Selenium2Library 库
Selenium 是非常流行的开源 web 自动化测试工具,对于大多使用 Robot Framework 框架的人都会有使用 Selenium2Library 库来进行 web 自动化测试工具。
Selenium 是支持多种开发语言的,对于不同的语言来说都有其对应的库。
对 Robot Framework 框 架 的 Selenium 库 有 两 个 : SeleniumLibrary 和 Selenium2Library 。
SeleniumLibrary 是基于 Selenium1.0 开发的,Selenium2Library 是基于 Selenium2.0 开发的。如果没有历史遗留问题,我们直接使用 Selenium2Library。
安装 Selenium2Library
下载地址:https://github.com/robotframework/Selenium2Library
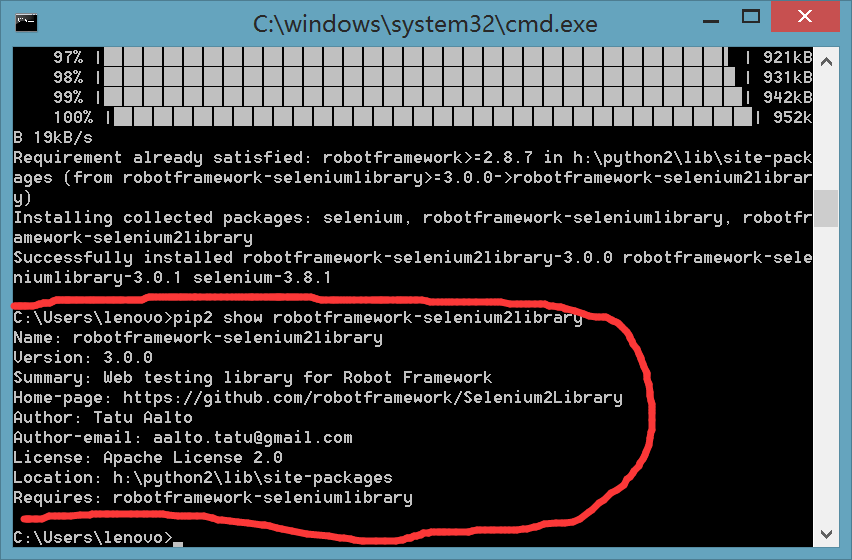
安装命令
pip install robotframework-selenium2library
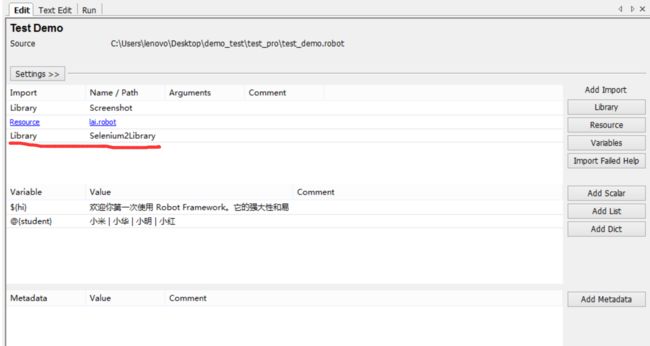
将“Selenium2Library”库添加到相应的测试套件中。显示黑色,加载成功。
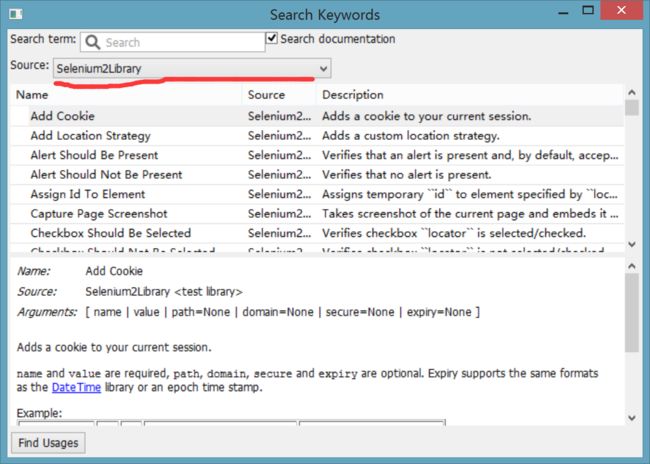
通过按 F5 快捷键来查询库所提供的关键字
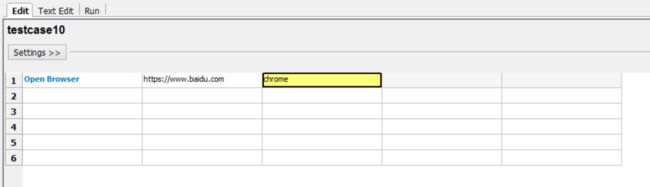
第一个例子
我们打开浏览器,打开的网址是https://www.baidu.com,浏览器选择chrome
我们需要选择和我们chrome浏览器对应的chromedriver.exe版本,并且放入python的工作目录下。
元素定位
对于 Web 自动化测试来说,就是操作页面上的各种元素,在操作元素之间需要先找到元素,换句话说就是定位元素。
Selenium2Library 提供了非常丰富的定位器:
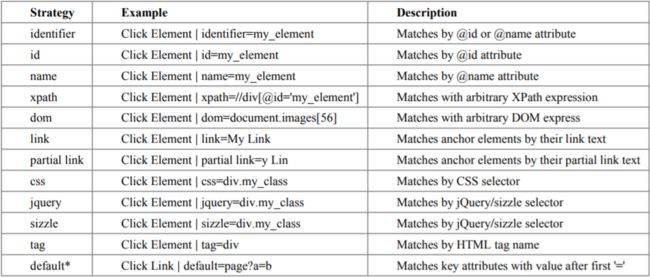
虽提供了这么多种定位方式,并不是要求我们每一种都要学会。在这里我只介绍 4 种定位方式,id、name、xpath 和 css。介绍 id 和 name,是因为这两种定位方式非常简单且实用,介绍 xpath 和 css,是因为这两种定位方式足够强大,可以满足几乎所有定位需求。
需要一定的HTML和CSS知识
id 和 name 定位
假如把一个元素看作一个人的话,id 和 name 可以看作一个人的身份证号和姓名。当然,这些属性值
是否唯一要看前端工程师如何设计了。
根据上面的例子,百度输入框可以取 id 或 name 进行定位。(前提是 id 和 name 的值在当页面上唯一)
id = kw1
name = wd
在 Robot framework 中就是这样写的:

Input text 用于输入框的关键字,“robot framework 学习”是要给输入框输入的内容。
百度按钮只 id 数据可以利用:
id=su
Click Button 是按钮点击的关键字
xpath 定位
XPath 是一种在 XML 文档中定位元素的语言。因为 HTML 可以看做 XML 的一种实现,所以 selenium
用户可是使用这种强大语言在 web 应用中定位元素。
假如,一个人没身份证号没名字怎么找呢?想想你是怎么找朋友吃饭的,他手机不通,电话不回呢?
直接上他家去呗,那你一定有他家住址,xx 市 xx 区 xx 路 xx 号。xpath 就可以通过这种层级关系找到元素。
1、xpath 的绝对路径:
xpath = /html/body/div[1]/div[4]/div[2]/div/form/span[1]/input
我们可以从最外层开始找,html 下面的 body 下面的 div 下面的第 4 个 div 下面的....input 标签。通过
一级一级的锁定就找到了想要的元素。
2、xpath 的相对路径:
绝对路径的用法往往是在我们迫不得已的时候才用的。大多时候用相对路径更简便。
2.1、元素本身:
Xpath 同样可以利用元素自身的属性:
Xpath = //[@id=’kw1’]
//表示某个层级下,表示某个标签名。@id=kw1 表示这个元素有个 id 等于 kw1 。
当然,一般也可以制定标签名:
Xpath = //input[@id=’kw1’]
元素本身,可以利用的属性就不只局限为于 id 和 name ,如:
Xpath = //input[@type=’text’]
Xpath = //input[@autocomplete=’off’]
但要保证这些元素可以唯一的识别一个元素。
2.2、找上级:
当我们要找的一个人是个刚出生的婴儿,还没起名子也没有入户口(身份证号),但是你会永远跟在
你父亲的身边,你的父亲是有唯一的名字和身份证号的,这样我们可以先找到你父亲,自然就找到你的。
元素的上级属性为:
找爸爸:
xpath = //span[@class=’bg s_ipt_w’]/input
如果爸爸没有唯一的属性,可以找爷爷:
xpath = //form[@id=’form1’]/span/input
这样一级一级找上去,直到 html ,那么就是一个绝对路径了。
2.3、布尔值写法:
如果一个人的姓名不是唯一的,身份证号也不是唯一的,但是同时叫张三 并且 身份证号为 123 的
人却可以唯一的确定一个人。那么可以这样写:
Xpath = //input[@id=’kw1’ and @name=’wd’]
可以 and ,当然也可以 or :
Xpath = //input[@id=’kw1’ or @name=’wd’]
但 or 的实际意义不太。我们一般不需要说,找的人名字或者叫张三,或者身份证号是 123 也可以。
Robot framework 中的写法:

css 定位
CSS(Cascading Style Sheets)是一种语言,它被用来描述 HTML 和 XML 文档的表现。CSS 使用选择器来为页面元素绑定属性。这些选择器可以被 selenium 用作另外的定位策略。
CSS 可以比较灵活选择控件的任意属性,一般情况下定位速度要比 XPath 快,但对于初学者来说比较难以学习使用,下面我们就详细的介绍 CSS 的语法与使用。
CSS 选择器的常见语法:
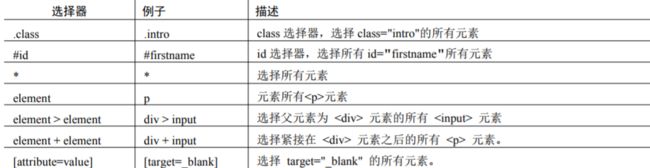
通过 class 属性定位:
css=.s_ipt
css=.bg s_btn
csscss_selector()方法用于 CSS 语言定位元素,点号(.)表示通过 class 属性来定位元素。
通过 id 属性定位:
css=#kw
css=#su
井号(#)表示通过 id 属性来定位元素。
通过标签名定位:
css=input
在 CSS 语言中用标签名定位元素不需要任何符号标识,直接使用标签名即可,但我们前面已经了解到
标签名重复的概率非常大,所以通过这种方式很难唯一的标识一个元素。
通过父子关系定位:
css=span>input
上面的写法表示有父亲元素,它的标签名叫 span,查找它的所有标签名叫 input 的子元素。
通过属性定位:
css=input[autocomplete='off']
css=input[maxlength='100']
css=input[type='submit']
在 CSS 当中也可以使用元素的任意属性,只要这些属性可以唯一的标识这个元素。
组合定位:
我们当然可以把上面的定位策略组合起来使用,这样就大大加强了元素的唯一性。
css=span.bg s_ipt_wr>input.s_ipt
css=span.bg s_btn_wr>input#su
有一个父元素,它的标签名叫 span,它有一个 class 属性值叫 bg s_ipt_wr,它有一个子元素,标签名叫 input,并且这个子元素的 class 属性值叫 s_ipt。好吧!我们要找的就是具有这么多特征的一个子元素。
Robot framework 中的写法:

Selenium2Library 关键字
通过不同的浏览器执行脚本
浏览器对应的关键字:

open browser 同样也可以打开本地 html 页面,如:
备注:
要想通过不同的浏览打开 URL 地址,一定要安装浏览器相对应的驱动。
(可以查看我之前的selenium驱动器配置详解)
关闭浏览器
浏览器最大化
Maximize Browser Window 关键字使当前打开的浏览器全屏
设置浏览器窗口宽、高
get windows size 关键字用于打设置打开浏览器的宽度和高度。以像素为单位,第一个参数 800 表示宽度,第二个参数 600 表示高度。

get windows size 关键字,用于获取当前浏览器的宽度和高度。获得浏览浏览器窗口宽、高,将显示在log.html 的日志中。
文本输入
input text 关键字用于向文本框内输入内容。
xpath=//* [@] :表示元素定位,定位文本输入框
点击元素
Click Element 关键字用于点击页面上的元素,单击任何可以点击按钮、文字/图片连接、复选框、单选框、甚至是下拉框等。
xpath=//* [@] :表示元素定位,定位点击的元素。
点击按钮
Click Element 关键字用于点击页面上的按钮。
Xpath=//* [@] :表示元素定位,定位点击的按钮。
等待元素出现
Wait Until Page Contains Element 关键字用于等待页面上的元素显示出来。
Xpath=//* [@] :表示元素定位,这里定位出现的元素
42 : 表示最长等待时间。
Error : 表示错误提示,自定义错误提示,如:“元素不能正常显示”
获取 title
get title 关键字用于获得当前浏览器窗口的 title 信息。
这里只获取 title 是没有意义的,我们通常会将获取的 title 传递给一个变量,然后与预期结果进行比较。从而判断当前脚本执行成功。
获取 text
get text 关键字用于获取元素的文本信息。
xpath=//* [@] : 定位文本信息的元素。
获取元素属性值
id=kw@name:id=kw 表示定位的元素。@nam 获取这个元素的 name 属性值。
cookei 处理

get cookies 获得当前浏览器的所有 cookie 。
get cookie value 获得 cookie 值。key_name 表示一对 cookie 中 key 的 name 。
add cookie 添加 cookie。添加一对 cooke (key:value)
delete cookie 删除 cookie。删除 key 为 name 的 cookie 信息。
delete all cookies 删除当前浏览器的所有 cookies。
验证
获得浏览器 title 进行比较

Open Browser 通过 chrome 打开百度首页。
Get Title 获得浏览器窗口的 titile ,并赋值给变量${title}
Should Contain 比较${title}是否等于“百度一下,你就知道”。
获得文本信息进行比较
表单嵌套
有时候和页面中会出现表单嵌套,这个时候需要进入到表单才能操作相关元素
Select Frame 进入表单,Xpath=//* [@] 表示定位要进入的表单。
Unselect Frame 退出表单。
下拉框选择
Unselect From List By Value 关键字用天选择下拉框。
Xpath=//* [@] 定位下拉框;
Vlaue 选择下拉框里的属性值。
执行 JavaScript
在一些特殊的情况下需要调用 JavaScript 代码。
Execute Javascript 关键字用于使用 JavaScript 代码