一 、引子
笔者刚开始进入公司的时候,主要是忙于分布式MySQL系统----MyShard的构建,公司使用了大量的IDC机房,基于这种网络特点,MyShard设计当初完全是为了是一套支持Multi-Master操作的高可用性的分布式数据库,可以在多个机房中部署的业务上提供快速的写操作,实现了分布式高可用存储能力。
在业务增长期,MyShard解决了公司的很多大型的数据库存储业务,随着公司业务逐渐稳定下来,分布式存储需求越来越少。而公司却有大量的小业务以及不断尝试的各种新业务,需要越来越多的小数据量的数据库存储。
所以这时候发现,之前的工作方向一直集中在公司的10%不到的业务上,而公司的90%以上的存储需求是MySQL的需求,目前有好上千套的MySQL在给不同的业务提供服务。而在当时,不管是MySQL的交付还是管理都比较原始,极端情况下,我们需要业务申请方自己提供服务器来部署MySQL,所以交付的周期也很长。而在高可用方面,都是需要业务方自己去处理主从切换等等问题,出现主数据库故障的时候,往往需要业务方自己去修改配置文件,重启进程,增加了服务的中断时间。
二、为什么没有采用开源的高可用方案
业界比较流行的MySQL的高可用方案主要有:MMM和MHA两种,对这个方案的分析网上有很多,MHA是优先选取的方案。
MHA的工作原理:
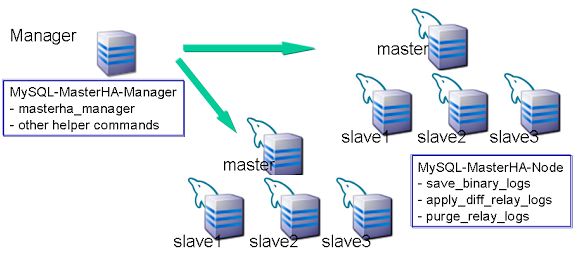
clipboard.png
当master出现故障时,通过对比slave之间I/O线程读取master binlog的位置,选取最接近的slave做为latestslave。其它slave通过与latest slave对比生成差异中继日志。在latest slave上应用从master保存的binlog,同时将latest slave提升为master。最后在其它slave上应用相应的差异中继日志并开始从新的master开始复制。
在MHA实现Master故障切换过程中,MHA Node会试图访问故障的master(通过SSH),如果可以访问(不是硬件故障,比如InnoDB数据文件损坏等),会保存二进制文件,以最大程度保证数据不丢失。MHA和半同步复制一起使用会大大降低数据丢失的危险。
MHA的优点
MHA提供了一个通用的框架,我们可以自定义判断和切换操作的步骤;而且,MHA的代码开源,我们甚至可以进行二次开发,这都为高可用系统提供了很好的扩展 能力。
MHA的缺点
需要在各个节点间打通ssh信任,这对某些公司安全制度来说是个挑战,因为如果某个节点被黑客攻破的话,其他节点也会跟着遭殃;
自带提供的脚本还需要进一步补充完善,当然了,一般的使用还是够用的。
虽然一个MHA Manger可以管理多个集群,但是没有大规模集群的经验。
高可用依赖于vip的方案,譬如采用keepalive来达到vip的切换,但是keepalive会限制切换的主机必须在一个网段,对于跨机房不在一个网段的服务器来说,就无法支持了。在大规模为每个MySQL集群安排一个vip也是难以实现的。keepalive在一个网段内,部署多套也会互相影响。
为什么不采用
我们公司的数据库的特点:
数据库多机房部署
数据库集群规模上千
安全性考虑
三、四层代理----RDS项目
除了MMM和MHA之外,MySQL还可以采用代理来实现高可用,MySQL代理会比MHA方案更适合大规模的使用。
当时阿里和腾讯分别推出了rds和cdb。我们研究了腾讯的cdb方案,cdb是基于TGW也即是NAT的模式实现了4层代理模型,来达到MySQL的高可用以及负载均衡功能。
但是TGW方案有个比较大的问题就是需要修改MySQL协议,一旦修改MySQL协议,所有的客户端(各种语言的驱动)都需要进行修改,这在推广上是非常难的。
所以我们采用了一种折中的方案,启动了RDS项目,主要用于提供MySQL内部云服务,其中高可用方案如下图所示,采用了iptables的NAT来实现MySQL的代理路由功能。
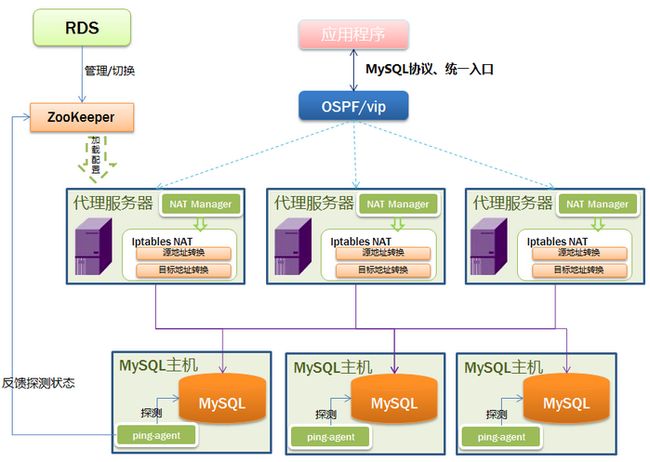
clipboard.png
4层代理层基本实现原理
业务方首先连接到代理服务器上,由于代理服务器上有NAT目标地址转换规则,所以会转到目标MySQL主机上,同时从MySQL主机回包到代理服务器后,由于有NAT源地址转换规则,又会转发回业务方,从而实现了代理功能。
下面举例说明我们如何为一个业务启动RDS四层代理:
我们先准备好以下几台机器:
客户端:172.26.14.16
代理 :172.26.82.45 启动业务代理端口20000
目标机器:172.26.82.7 部署MySQL 端口号为3306
在代理机器上设置规则:
1、打开forward
echo 1 > /proc/sys/net/ipv4/ip_forward
2、设置从客户端请求的目标地址和原地址转换规则
iptables -t nat -A PREROUTING -p tcp -s 172.26.14.16 --dport 3306 -j DNAT --to-destination 172.26.82.7:20000
iptables -t nat -A POSTROUTING -p tcp -d 172.26.82.7 --dport 20000 -j SNAT --to-source 172.26.82.45
3、设置好规则之后,就可以通过mysql来连接到代理的20000端口了。
mysql -utest -ptest -h172.26.82.45 -P20000
这时候,实际访问的是172.26.82.7上3306端口的MySQL数据库。
四、数据库配置中心----代理层(7层代理)
笔者之前一直都在公司云存储中心工作,由于种种原因,2015年年中调到了运维部的数据库团队,在这里才发现,rds项目其实只是在数据库运维平台中走出了很小的一步。为了提供全方位的数据库云服务平台,于是我们开始打造了全新的数据库配置中心,同时提供MySQL、Redis、Mongodb等数据库和缓存内部云服务。
与此同时,之前在rds项目中实现的4层代理的缺点也越来越明显:
只能使用MySQL主库,M-M-S结构是的MySQL资源极其浪费;
只能在单机房使用,跨机房访问效率非常低;
运维功能太少,由于采用iptables,在代理机器上无法看到任何的连接信息,也无法捕获任何业务访问的指标,甚至于连接信息都无法获取;
基于以上几点原因,笔者决定开发基于7层应用层的MySQL代理层平台,系统的具体架构如下所示:
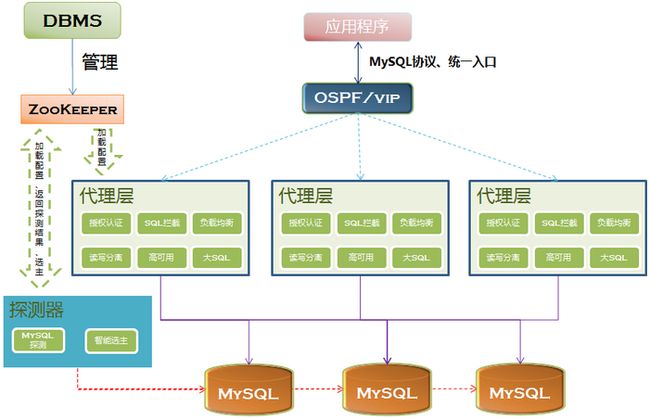
clipboard.png
由于代理层是自己实现的应用程序,所以笔者在代码中很容易就实现以下几个核心的功能:
授权认证模型;
SQL拦截;
负载均衡;
读写分离;
高可用;
大SQL隔离;
除了这些特性以外,基于我们公司的多机房特点,笔者给代理层添加了机房感知能力。在整个数据库配置中心,每个代理层程序、每个MySQL实例都有机房属性。有了机房属性,代理层可以实现自动就近访问MySQL的能力,从而提高了系统性能同时,简化了业务程序的部署。
一个典型的业务部署例子如下:
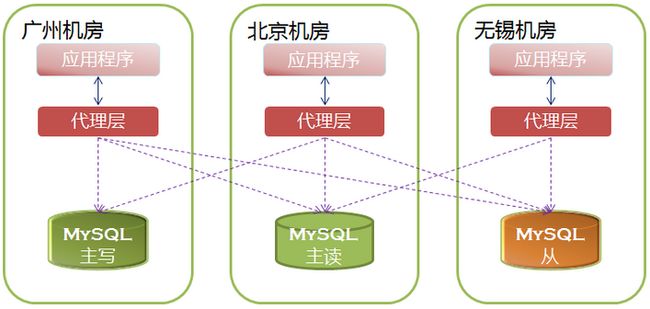
clipboard.png
从上图可以看出,应用程序永远也不再需要考虑多机房高可用、负载均衡、读写分离的问题。而且由于代理层实现了高可用功能,一旦发现主写MySQL故障,会自动把主读切换为主写,从而在秒级实现FAILOVER。
平台级设计
由于我们的代理层采用了平台级的设计,上图中的代理层可以连接多套业务(MySQL集群),新的业务只需要在zookeeper配置好,代理层就会自动感知,业务方马上能够在代理层上使用,而不需要为每个业务部署自己的独立的代理层,从而极大的减少了运维成本。
除此以外采用代理层还为数据库云服务平台带来不少好处:
业务方连接代理机器和相应的端口,底层MySQL主从切换可以对业务方透明;
MySQL实例维护或者迁移可以对业务方透明(一键迁移);
MySQL业务扩容/缩容也对业务透明(一键扩缩容);
代理层上线推广到现在,已经有好几百套的MySQL集群跑在上面了,MySQL的高可用平台成功落地。
五、后记
Mongodb相对于MySQL的一个很大的优势就是高可用性,MySQL的高可用方案很多,但是完美的方式不多,代理层是在我们公司成功实施的一套平台,希望有机会能和业界一起探讨和学习,实现更多完美的解决方案。
代理层虽然已经在公司大规模使用,但是还有很多发展和改善的空间,随着MySQL 5.6和MySQL 5.7的广泛应用,GTID已经非常成熟,由于公司内部使用场景少,代理层的切换还没有实现GTID模式的切换,所以下一阶段,笔者会考虑实现基于GTID的高可用模式。