小孔同学推荐了两个基于循环神经网络以及CRF处理nlp问题的算法,分别是中分分词以及命名实体识别,都是github上开源的项目,之前也用过一些开源的分词工具以及产品级分词工具,比如波森nlp,发现github上这两个【BiLSTM+CRF】 【NeuroNER】,效果都非常不错,感谢koth 以及 Franck Dernoncourt。在这不分析模型,只说下把两个模型frozen一下,然后一块封装到nlp相关的接口中,通过flask可以非常方便的发布供项目其他模块使用~
分词模型
按照README中介绍的过程训练模型,训练完成后,想把分词作为工程的其他模块通过接口的形式发布出来,在这直接使用了作者固化出来的模型在Python中加载,最终脚本如下所示,指示单句子分词,如果是长文本,参照着作者github中 kcws/cc/seg_backend_api.cc 调用的分割函数,分割成短文本即可。
"""
分词主类,加载预先训练好并固化好的模型文件,加载训练生成的词-id映射表并进行分词
"""
import numpy as np
import tensorflow as tf
import math
class Node:
"""
trie树中的节点, weight=0 表示该节点不是叶子节点
"""
def __init__(self):
self.weight = 0.0
self.next = {}
class Trie:
"""
trie 树实现,用来添加用户自定义词典
每个节点包括一个权重以及指向下一个节点的连接
权重初始化为0,当该节点是词的最终节点时,权重赋值为用户自定义词典的权重
"""
def __init__(self):
self.root = Node()
def push_node(self, word, weight):
"""
将词与权重压入构建trie数的节点以及路径
:param word: 词
:param weight: 权重
:return: None
"""
word_len = len(word)
if word_len == 0: return
temp = self.root
for index, char in enumerate(word):
if char in temp.next:
temp = temp.next[char]
if index + 1 == word_len: temp.weight = weight
continue
else:
temp.next[char] = Node()
temp = temp.next[char]
if index + 1 == word_len: temp.weight = weight
def search(self, sentence):
"""
对输入的文本通过trie树做检索,查找文本中出现的用户自定义词,并返回该词所在位置以及该词权重
:param sentence: 文本
:return: eg: [([0, 1], 4.0), ([9, 10, 11], 4.0)]
tuple 列表,其中[0, 1]表示该词出现在句子的第0,1索引出, 4.0表示用户对该词定义的权重
"""
fake_list = []
word_len = len(sentence)
if word_len == 0: return fake_list
point = self.root
index = 0
pre_match = -1
word_range = None
while index < word_len:
word = sentence[index]
if word in point.next:
if pre_match < 0: pre_match = index
point = point.next[word]
index += 1
if point.weight > 0: word_range = ([i for i in range(pre_match, index)], point.weight)
if index == word_len: fake_list.append(word_range)
continue
else:
if word_range: fake_list.append(word_range)
word_range = None
point = self.root
index = pre_match + 1 if pre_match >= 0 else index + 1
pre_match = -1
return fake_list
class Segment:
def __init__(self, frozen_model_path, vocab_path, user_dict_path=None):
self.seq_max_len = 80
self.graph = None
self.frozen_model_path = frozen_model_path
self.base_vocab_path = vocab_path
self.user_dict_path = user_dict_path
self.user_dict = None
self.sess = None
self.graph = None
self.input = None
self.transitions = None
self.unary_score = None
self.word_2_index = dict()
self.load_model()
def load_model(self):
"""
加载深度神经网络模型,提取输入节点以及输出节点
得到状态转移概率矩阵
Returns: None
"""
self.load_basic_vocab()
self.load_user_dict()
with tf.gfile.GFile(self.frozen_model_path, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, input_map=None, return_elements=None, name="prefix", op_dict=None,
producer_op_list=None)
self.graph = graph
self.sess = tf.Session(graph=self.graph)
transitions_ = self.graph.get_tensor_by_name("prefix/transitions:0")
self.unary_score = self.graph.get_tensor_by_name("prefix/Reshape_7:0")
self.input = self.graph.get_tensor_by_name("prefix/input_placeholder:0")
self.transitions = self.sess.run([transitions_])
self.transitions = np.squeeze(np.array(self.transitions), axis=0)
def load_basic_vocab(self):
"""
加载词映射表 汉字:id
Returns: None
"""
with open(self.base_vocab_path, "r") as file_rd:
for line in file_rd.readlines():
line = line.strip()
[word, index] = line.split(" ")
try:
self.word_2_index[word] = int(index)
except Exception: pass
def load_user_dict(self):
"""
加载用户自定义词典,生成trie树,viterbi解码前对unary code 进行修改
:return: None
"""
if not self.user_dict_path:
self.user_dict = None
return
else:
self.user_dict = Trie()
with open(self.user_dict_path, "r") as file_rd:
for line in file_rd.readlines():
line = line.strip()
if line and line == "": continue
try:
word, weight = line.split(" ")
self.user_dict.push_node(word, float(weight))
except Exception:
pass
def fake_predication(self, unary_scores, sentence):
"""
通过用户自定义词典检索句子,修改自定义词处的概率向量,用于后续的viterbi解码
:param unary_scores: 句子的状态概率矩阵,shape=(sentence_len, state_len)
:param sentence: 原句子
:return: None
"""
fake_list = self.user_dict.search(sentence)
sentence_len = unary_scores.shape[0]
for item in fake_list:
if max(item[0]) > sentence_len:
return
word_range = item[0]
word_weight = item[1]
word_len = len(word_range)
for index in range(word_len):
weight_total = 4.0 + word_weight
if index == 0:
weights = [1.0, 1.0 + word_weight, 1.0, 1.0]
elif index + 1 == word_len:
weights = [1.0, 1.0, 1.0, 1.0 + word_weight]
else:
weights = [1.0, 1.0, 1.0 + word_weight, 1.0]
weights = [math.log(i / weight_total) for i in weights]
unary_scores[word_range[index]] = weights
def predict(self, content):
"""
分割主函数
Args:
content: 待分割的文本
eg: 赵雅淇洒泪道歉和林丹没有任何经济关系
Returns: 分割后的字符串
eg: [{"tok": "赵雅琪"},{"tok": "洒泪"},{"tok": "道歉"},{"tok": "和"},
{"tok": "林丹"},{"tok": "没有"},{"tok": "任何"},{"tok": "经济"},{"tok": "关系"}]
"""
result = []
word_index_seq = []
for word in content:
if word in self.word_2_index:
word_index_seq.append(self.word_2_index[word])
else:
word_index_seq.append(1)
word_index_seq.extend([0] * (self.seq_max_len - len(word_index_seq)))
feed_input = np.expand_dims(np.array(word_index_seq), axis=0)
unary_score_val = self.sess.run([self.unary_score], {self.input: feed_input})
seq_len = sum([1 for item in word_index_seq if item > 0])
tf_unary_scores_ = np.squeeze(unary_score_val[0], axis=0)
tf_unary_scores_ = tf_unary_scores_[:seq_len]
if self.user_dict:
# 是否启用用户自定义词典进行优化分词结果
self.fake_predication(tf_unary_scores_, content)
tag_sequence, _ = tf.contrib.crf.viterbi_decode(tf_unary_scores_, self.transitions)
pre_word = ""
for tag, word in zip(tag_sequence, content):
if tag == 0:
pre_word = ""
result.append({"tok": word})
elif tag == 1 or tag == 2:
pre_word += word
elif tag == 3:
pre_word += word
result.append({"tok": pre_word})
pre_word = ""
return result
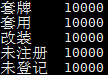
其中frozen_model_path是frozen之后生成的pb文件,vocab_path则是词-ID对照文件,user_dict_path是用户自定义词典,如图所示:

参照着koth的方法,网络输出的句子状态概率矩阵,在进行viterbi解码之前通过用户自定义词典以及权重进行调整,之后再解码,如果让我自己去想怎么实现,我可能会直接在viterbi解码后的状态向量,通过自定义词强行进行拆分合并。
命名实体识别模型
命名实体识别的项目也用了相似的,感兴趣的不妨也参考下,最终大致也是通过相同的方式对模型进行固化,然后封装到接口中。
# -*- coding:utf-8 -*-
"""
命名实体识别主类
加载预先训练好并固化好的模型文件,加载词向量模型文件
"""
import numpy as np
import tensorflow as tf
import dataset_predict as ds
class NERPredict:
def __init__(self, frozen_model_path, word_2_vec_path, trained_model_path):
self.graph = None
self.frozen_model_path = frozen_model_path
self.word_vec_path = word_2_vec_path
self.pre_trained_model_path = trained_model_path
with tf.gfile.GFile(self.frozen_model_path, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, input_map=None, return_elements=None, name="prefix", op_dict=None,
producer_op_list=None)
self.graph = graph
self.transition_params_trained = self.graph.get_tensor_by_name('prefix/crf/transitions:0')
self.input_token_indices = self.graph.get_tensor_by_name('prefix/input_token_indices:0')
self.dropout_keep_prob = self.graph.get_tensor_by_name('prefix/dropout_keep_prob:0')
self.unary_scores = self.graph.get_tensor_by_name('prefix/feedforward_before_crf/scores:0')
self.predictions = self.graph.get_tensor_by_name('prefix/feedforward_before_crf/predictions:0')
self.sess = tf.Session(graph=self.graph)
self.dataset = ds.Dataset(verbose=False, debug=False)
self.parameters = {
'token_pretrained_embedding_filepath': self.word_vec_path,
'pretrained_model_folder': self.pre_trained_model_path,
'remap_unknown_tokens_to_unk': True
}
self.dataset.load_dataset(self.parameters)
transition_temp = self.sess.run([self.transition_params_trained])
transition_temp = np.array(transition_temp)
self.transition = np.squeeze(transition_temp, axis=0)
def predict(self, tokens_of_sentence):
"""
实体识别主函数
Args:
content: 词序列
Returns: 实体识别结果
"""
small_score = -1000.0
large_score = 0.0
if isinstance(tokens_of_sentence, str):
tokens_of_sentence = tokens_of_sentence.split(" ")
token_indices, label_indices, character_indices_padded, character_indices, token_lengths, \
characters, label_vector_indices = self.dataset.convert_to_indices_for_sentence(
tokens_of_sentence)
feed_dict = {
self.input_token_indices: token_indices["deploy"][0],
self.dropout_keep_prob: 1.
}
unary_scores, predictions = self.sess.run([self.unary_scores, self.predictions], feed_dict)
unary_scores = np.squeeze(np.array(unary_scores))
concate_array = np.ones(shape=(unary_scores.shape[0], 2), dtype=np.float32) * small_score
unary_scores = np.concatenate((unary_scores, concate_array), axis=1)
start_unary_scores = np.array([[small_score] * self.dataset.number_of_classes + [large_score, small_score]])
end_unary_scores = np.array([[small_score] * self.dataset.number_of_classes + [small_score, large_score]])
unary_scores = np.concatenate((start_unary_scores, unary_scores, end_unary_scores), axis=0)
predictions, _ = tf.contrib.crf.viterbi_decode(unary_scores, self.transition)
predictions = predictions[1:-1]
assert (len(predictions) == len(tokens_of_sentence))
predictions = [self.dataset.index_to_label[index] for index in predictions]
return predictions
dataset_predict 是工程自带的一个类,偷懒直接纠过来用了,至于怎样frozen原模型生成pb文件,在这不在介绍。从代码中可以看到循环神经网络结合CRF 做分词以及命名实体识别的模型结构几乎是一致的,最终也都用到了viterbi解码,有兴趣的可以参考下。
模型固化部分(针对ner项目)
"""
frozen the model test
"""
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()
output_nodes = ['crf/transitions', 'feedforward_before_crf/scores', 'feedforward_before_crf/predictions']
output_graph_def = graph_util.convert_variables_to_constants(sess, input_graph_def, output_nodes)
with tf.gfile.GFile("frozen_model.pb", "wb") as f:
f.write(output_graph_def.SerializeToString())
print("frozen the ner model")
"""
frozen model test finish
"""
欢迎一块交流讨论,文中有错误的地方,还请指正,谢谢~
email: [email protected]