Course Digest
复杂度与计算量
- python中is和==的区别:
Python中的对象包含三要素:id、type、value
其中id用来唯一标识一个对象(Cython中就是对象的内存地址),type标识对象的类型,value是对象的值
is判断的是a对象是否就是b对象,是通过id来判断的
==判断的是a对象的值是否和b对象的值相等,是通过value来判断的
在Python中,小数字是统一存储的,故可以用is检测两个小整数是否相等。
Python 源码阅读 —— int 小整数对象池[-5, 257]
在\Python-3.6.0\Objects\longobject.c中有关于小数组的定义和说明:
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif
#if NSMALLNEGINTS + NSMALLPOSINTS > 0
/* Small integers are preallocated in this array so that they
can be shared.
The integers that are preallocated are those in the range
-NSMALLNEGINTS (inclusive) to NSMALLPOSINTS (not inclusive).
*/
static PyLongObject small_ints[NSMALLNEGINTS + NSMALLPOSINTS];
Python内部还有好多东西不知道,是时候看一波Python源码了,在这之前,需要有编译器的知识。两本书《Python源码剖析》以及《Code Implementation》。
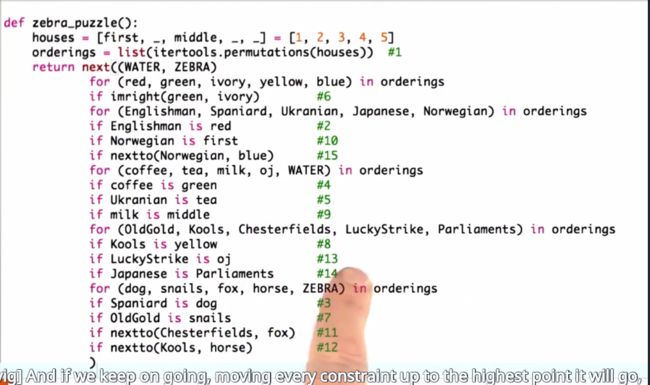
1st Try(Brute Force)

TimeCall
类似装饰器的用法
Aspect-Oriented Programing

For Statement Truth

c Fucntion
Zebra Summary
- Python中定义的函数默认返回None
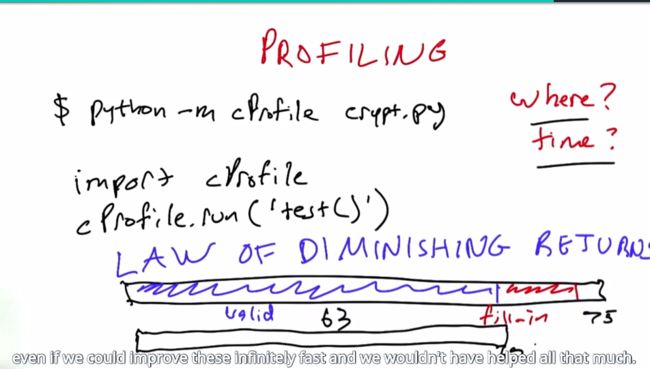
cProfile详细计时程序
- the law of diminishing returns
Code
import string, re, itertools
def solve(formula):
"""Given a formula like 'ODD + ODD == EVEN', fill in digits to solve it.
Input formula is a string; output is a digit-filled-in string or None."""
for f in fill_in(formula):
if valid(f):
return f
def fill_in(formula):
"Generate all possible fillings-in of letters in formula with digits."
letters = ''.join(set([ch for ch in formula if 'a'<=ch<='z' or 'A'<=ch<='Z'])) #should be a string
# letters = ''.join(set(re.findall('[A-Za-z]', formula)))
for digits in itertools.permutations('1234567890', len(letters)):
table = string.maketrans(letters, ''.join(digits))
yield formula.translate(table)
def valid(f):
"""Formula f is valid if and only if it has no
numbers with leading zero, and evals true."""
try:
return not re.search(r'\b0[0-9]', f) and eval(f) is True
except ArithmeticError:
return False
# --------------
# User Instructions
#
# Modify the function compile_formula so that the function
# it returns, f, does not allow numbers where the first digit
# is zero. So if the formula contained YOU, f would return
# False anytime that Y was 0
import re
import itertools
import string
def compile_formula(formula, verbose=False):
letters = ''.join(set(re.findall('[A-Z]', formula)))
parms = ', '.join(letters)
tokens = map(compile_word, re.split('([A-Z]+)', formula))
body = ''.join(tokens)
f = 'lambda %s: %s' % (parms, body)
if verbose: print f
return eval(f), letters
def compile_word(word):
"""Compile a word of uppercase letters as numeric digits.
E.g., compile_word('YOU') => '(1*U+10*O+100*Y)'
Non-uppercase words uncahanged: compile_word('+') => '+'"""
if word.isupper():
terms = [('%s*%s' % (10**i, d))
for (i, d) in enumerate(word[::-1])]
return '(' + '+'.join(terms) + ')'
else:
return word
def faster_solve(formula):
"""Given a formula like 'ODD + ODD == EVEN', fill in digits to solve it.
Input formula is a string; output is a digit-filled-in string or None.
This version precompiles the formula; only one eval per formula."""
f, letters = compile_formula(formula)
for digits in itertools.permutations((1,2,3,4,5,6,7,8,9,0), len(letters)):
try:
if f(*digits) is True:
table = string.maketrans(letters, ''.join(map(str, digits)))
return formula.translate(table)
except ArithmeticError:
pass
上述三个函数比之前的方法总体上快了25倍。首先使用cProfile函数找到了程序运行的瓶颈——eval()函数,然后通过少调用eval()函数来实现增速。也要注意老师给出程序中普遍使用的函数式编程方法,比如map()的使用。改变之后的eval()函数只用返回一个lambda函数,而不用于等式正确性的评估。
HW1
def compile_formula(formula, verbose=False):
letters = ''.join(set(re.findall('[A-Z]', formula)))
parms = ', '.join(letters)
# leadingletter = ', '.join(set([word[0] for word in re.findall('([A-Z]+)', formula) if len(word)>1]))
leadingletter = ', '.join(set(re.findall('([A-Z])[A-Z]+', formula)))
tokens = map(compile_word, re.split('([A-Z]+)', formula))
body = ''.join(tokens)
f = 'lambda %s: %s if 0 not in (1, %s) else False' % (parms, body, leadingletter)
if verbose: print f
return eval(f), letters

Teacher's Version
HW2
import itertools
def floor_puzzle():
for Hopper, Kay, Liskov, Perlis, Ritchie in itertools.permutations([1, 2, 3, 4, 5], 5):
if Hopper != 5 and Kay != 1 and (Liskov not in (1, 5)) and Perlis > Kay and abs(Ritchie-Liskov) != 1 \
and abs(Kay-Liskov) != 1:
return [Hopper, Kay, Liskov, Perlis, Ritchie]
HW3
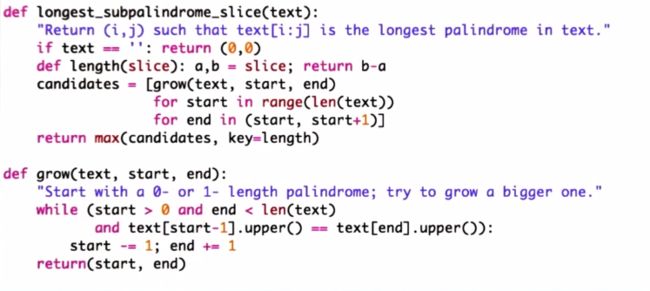
def longest_subpalindrome_slice(text):
"Return (i, j) such that text[i:j] is the longest palindrome in text."
text = text.lower()
n = len(text)
for l in range(n, 0, -1):
for i in range(n-l+1):
if isPalindrome(text[i:i+l]):
return i, i+l
return 0, 0
def isPalindrome(text):
return text == text[::-1]
Teacher's Version
回文字符串算法