关于预测的两类核心算法
- 函数逼近/预测分析问题(分类问题、回归问题)
解决方法:惩罚线性回归、集成方法
当数据含有大量的特征,但是没有足够多的数据或时间来训练更复杂的集成方法模型时,惩罚回归方法将优于其他算法。
而且这些算法使用十分简单,可调参数不多,都有定义良好、结构良好的输入数据类 型。当面临一个新问题的时候,在 1 ~ 2 小时内完成输 入数据的处理、训练模型、输出预测结果是司空见惯的。
这些算法的一个最重要特性就是可以明确地指出哪个输入变量(特征)对预测结果最重要。这已经成为机器学习算法一个无比重要的特性。在预测模型构建过程中,最消耗时间的一步就是特征提取(feature selection)或者叫作特征工程(feature engineering)。就是 数据科学家选择哪些变量用于预测结果的过程。根据对预测结果的贡献程度对特征打分。
惩罚线性回归
产生原因
*最小二乘法:过拟合问题
自由度
确定一条直线需要2个独立的参数(如x轴交点坐标,斜率)
数据条数》自由度
惩罚线性回归可以减少自由度使之与数据规模、问题的复杂度相匹配。对于具有大量自由度的问题,惩罚线性回归方法获得了广泛的应用。在下列问题中更是得到了偏爱,基因问题,通常其自由度(也就是基因的数目)是数以万计的;文本分类问题,其自由度可 以超过百万。
集成方法(ensemble methods)
集成方法的基本思想是构 建多个不同的预测模型,然后将其输出做某种组合作为最终的输出,如取平均值或采用多 数人的意见(投票)。单个预测模型叫作基学习器(base learners)。计算学习理论(computation learning theory)的研究结果证明只要基学习器比随机猜测稍微好些(如果独立预测模型 的数目足够多),那么集成方法就可以达到相当好的效果。
产生原因:
某些机器学习算法输出结果不稳定,这一问题导致了集成方法的提出。例如,在现有数据集基础上增加新的数据会导致最终的预测模型或性能突变。二元决策树 和传统的神经网络就有这种不稳定性。这种不稳 定性会导致预测模型性能的高方差,取多个模型 的平均值可以看作是一种减少方差的方法。技巧 在于如何产生大量的独立预测模型,特别是当它们都采用同样的基学习器时
一个有用的技巧就是在开发的早期阶段,如特征工程阶段,利用惩罚线性模型进行训练。这给数据科学家提供一个基本的判断:哪些变量(特征)是有用的、重要的,同时提供了一个后续与其他算法性能比较上的基线。
数据科学家的任务就是如何平衡问题的复杂度、预测模型的复杂度和数据集规模,以获得一个最佳的可部署模型。基本思想是如果问题不是很复杂,而且不能获得足够多的数据,则线性方法比更加复杂的集成方法可能会获得全面更优的性能。基因组数据就是此类问题的典型代表
数据集规模通常需要是自由度的倍数关系。因为数据集的规模是固定的,所以需要调整模型的自由度。惩罚线性回归的相关章节将介绍惩罚线性回归如何支持这种调整以及依此如何达到最优的性能
疑点
第 3 章将更详细地讨论为什么一个算法或者另一个算法是一个问题的更好选择。这与问题的复杂度、算法内在固有的自由度有关。线性模型倾向于训练速度快,并且经常能够提供与非线性集成方法相当的性能,特别是当能获取的数据受限时。因为它们训练时间短,
在早期特征选取阶段训练线性模型是很方便的,然后可以据此大致估计针对特定问题可以达到的性能。线性模型可以提供关于特征对预测的相关信息,可以辅助特征选取阶段的工作。在有充足数据的情况下,集成方法通常能提供更好的性能,也可以提供相对间接的关
于结果的贡献的评估。
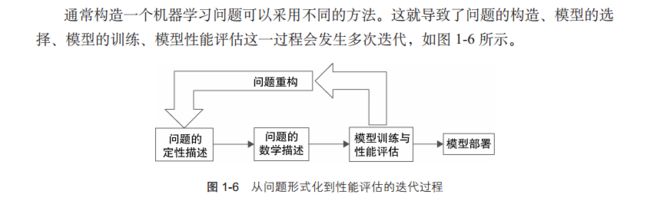
使用机器学习需要几项不同的技能。
1 一项就是编程技能,
2 获得合适的模型进行训练和部署
步骤:
对问题用数学语言进行重叙,
需要浏览可获得的数据,确定哪类数据可能用于预测。“浏览”的意思是对数据进行各种统计意义上的检测分析
假设通过某种方法,选择了一组特征,开始训练机器学习算法。这将产生一个训练好的模型,然后是估计它的性能。下一步,可能会考虑对特征集进行调整,包括增加新的特征,删除已证明没什么帮助的特征,或者选择另外一种类型的训练目标(也叫作目标函数),通过上述调整看看能否提高性能。可以反复调整设计决策来提高性能。可能会把导致性能比较差的数据单独提出来,然后尝试是否可以从中发现背后的规律。这可以导致添加新的特征到预测模型中,也可以把数据集分成不同的部分分别考虑,分别建立不同的预测模型。
当重述问题、提取特征、训练算法、评估算法时,需要熟悉不同算法所要求的输入数据结构。
此过程通常包括如下步骤。
(1)提取或组合预测所需的特征。
(2)设定训练目标。
(3)训练模型。
(4)评估模型在测试数据上的性能表现
特征工程就是对特征进行整理组合,以达到更富有信息量的过程。建立一个证劵交易系统包括特征提取和特征工程。特征提取将决定哪些特征可以用来预测价格。过往的价格、相关证劵的价格、利率、从最近发布的新闻提取的特征都是现有公开讨论的各种交
易系统的输入数据。而且证劵的价格还有一系列的工程化特征,包括:指数平滑异同移动平均线(moving average convergence and divergence, MACD)、相对强弱指数(relative strength index, RSI)等。这些特征都是过往价格的函数,它们的发明者都认为这些特征对于证劵交易是非常有用的。
模型的训练也是一个过程,每次开始都是先选择作为基线的特征集合。作为一个现代机器学习算法(如本书描述的算法),通常训练 100 ~ 5000 个不同的模型,然后从中精选出一个模型进行部署。产生如此之多的模型的原因是提供不同复杂度的模型,这样可以挑选出一个与问题、数据集最匹配的模型。如果不想模型太简单又不想放弃性能,不想模型太复杂又不想出现过拟合问题,那么需要从不同复杂度的模型中选择一个最合适的。
通过理解数据来了解问题
构建预测模型的过程叫作训练。具体的方法依赖于算法,基本上采用迭代的方式。算法假定属性和标签之间存在可预测的关系,观察出错的情况,做出修正,然后重复此过程直到获得一个相对满意的模型
属性和标签的不同类型决定模型的选择
很多机器学习算法只能处理数值变量,不能处理类别变量或因素变
量(factor variable)。例如,惩罚回归算法只能处理数值变量, SVM、核方法、 K 最近邻也是同样。第 4 章将介绍将类别变量转换为数值变量的方法。这些变量的特性将会影响算法的选择以及开发一个预测模型的努力的方向,因此这也是当面临一个新问题时,需要考
虑的因素之一。
当标签是数值的,就叫作回归问题。当标签是类别的,就叫作分类问题。如果分类结果只取 2 个值,就叫作二元分类问题。如果取多个值,就是多类别分类问题
很多情况下,问题的类型是由设计者选择的。刚刚的例子就是如何把一个回归问题转换为二元分类问题,只需要对标签做简单的变换。这实际上是面临一个问题时所做的一种权衡。例如,分类目标可以更好地支持 2 种行为选择的决策问题。
分类问题也可能比回归问题简单。例如考虑 2 个地形图的复杂度差异,一个地形图只有一个等高线(如 30.5 米的等高线),而另一个地形图每隔 3.05 米就有一个等高线。只有一个等高线的地形图将地图分成高于 30.5 米的区域和低于 30.5 米的区域,因此相比另一个地形图含有更少的信息。一个分类器就相当于只算出一个等高线,而不再考虑与这条分界线的远近距离之类的问题,而回归的方法就相当于要绘制一个完整的地形图
新数据集的注意事项
- 数据规模(行数、列数)
- 类别变量的数目、类别的取值范围
- 缺失的值(缺失的行数+具体缺失的项数)
- 属性和标签的统计特性以及关系 (模糊:平行坐标图 具体:相关性)
数据集属性的可视化
平行坐标图
基于标签对折线标示不同的颜色,更有利于观测到属性值与标签之间的关系。这些观察将有助于解释和确认某些预测的结果。
属性和标签的关系可视化
属性与标签的交会图(cross-plots)
两个属性(或一个属性、一个标签)的相关程度可以由皮尔逊相关系数
用热图(heat map)展示属性和标签的相关性
多个属性间的相关性很高(相关系数 >0.7),即多重共线性(multicollinearity),往往会导致预测结果不稳定。
如果属性和标签相关,则通常意味着两者之间具有可预测的关系
*分类问题*
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plot
target_url = ("https://archive.ics.uci.edu/ml/machine-learning-"
"databases/undocumented/connectionist-bench/sonar/sonar.all-data")
#read rocks versus mines data into pandas data frame
rocksVMines = pd.read_csv(target_url,header=None, prefix="V")
for i in range(208):
#assign color based on color based on "M" or "R" labels
if rocksVMines.iat[i,60] == "M":
pcolor = "red"
else:
pcolor = "blue"
#plot rows of data as if they were series data
dataRow = rocksVMines.iloc[i,0:60]
dataRow.plot(color=pcolor, alpha=0.5)
plot.xlabel("Attribute Index")
plot.ylabel(("Attribute Values"))
plot.show()
*回归问题的平行坐标图*
#数值标签映射
回归问题,应该用不同的颜色来对应标签值的高低。也就是实现由标签的实数值到颜
色值的映射,需要将标签的实数值压缩到 [0.0,1.0] 区间
from math import exp
target_url = ("http://archive.ics.uci.edu/ml/machine-"
"learning-databases/abalone/abalone.data")
#read abalone data
abalone = pd.read_csv(target_url,header=None, prefix="V")
abalone.columns = ['Sex', 'Length', 'Diameter', 'Height',
'Whole Wt', 'Shucked Wt',
'Viscera Wt', 'Shell Wt', 'Rings']
summary = abalone.describe()
minRings = summary.iloc[3,7]
maxRings = summary.iloc[7,7]
nrows = len(abalone.index)
for i in range(nrows):
#plot rows of data as if they were series data
dataRow = abalone.iloc[i,1:8]
labelColor = (abalone.iloc[i,8] - minRings) / (maxRings - minRings)
dataRow.plot(color=plot.cm.RdYlBu(labelColor), alpha=0.5)
plot.xlabel("Attribute Index")
plot.ylabel(("Attribute Values"))
plot.show()
改变颜色映射关系可以从不同的层面来可视化属性与目标之间的关系
1 归一化
2 对数转换
针对岩石 vs. 水雷问题,平行坐标图的线用 2 种颜色代表了 2 种目标类别。在回归问题(红酒口感评分、鲍鱼预测年龄),标签(目标类别)取实数值,平行坐标图的线取一系列不同的颜色。在多类别分类问题中,每种颜色代表一种类别,共有 6 种类别, 6 种颜色。标签是 1 ~ 7,没有 4。颜色的选择与回归问题中的方式类似:将目标类别(标签)除以其最大值,然后再基于此数值选择颜色。
第一部分是R标签的(岩石),第二部分是M标签的(水雷)。在分析数据时首先要注意到此类信息。在后续章节中会看到,确定模型的优劣有时需要对数据进行取样。那么取样就需要考虑到数据的存储结构
边缘点很可能就是分析模型预测错误的一个重要来源
小结
本章介绍了用于探究新数据集的一些工具,这些工具从简单地获取数据集的规模开始,包括确定数据集属性和目标的类型等。这些关于数据集的基本情况会对数据集的预处理、预测模型的训练提供帮助。
这些概念包括:简单的统计信息(均值、标准差、分位数)、二
阶统计信息,如属性间的相关性、属性与目标间的相关性。当目标是二值时,计算属性与目标相关性的方法与目标是实数(回归问题)时有所不同。本章也介绍了可视化技巧:利用分位数图来显示异常点;利用平行坐标图来显示属性和目标之间的相关性。上述方法和技巧都可以应用到本书后续的内容,用来验证算法以及算法之间的对比。
预测模型的构建:平衡性能、复杂性以及大数据
- 使用训练数据
- 评估模型性能
好的性能意味着使用属性 x i 来生成一个接近真实 y i 的预测,这种“接近”对不同问
题含义不同。
对于回归问题,y i 是一个实数,性能使用均方误差(MSE)或者平均绝对误差(MAE)来度量。
如果问题是一个分类问题,那么需要使用不同的性能指标。最常用的性能指标是误分类率,即计算 pred() 函数预测错误的样本比例
影响算法选择及性能的因素——复杂度以及数据
有几个因素影响预测算法的整体性能。这些因素包括问题的复杂度、模型复杂度以及
可用的训练数据量。下面将介绍这些因素是如何一起来影响预测性能的。
应用数据科学家需要对算法性能进行评估,从而为客户提供合理的期望并且对算法进行比较。对模型进行评估的最佳经验是从训练数据集中预留部分数据。样本外误差
只有在新样本上计算得到的性能才能算是模型的性能。
- 简单问题 复杂问题(边界)
数据有限的复杂问题选简单模型 - 简单模型 复杂模型
现代机器学习算法往往生成模型族,不只是单个模型
最好的办法是用复杂模型解决复杂问题,用简单模型解决简单问题,但是必须考虑问题的另一维度;即,必须考虑数据规模。
- 数据的分布形状也很重要
数据集长宽比
对于列比行多的数据集或者相对简单的问题,倾向于使用线性模型。对于行比列多很多的复杂问题,倾向于使用非线性模型。另一个考虑因素是训练时间。线性方法要比非线性方法训练时间短
度量预测模型性能
- 回归问题
MSE MAE RMSE
代码清单最后是方差的计算(与均值的均方误差)以及标准差计算(方差的开方)。这些量与预测错误指标 MSE 以及 RMSE 进行比较非常有意义。例如,如果预测错误的 MSE 同目标方差几乎相等(或者 RMSE 与目标标准差几乎相等),这说明预测算法效果并不好,通过简单对目标值求平均来替换预测算法就能达到几乎相同的效果。
除了计算错误的摘要统计量以外,查看错误的分布直方图、长尾分布(使用分位数或
者等分边界)以及正态分布程度等对于分析错误原因以及错误程度也非常有用。有时这些探索会对定位错误原因以及提升潜在性能带来启发。
*分类问题
概率 阈值
混淆矩阵
最佳决策阈值应该是能够最小化误分类率的值。然而,不同类错误对应的代价可能是
不同的。
一些用于估算2分类问题性能的方法同样适用于多分类问题。误分类错误仍然有意义,混淆矩阵也同样适用。有许多将 ROC 曲线以及 AUC 指标推广到多分类应用的工作 - 30%测试集(均匀采样)
- n折交叉验证
- 分层抽样(分别从欺诈样本以及合法样本)
样本外测试已经可以给出预测错误的期望结果。如果能在更多数据上进行训练,模型效果会更好,泛化能力也更好。真正要部署的模型应该在所有数据上进行训练。
最小二乘法OLS
过拟合,列太多 最佳子集回归
使用前向逐步回归来控制过拟合
最佳子集选择以及前向逐步回归过程基本类似。它们训练一系列的模型(列数为 1 训
练几个,列数为 2 训练几个,等等)。这种方法产生了参数化的模型族(所有线性回归以列数作为参数)。这些模型在复杂度上存在差异,最后的模型通过在预留样本上计算错误进行选择。
属性已经根据其对预测的重要性进行了排序
第一个元素是第一个选择的属性,第二个元素是第二个选择的属性,
以此类推。用到的属性按顺序排列。这是机器学习任务中一个很重要并且必需的特征。早期机器学习任务大部分都包括寻找(或者构建)用于构建预测的最佳属性集。而能够对属性进行排序的算法对于上述任务非常有帮助。
通过惩罚回归系数来控制过拟合——岭回归
最佳子集回归以及前向逐步回归通过限制使用的属性个数来控制回归的复杂度。另外一种方法称作惩罚系数回归。惩罚系数回归是使系数变小,而不是将其中一些系数设为 0。一种惩罚线性回归的方法被称作岭回归。
前向逐步回归算法生成了一系列不同的模型,第一个模型只包含一个属性,第
二个模型包含两个属性,等等,直到最后的模型包含所有属性。岭回归代码也包含一系列的模型。岭回归通过不同的 α 值来控制模型数量,而不是通过属性个数来控制。α 参数决定了对β的惩罚力度。
小结
本章首先给出了围绕问题复杂性以及模型复杂性的可视化示例,讨论了这些因素以及数据集大小如何影响给定问题的分类性能。接着讨论了针对不同问题(回归、分类以及多分类)度量预测性能的多个评价指标,这些指标也是函数逼近问题的一部分。介绍了用于在新数据上评估性能的 2 种方法(在测试集上评估以及 n 折交叉验证)、机器学习生成一族参数化模型的框架,以及如何基于测试集的性能来选择实际应用的模型