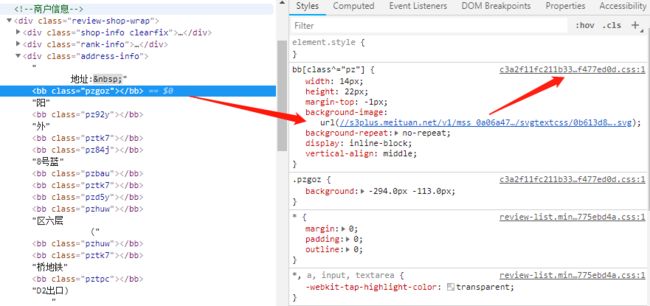 图2-3 隐藏的css文件
图2-3 隐藏的css文件
可以看到有一个css文件,我们在元素中搜索这个表 如图2-4
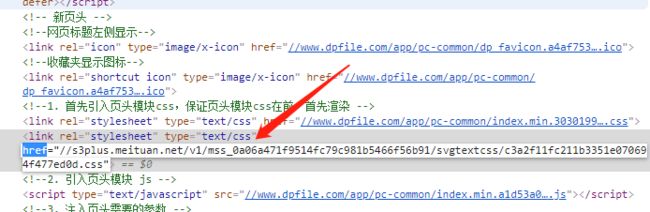 图2-4 css文件所在位置
图2-4 css文件所在位置
这样我们便可以从网页中找到指定的文件链接,关于如何根据key值找到对应的参照表。我们打开此链接如图2-5、2-6所示:
 图2-5 key值对照表
图2-5 key值对照表
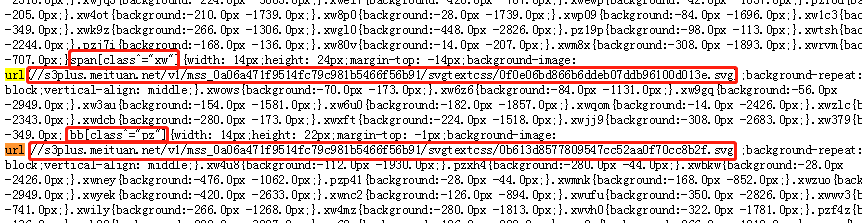
我们可以从图2-5、图2-6看到cc标签、span标签、bb标签每个下面都有一个url。我们打开可以发现就是之前那种格式的对应表,我们稍后再看。我们先看到我们的key值(标签class属性对应的值),后面都接着一个坐标,格式统一都是.(标签class值){background: (横坐标)px(纵坐标) px;这样我们就已经获得key值所对应的坐标,到这里我们基本可以确定,我们找到key值和所对应的坐标就可以根据标签相对应的表,利用坐标就可以找到利用标签所替换的数据。
三、JS解密
接下来,我们就需要知道如何利用获取到的坐标来获取正确被替换的数据。我们首先根据那张表格依次打开链接,查看它们元素会发现有两种格式,一种格式有元素defs标签,另一种没有。如图3-1、图3-2、图3-3所示:
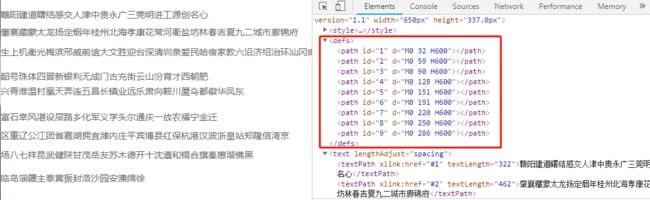

总共三张表对应三个不同标签,分两种格式,我分成有defs标签和无defs标签两类。注意,这里我并没有根据标签种类去划分表类别,因为每一次获取到的格式都是随机的。也就是说今天span标签是对应有defs标签数据表,可能明天就对应不含有defs标签类的数据表。数据表格式是随机变化的。
(1)含有defs标签类别数据表解密
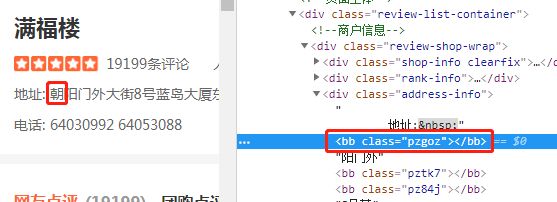
以地址中的bb标签为例,看地址所对应的标签值为pzgoz,如图3-4所示:,以及bb标签所对应的svg数据表,如图3-6所示:
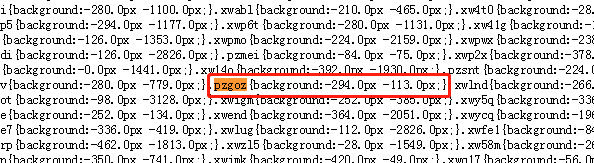
根据css表找到它的对应坐标x=-294,y=-113.0,如图3-5所示:
最后根据标签类别找到对应svg数据表链接,打开链接,如图3-6所示:
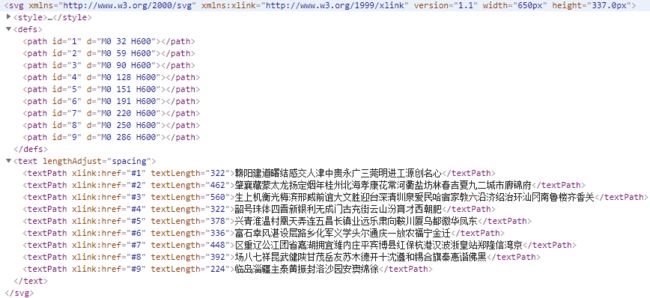
将坐标转为正,先从y坐标看到defs标签d属性上,y=113应该排序在d=M0 90 H600与d=M0 128 H600之间,所以id应该为4,再看textPath标签xlink:href属性为#4的就是我们所要找的行,如果之前有注意看标签width的话,就知道每一个字长为14px,x=294去除以14,等于21,这一行做list的话,list[21]应该就是朝字。代码如下:
hight = html.xpath('//defs//path/@d')
hight = [i.replace('M0','').replace('H600','').strip() for i in hight]
hight.append(y)
hight = sorted(hight, key=lambda i: int(i))
y = hight.index(y)
#若纵坐标与标签y相等相等时,取同行的高度
if y != len(hight) - 1 and hight[y] == hight[y + 1]:
y = y + 1
content = html.xpath('//textpath/text()')[y]
content = ''.join(content).strip()
x = int(int(x) / 14)
return content[x]
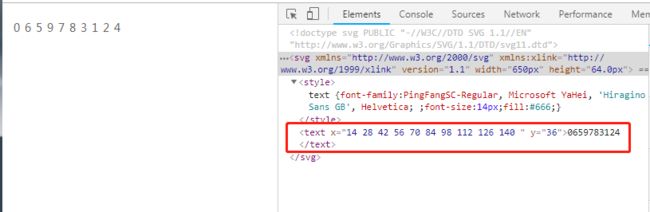
(2)不含有defs标签类别数据表解密
之前步骤一样,直接跳到找到对应的svg数据表,如图3-7所示:

比如数字3,x=-232.0px y=-140.0px,先全部取正数,y=140 对应在标签text属性y=118和y=163之间,同样排序在第四位,所以取第四行为list,同样232/14=16,list[16]=3;同时也可以数标签text属性x中232排在224-238之间,也就是16-17位之间,但要取16为下标。代码如下:
hight = html.xpath('//text/@y')
hight.append(y)
hight = sorted(hight, key=lambda i: int(i))
y = hight.index(y)
# 若纵坐标与标签y相等相等时,取同行的高度
if y != len(hight) - 1 and hight[y] == hight[y + 1]:
y = y + 1
content = html.xpath('//text/text()')[y]
content = ''.join(content).strip()
x = int(int(x) / 14)
return content[x]
四、代码实现
这里附上我测试的代码,仅供学习参考,切勿用于商业用途。直接使用前,请带上自己浏览器的请求头参数。
#coding=utf-8
import requests
import lxml.html
import re
from decimal import Decimal
#获取svg表格中被替换的数据
def get_hide_char(x,y,type,url):
response = requests_middler(url)
html = lxml.html.fromstring(response.content)
#网页格式是否有defs元素
if len(html.xpath('//defs//path/@d'))<1:#如果没有defs标签
hight = html.xpath('//text/@y')
hight.append(y)
hight = sorted(hight, key=lambda i: int(i))
y = hight.index(y)
# 若纵坐标与标签y相等相等时,取同行的高度
if y != len(hight) - 1 and hight[y] == hight[y + 1]:
y = y + 1
content = html.xpath('//text/text()')[y]
content = ''.join(content).strip()
x = int(int(x) / 14)
return content[x]
else:#如果含有defs标签
hight = html.xpath('//defs//path/@d')
hight = [i.replace('M0','').replace('H600','').strip() for i in hight]
hight.append(y)
hight = sorted(hight, key=lambda i: int(i))
y = hight.index(y)
#若hight相等时,取同行的高度
if y != len(hight) - 1 and hight[y] == hight[y + 1]:
y = y + 1
content = html.xpath('//textpath/text()')[y]
content = ''.join(content).strip()
x = int(int(x) / 14)
return content[x]
#请求url统一方式
def requests_middler(url):
headers={'User-Agent':''}#加入自己的User-Agent
html = requests.get(url, headers=headers)
return html
#获取css表中key值对应的坐标,以及标签对应svg表链接
def get_position_xy(html,password,type,url):
#获取key值对应的坐标
rule = re.compile(password + '{background:-(.*?).0px -(.*?).0px;')
result = re.findall(rule, html)[0]
x = result[0]
y = result[1]
#获取标签所对应的svg表格
rule = re.compile(type + '\[class\^="\w+"\]\{(.*?)}', re.S)
result = re.findall(rule,html)[0]
rule = re.compile('url\((.*?)\)')
href = re.findall(rule, result)
url = 'http:' + href[0]
hide_char=get_hide_char(x,y,type,url)
return hide_char
#解密前数据做好清洗,清洗成标签与文字组成的list,保证还原字符串顺序
def get_hide_string(s,url):
result=[]
a_list = re.split('',s)
# print(a_list)
b=[]
for i in a_list:
try:
dex = i.index('<')
except ValueError:
b.append(i)
continue
if dex!=0:
b.append(i[:dex])
rule = re.compile('<(.*?) class="(.*?)"')
tag = re.findall(rule,i[dex:])[0]
b.append(tag)
try:
b.remove('')
except ValueError:
pass
print(b)#b为已清洗好的list,接下来分别还原标签替换数据
html = requests_middler(url)
html = html.text
for tag in b:
#遇到类别标签则分类进行筛选
if tag[0]=='span'or tag[0]== 'cc' or tag[0]=='bb':
hide_char=get_position_xy(html,tag[1],tag[0],url)
result.append(hide_char)
#防止被其它标签干扰
elif tag[0]==''or tag[0]=='p'or tag[0]=='div':
continue
#遇到中文及不含标签则直接加入list
else:
result.append(tag)
return ''.join(result).strip('\n').strip()
if __name__=='__main__':
url ='https://www.dianping.com/shop/507576/review_all'
cookies={}#自己加入当时访问的cookies
headers = {'User-Agent': ''}#加入自己的User-Agent
response=requests.get(url,headers=headers,cookies=cookies)
html = lxml.html.fromstring(response.content)
#找到标签数据,必须要保留标签,这里以商店地址为例
rule = re.compile('(.*?)', re.S)
address=re.findall(rule,response.text)[0]
address = address.strip().replace('\n','').replace(' ','')
#找到css表,css表链接存放位置固定,所以直接获取
css = html.xpath('//link[@rel="stylesheet"]/@href')[1]
url ='http:'+css.strip()
result = get_hide_string(address,url)
result=result.replace(' ','')
print('解密前数据:'+address)
print('解密后数据:'+result)
代码运行结果 如图4-1所示:

六、总结
总结一下,就是先找到被替换数据标签,发现替换时对应的css表,找到css表,根据标签属性class值作key值去找到对应的坐标,同时找到标签类别所对应的svg数据表链接,最后参照数据表坐标得到被隐藏的数据。
大众点评前端JS加密方法与平时遇到的都不太一样,所以花了一些时间来讲,之后遇到不一样的JS加密也会给大家一起学习探讨,同样如果发现文章的不足,欢迎指出。
注意:由于大众点评数据表和替换内容一直在变化,所以你们看到的内容将可能与我写的不一样,但是原理和方法还是一样。
如果您喜欢我的文章,请关注或点击喜欢,您的支持是我最大的动力 ^ ^~!
仅供学习参考,切勿用于商业用途
转载请注明作者及其出处
黑羊的皇冠 主页