Java集合工具包位于Java.util包下,包含了很多常用的数据结构,如数组、链表、栈、队列、集合、哈希表等。学习Java集合框架下大致可以分为如下五个部分:List列表、Set集合、Map映射、迭代器(Iterator、Enumeration)、工具类(Arrays、Collections)。
Java集合类的整体框架如下:

Java集合工具包位于Java.util包下,包含了很多常用的数据结构,如数组、链表、栈、队列、集合、哈希表等。学习Java集合框架下大致可以分为如下五个部分:List列表、Set集合、Map映射、迭代器(Iterator、Enumeration)、工具类(Arrays、Collections)。
Collection是List、Set等集合高度抽象出来的接口,它包含了这些集合的基本操作,它主要又分为两大部分:List和Set。
List接口通常表示一个列表(数组、队列、链表、栈等),其中的元素可以重复,常用实现类为ArrayList和LinkedList,另外还有不常用的Vector。另外,LinkedList还是实现了Queue接口,因此也可以作为队列使用。
Set接口通常表示一个集合,其中的元素不允许重复(通过hashcode和equals函数保证),常用实现类有HashSet和TreeSet,HashSet是通过Map中的HashMap实现的,而TreeSet是通过Map中的TreeMap实现的。另外,TreeSet还实现了SortedSet接口,因此是有序的集合(集合中的元素要实现Comparable接口,并覆写Compartor函数才行)。
我们看到,抽象类AbstractCollection、AbstractList和AbstractSet分别实现了Collection、List和Set接口,这就是在Java集合框架中用的很多的适配器设计模式,用这些抽象类去实现接口,在抽象类中实现接口中的若干或全部方法,这样下面的一些类只需直接继承该抽象类,并实现自己需要的方法即可,而不用实现接口中的全部抽象方法。
Map是一个映射接口,其中的每个元素都是一个key-value键值对,同样抽象类AbstractMap通过适配器模式实现了Map接口中的大部分函数,TreeMap、HashMap、WeakHashMap等实现类都通过继承AbstractMap来实现,另外,不常用的HashTable直接实现了Map接口,它和Vector都是JDK1.0就引入的集合类。
Iterator是遍历集合的迭代器(不能遍历Map,只用来遍历Collection),Collection的实现类都实现了iterator()函数,它返回一个Iterator对象,用来遍历集合,ListIterator则专门用来遍历List。而Enumeration则是JDK1.0时引入的,作用与Iterator相同,但它的功能比Iterator要少,它只能再Hashtable、Vector和Stack中使用。
Arrays和Collections是用来操作数组、集合的两个工具类,例如在ArrayList和Vector中大量调用了Arrays.Copyof()方法,而Collections中有很多静态方法可以返回各集合类的synchronized版本,即线程安全的版本,当然了,如果要用线程安全的结合类,首选Concurrent并发包下的对应的集合类。
转载出处:http://blog.csdn.net/ns_code/article/details/35564663
Collection
|-----List 有序(存储顺序和取出顺序一致),可重复
|----ArrayList ,线程不安全,底层使用数组实现,查询快,增删慢。
效率高。每次容量不足时,自增长度的一半,如下源码可知
int newCapacity = oldCapacity + (oldCapacity >> 1);
|----LinkedList , 线程不安全,底层使用链表实现,查询慢,增删快。效率高。
|----Vector , 线程安全,底层使用数组实现,查询快,增删慢。效率低。
每次容量不足时,默认自增长度的一倍(如果不指定增量的话),如下源码可知
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);
|-----Set 元素唯一,一个不包含重复元素的 collection。
更确切地讲,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。
|--HashSet 底层是由HashMap实现的,通过对象的hashCode方法与equals方法来保证插入元素的唯一性,无序(存储顺序和取出顺序不一致)。
|--LinkedHashSet 底层数据结构由哈希表和链表组成。哈希表保证元素的唯一性,链表保证元素有序。(存储和取出是一致)
|--TreeSet 基于 TreeMap 的 NavigableSet 实现。
使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。元素唯一。

HashMap 和 Hastable 的区别
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。


HashMap采用Entry数组来存储key-value对,每一个键值对组成了一个Entry实体,Entry类实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Entry实体,依次来解决Hash冲突的问题,因为HashMap是按照Key的hash值来计算Entry在HashMap中存储的位置的,如果hash值相同,而key内容不相等,那么就用链表来解决这种hash冲突。
ConcurrentHashMap与HashMap相比,有以下不同点
ConcurrentHashMap线程安全,而HashMap非线程安全
HashMap允许Key和Value为null,而ConcurrentHashMap不允许
HashMap不允许通过Iterator遍历的同时通过HashMap修改,而ConcurrentHashMap允许该行为,并且该更新对后续的遍历可见
Java 8基于CAS的ConcurrentHashMap
注:本章的代码均基于JDK 1.8.0_111
数据结构
Java 7为实现并行访问,引入了Segment这一结构,实现了分段锁,理论上最大并发度与Segment个数相等。Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))。
寻址方式
Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引。同样为了避免不太好的Key的hashCode设计,它通过如下方法计算得到Key的最终哈希值。不同的是,Java 8的ConcurrentHashMap作者认为引入红黑树后,即使哈希冲突比较严重,寻址效率也足够高,所以作者并未在哈希值的计算上做过多设计,只是将Key的hashCode值与其高16位作异或并保证最高位为0(从而保证最终结果为正整数)
CopyOnWriteArrayList如何做到线程安全的
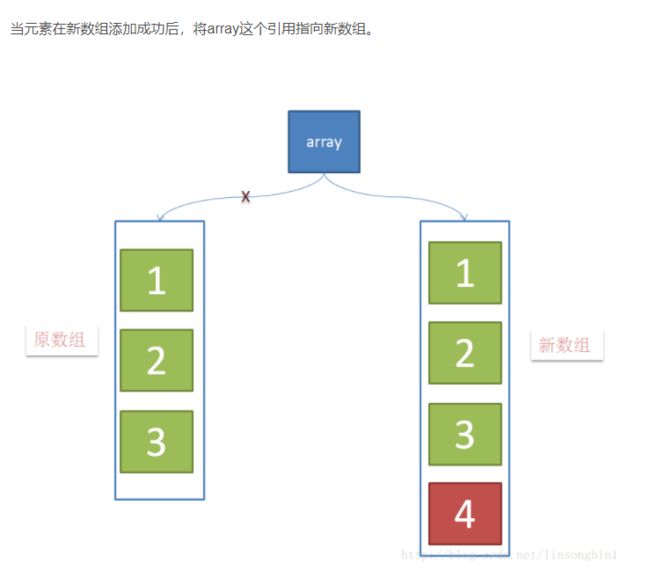
CopyOnWriteArrayList使用了一种叫写时复制的方法,当有新元素添加到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组。
当有新元素加入的时候,如下图,创建新数组,并往新数组中加入一个新元素,这个时候,array这个引用仍然是指向原数组的。