并发安全的 ConcurrentHashMap 实现原理详解
哈希表是中非常高效,复杂度为O(1)的数据结构,在Java开发中,我们最常见到最频繁使用的就是HashMap和HashTable,但是在线程竞争激烈的并发场景中使用都不够合理。
HashMap :先说HashMap,HashMap是线程不安全的,在并发环境下,可能会形成环状链表(扩容时可能造成,具体原因自行百度google或查看源码分析),导致get操作时,cpu空转,所以,在并发环境中使用HashMap是非常危险的。
HashTable : HashTable和HashMap的实现原理几乎一样,差别无非是1.HashTable不允许key和value为null;2.HashTable是线程安全的。但是HashTable线程安全的策略实现代价却太大了,简单粗暴,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,相当于将所有的操作串行化,在竞争激烈的并发场景中性能就会非常差。
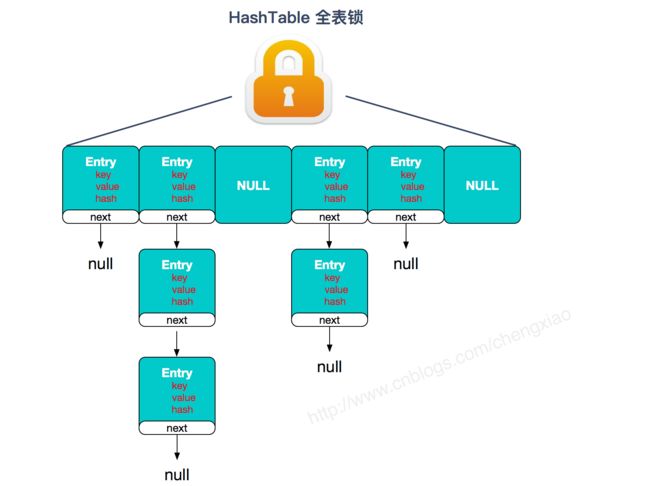
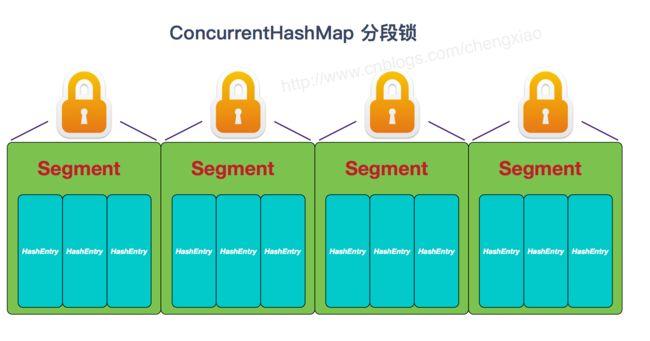
HashTable性能差主要是由于所有操作需要竞争同一把锁,而如果容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这样便可以有效地提高并发效率。这就是ConcurrentHashMap所采用的"分段锁"思想。
ConcurrentHashMap源码分析
ConcurrentHashMap采用了非常精妙的"分段锁"策略,ConcurrentHashMap的主干是个Segment数组。
final Segment[] segments;
Segment继承了ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在ConcurrentHashMap,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。(就按默认的ConcurrentLeve为16来讲,理论上就允许16个线程并发执行,有木有很酷)
所以,对于同一个Segment的操作才需考虑线程同步,不同的Segment则无需考虑。
Segment类似于HashMap,一个Segment维护着一个HashEntry数组
transient volatile HashEntry
HashEntry是目前我们提到的最小的逻辑处理单元了。一个ConcurrentHashMap维护一个Segment数组,一个Segment维护一个HashEntry数组。
不变(Immutable)和易变(Volatile)
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。如果使用传统的技术,如HashMap中的实现,如果允许可以在hash链的中间添加或删除元素,读操作不加锁将得到不一致的数据。ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的。HashEntry代表每个hash链中的一个节点,其结构如下所示:
static final class HashEntry {
final K key;
final int hash;
volatile V value;
final HashEntry next;
}
可以看到除了value不是final的,其它值都是final的,这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next 引用值,所有的节点的修改只能从头部开始。
对于put操作,可以一律添加到Hash链的头部。但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点。这在讲解删除操作时还会详述。为了确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁。
定位段
为了加快定位段以及段中hash槽的速度,每个段hash槽的的个数都是2^n,这使得通过位运算就可以定位段和段中hash槽的位置。当并发级别为默认值16时,也就是段的个数,hash值的高4位决定分配在哪个段中。
但是我们也不要忘记《算法导论》给我们的教训:hash槽的的个数不应该是 2^n,这可能导致hash槽分配不均,这需要对hash值重新再hash一次。