这学期有了汇编课,但个人感觉这部分难度还是有一些的,所以写了这篇当做自己对于知识的复习,同时也是希望能够再次加深理解,虽然汇编语言在当今用的比较少了,但是作为一名计算机专业的学生,我们还是应该有所了解的。
我的这篇文章分为三个部分
第一部分:通过看MASM的默认程序段,对一些基本概念略作了解
第二部分:通过解读一道例题,了解简单的汇编指令(个人感觉跟高级语言还是有一些差异的)
第三部分:总结一下编写汇编语言的大致思路
接下来进入第一部分
正如高级语言有自己的编译器一样,汇编语言也有自己的一个编程环境,目测是有几种不同的环境的。
我们学校课程选用的是MASM这个环境,我个人感觉还是不错的

首先打开编译器是这个样子的,这些都是默认的
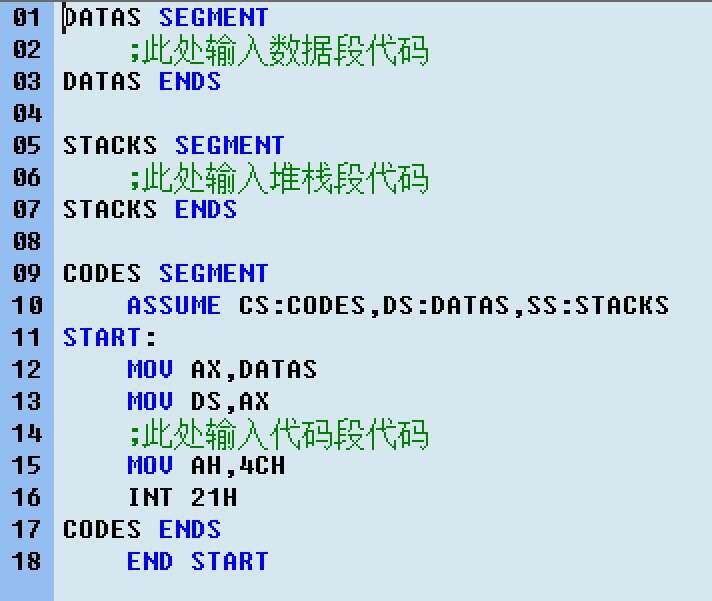
大致可以分成三个部分,data segment(数据段)、stacks segment(堆栈段)、codes segment(代码段)
一般如果我们的程序里需要有pop和push这类的指令,那么我们要先写堆栈段这部分(作为初学者就不用考虑这些了,先写上,反正也不会有什么错。。。)

这里面 db 128 dup(0)表示的意思是开辟128个字节大小(用db表示)的空间,每一个空间的初始为0(有一点C语言数组的味道。。。)
基本上每一个汇编程序一开始都是写这个,但是为什么要这么写,我个人认为作为初学者暂且可以不去探究,只需要记住每次写汇编之前,先写上这么一段,以及知道这一段是在开辟一段空间,这段空间是作为堆栈使用的就可以
stack segment stack
db 128 dup(0)
stack segment
堆栈段就到此为止了,接下来我们进入数据段的研究
数据段的初始是这个样子的,我们要在其中定义我们需要用的数据
DATAS SEGMENT
;此处输入数据段代码
DATAS ENDS
举个例子

比如下面这样
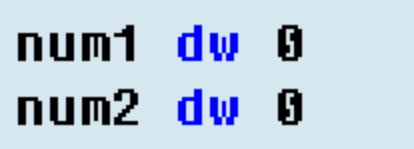
目前来说我作为一个没编过几个程序的新手,我见到的大部分数据定义格式都是这个样子的
变量名 变量类型 初始值
num1 db 0
这一句就表示定义一个叫num1的变量,这个变量是字节形的,也就是说在内存中为这个变量开辟一个8位的字节空间来保存这个变量的值
个人认为需要注意这几点
(a)变量名的定义不要和关键字冲突(比较好的方式就是每个变量都包含一个下划线,这样比较省事)
(b)变量类型不止db一种,还有有很多其他的,放一张网上的图

除了以上这种变量的定义方法,字符串变量的定义也是很常见的,格式如下
变量名 db(字符串只能用db) 字符串
我觉得对于初学者,有必要解释一下,这个字符串的定义在内存中是如何对应的
首先明确字符串由字符组成,字符包括字母、数字、一些特殊符号,还有空格,回车,换行等等
每一个字符都有一个0-63之间的数字与之对应,这个对应关系就是美国信息交换标准码(ASCII码)
接下来我们来梳理内存的对应关系,以上面这个定义为例
我个人目前的理解是,prompt1相当于是一个指针,这个指针指向的是这个字符串的第一个字符,在这里面就是‘p’,之后在内存中从低地址向高地址,依次放入‘l’、‘e’、‘a’、‘s’、‘e’........‘:’、‘$’
虽然我们在写的时候写的是字符,但是存在内存中存的就是字符对应的ASCII码值
由于一个存储单位是8位,所以存一个63以内的数字是绰绰有余的
这也就是为什么在定义字符串的时候都是用db,而不用dw之类的存储类型
我理解的就是为了尽可能的节约内存资源,毕竟就算计算机技术发展到了今天,内存资源也不是随随便便就可以浪费的。
还有一点需要关注的就是,整个字符串中的最后一个字符'$',这个是表示字符串的结尾,可以类比C语言字符串中的'/0'
上面我是用语言描述的方式表达了数据定义与内存之间的关系
接下来再用图来加深一下理解
首先是数据的
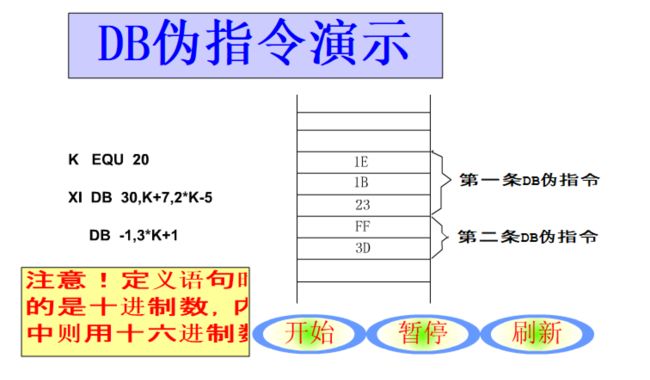
接下来是字符的

到此为止,已经进行了简单的数据段和堆栈段的定义方式,其中堆栈段的定义可以一开始就直接写上,但是数据段的定义往往是在编程的过程中逐步完善的。
接下来,我们要学习一个词MACRO
查查,有道词典,就知道这是一个厉害的词


“人如其名”,macro的功能也是强大的,接下来就学习一下汇编中的宏指令
先回答一个基本的问题
为什么要学习宏指令?
为了使程序更简洁呀!!!!
为什么会使程序简洁呢??(我暂且留一个伏笔,稍后再说)
我们先以一个程序为例,介绍一下汇编中如何利用DOS功能调用来输出一个字符串
比如说我们的目的是要输出字符串到dos命令行窗口中(小黑框),我们要用汇编完成,我们会怎么做呢
我们会用DOS的功能调用,因为DOS的功能表里有字符串输出功能
这个DOS功能的使用要求我们要把数值9放到ah寄存器(ax寄存器的高八位)中,补一句,在调用DOS功能时,AH寄存器中的值是用来区分调用哪一个DOS功能,9号就是字符串输出功能。
接下来呢,我们会这么写
lea dx, string(这个语句叫有效地址传送指令,在这句话里,它将string这个字符串的首地址,放到了dx这个16位的寄存器中)
这里注意了!!!!

lea这个指令的介绍如下

这个指令是很友爱的,因为指令对于oprd1和oprd2是没有特殊要求的,这里所说的特殊要求是对于oprd并没有指定只能使用哪一个寄存器,后面我们会看到有些指令对于操作数是有特殊要求的
但是!!!!
我们这一条指令是必须要把oprd1写成dx寄存器的
因为前面的DOS功能表告诉我们,9号功能会自动根据DS:DX找到字符串并输出
int 21h(这个语句先暂且理解为DOS的功能执行,更深入的理解个人认为暂且不需要,因为我们每次都是写这个。。。。。)
前面我们说了正常情况下输出一个字符串我们该怎么做(中间我们插入了lea指令的介绍),但是有些语句我们是要在一个程序里反反复复用到的,比如字符输入、字符输出、或者是字符串输入输出这些
为了避免麻烦,我们希望能够把这些功能打个包,想用的时候随时用,并且不用总是写那些重复的语句
这个包就是“宏(macro)”!!!!!
这个包就是“宏(macro)”!!!!!
这个包就是“宏(macro)”!!!!!
好,接下来我们就看一下,如何进行打包工作

打包大致就是定义一个宏的意思
定义宏的格式是

举个例子——输出字符串的“宏”
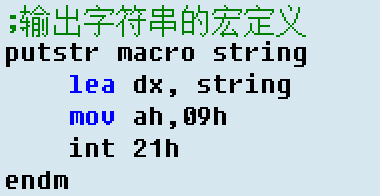
再举个栗子

输入字符的宏

原本是这个样子的
mov ah 1
int 21h
写成“宏”就是这个样子的

一般我们会把宏定义写在代码段之前,数据段之后,写在数据段之后是因为宏定义中会用到数据段定义的变量,比如string,写在代码段之前是因为代码段里会用到宏,所以需要事先定义
最后要说一下宏的缺点!!!!!
宏的缺点就是形参只能是字符串或者是字符,如果是其他类型的变量的话就要写成一个函数啦!!!!
接下来我们就要进入最为惊心动魄的code segment了!!!

在MASM汇编环境下,新建一个文件,其中code segemnt的部分是这样的

这里面有一些东西是写好的,我们不需要自己动手,但是还是要知道是什么意思,我个人认为这也对我们后续的编程是有帮助的。
比如assume CS:CODES,DS:DATAS,SS:STACKS
其中CS、DS、SS是段寄存器(其实还有一个ES段寄存器,这里用不上)
ASSUME CS:CODES,DS:DATAS,SS:STACKS
这句话表明CODES这个段从现在开始就被程序认为是段寄存器了,DATAS就被认为是数据段寄存器了、而STACKS就被认为是堆栈段寄存器了
或许我上面说的这些话有点儿像废话(其实我也觉得有点儿)。。。。。。。

但还是有一些含义的,以下是我个人的理解,仅供参考
上面这些代码表明:内存是客观的,但是对内存的使用是人为的
也就是说我可以定义一个段CODES给CS作为代码段
但是我如果高兴的话,我也可以定义一个HAPPY段,然后写CS:HAPPY(这是我个人理解,还没有试验过。。。。),但是无论是HAPPY还是CODES他们发挥的功能都是存储指令
接下来要解释一下那个start是什么意思,要想理解为什么我们每一次写代码段的时候都要写个start就要先理解,整个程序的最后那个END的含义。
END的含义表示程序的结束
格式就是 END 表达式(这里的表达式必须是程序段第一个可执行指令的地址。这个很重要)
为了能够得到这个地址,我们就要给程序第一个指令一个标号,这个标号的含义就是第一个指令的位置
接下来进入第二部分:解读一道例题,了解几个最基本的汇编指令
我以我的课内作业为例
题目如下:
求两个数的平方差,若是负数,要输出负号。要求:由键盘输入两整数a 、b,中间空格隔开;Enter 键结束输入,并换行显示结果。
按照我们前面说的,首先是一些无脑操作(在理解之后就可以无脑了)

第一步:堆栈段开辟,并赋初始值0
stack segment stack
db 128 dup(0)
stack ends
数据段先空着,宏定义这部分也先空着,后面根据需要再补(有需求,才有编程。。。)
我们先开始写代码段,先写上加粗的两句,这两句基本上也属于常规操作,基本所有程序的代码段上来都是这个(只是个人经验,其实总共也没编几道题。。。。)
CODES SEGMENT
ASSUME CS:CODES,DS:DATA,SS:STACKS
START:
MOV SS STACKS
MOV DS,DATAS
MOV AH,4CH//DOS功能,表示代码结束
INT 21H
CODES ENDS
END START
原因就是汇编是对寄存器的操作,寄存器一共有16个,而寄存器的种类是有划分的,其中段寄存器是用来存放段基址的(为什么会有这个概念是有历史原因的,个人认为可以暂且忽略,只需要知道段寄存器中的段基址是需要一开始就写好的)

通过看这张图,我们虽然不能掌握每一个寄存器的应用,但是我们可以知道CS和SS两个寄存器是很特殊的,他们叫段寄存器,是用来存放段基址的
但是到这里大体上的意思是对了,但是还有一点小问题
那就是MOV指令是不能把段名传给段寄存器的,所以需要改一下,先把段名(段基址)传给一个通用寄存器,再传给段寄存器
MOV AX STACKS
MOV SS AX
MOV AX DATAS
MOV DS,AX
接下来为了简洁美观,我们需要输出提示语,为了锻炼我们用宏的能力,我们就用宏来写输出提示语这一部分
首先是定义宏,宏的格式如下:
putstr(宏名) macro(宏关键词) string(传入的参数)
lea dx string//把字符串的首地址传入9号功能指定的寄存器 ,这里的string是形式参数(这个lea指令前面说过,英文源于LOAD EFFECT ADDRESS)
mov ah 09h//这里要调用dos的输出字符串功能,是9号功能
int 21h
接下里就是在代码段里调用宏
CODES SEGMENT
ASSUME CS:CODES,DS:DATAS,SS:STACKS
START:
MOV AX STACKS
MOV SS AX
MOV AX DATAS
MOV DS,AX
putstr prompt1//注意这里的prompt1是实际参数,而这个实际参数是需要用前面介绍的数据段定义字符串的方式来定义的
MOV AH,4CH//DOS功能,表示代码结束
INT 21H
CODES ENDS
END START
接下来按照程序的需求,该从控制台读入数字了
虽然我们说是从控制台读数字,但实际上读的是字符串,而字符串是按照ASCII码存的,也就是说内存中实际上存的是ASCII码,所以我们需要把读入的字符ASCII变为数值(这点看看ASCII表就知道是要把数字字符对应的ASCII减去48就可以了,但是汇编中记得用16进制哟!!所以是30h)
这是一个经常要做的事,所以写成一个函数(为什么不写成一个宏?答:这是由前面说过的宏只能传入字符串的局限所导致的),函数的功能就是传入字符,可以得到相应的数值,以后直接调用即可
函数(汇编叫过程,从关键字proc(procedure就可以看出来))的标准格式是

接下来是具体的代码,在这一部分只解释代码含义,不探讨编程思维(也就是为什么这么写的问题)
transform1(过程名) proc(这是关键字)
mov neg_flag,0//neg_flag是符号标记(数据段要定义),规定0为正1为负,初始neg_flag为0,相当于是先默认为正数
可以跳过多余的空格,具体的操作就是利用循环,跳过空格
skip_space://这是程序段的标号(标号我理解的就是一个类似于索引的东西,汇编可以很神奇地通过程序中的标号找到标号对应程序的位置),用于跳转,可以跳过多余的空格,具体的操作就是利用循环,跳过空格
getchar//由于经常使用,所以定义一个宏,所以要定义一个宏,作用就是利用DOS功能01把输入的字符对应的ASCII码值放到AL寄存器中
cmp al, ' ' ;//又是一个新指令,指令的作用就是通过前一个操作数减去后一个操作数,之后根据运算结果改变标志位
je skip_space ;//又是一个新指令,这个指令英文:judge equal,原理就是看上一条指令运算结果对于标志位的改变,借此来判断al是不是空格

这张图没有任何含义,我只是有点累了。。。。不想写了。。。。。
在进入下面这些语句的时候,AL中已经有了值了,要么是数据,要么是负号,反正不是空格。。。
cmp al, '-';判断有没有负号,跟空格的判断一样
jne next1;新指令(其实也不新,就是judge unequal,类比judge equal)若不相等,那么就是正数,那么标志位ZF=0,跳转到next1标号位置
mov neg_flag,1 ;这里是负数的标记,如果上一条指令成立,那么不会走到这条指令,如果走到这里了,那就说明是负数,于是就是neg_flag=1
getchar;获取字符,此时应该就是负数的数字了
next1:
mov di, 0 ;di来保存换成的数值,di本身是目的地址寄存器,但由于属于通用寄存器,所以也可以用来存数据,注意此时的di是一个16位的寄存器,这一点对于后面的程序是有影响的
input_loop:看这个样子就知道是一个用于循环的程序标号
sub al, 30h; (0-9)asc码转 数值,我们以3为例
mov cl, al ; 转出的数值保存到cl(8位寄存器到8位寄存器),此时cl=3,al=3
mov ax, di; 此时ax=0,注意上一行al=3,但此时ax=0使得al也等于0了,因为ax中包含al
mov bx, 10;bx=10
mul bx ;又是一条新指令,mul做的是无符号的乘法,具体操作要看操作数是字还是字节,如果操作数是字节操作数,则把AL中的无符号数与SRC相乘得到16位结果送AX中,即:AX←(AL)*(SRC)。如果SRC是字操作数,则把AX中的无符号数与SRC相乘得到32位结果送DX和AX中,DX存高16位,AX存低16位,我们这里是字操作数所以结果存到了DX:AX两个寄存器中,此时DX、AX都是零
mov ch,0;让ch(8位寄存器为)为0
add ax, cx ;之前的di的数值+ 转后的数值,此时ax结果为3
mov di, ax ;保存结果到di,此时di=3,ax=3
getchar;接着获取字符,字符的ASCII放到AL中
cmp al,0dh ;遇到回车,认为输入完一个整数,在这部分由于DOS功能默认选择AL寄存器为输入字符的存储位置,因此破坏了之前AX=3
je int_quit
cmp al,' ' ;遇到空格
je int_quit
jmp input_loop;相当于是无条件的跳转
int_quit:
mov ax,di ;save di to ax,这里恢复之前由DOS功能导致的AX值的改变,让AX重新为结果3(这就告诉我们如果我们想要把AX作为结果,那么中间一旦使用DOS的某些功能就一定要把AX中的值先进行保护,这里我们用的是di进行了保护)
mov bx, neg_flag;把符号标记给bx
cmp bx, 1;看bx是否为正数
jne LN;若不是正数,跳到LN
neg ax ;又是新指令,但并不复杂,就是取反而已,放在负数的判断之后
LN:
ret
transform2
endp
注意
(1)在这个过程中要注意对于寄存器高低位的使用,Ax=AH与AL拼接,所以即便AL之前有值,如果之后对AX赋值0,那么AL也将是0
(2)MUL这个指令做的是无符号的乘法,所以是绝对值相乘,结果都是正数,如果是负数的话,之后要再用neg取反
现在通过这个函数,数值3已经放到了AX里了,同理,再调用一次另外一个数值,暂且定为4,也可以得到,由于两次都是放在AX中,所以一定要定义其他的变量,以便保存数据
call transform1
mov num1, ax第一个数
call transform1
mov num2, ax第二个数
mov ax, num1由于后面要做平方,所以有一个数必须放到AX里,另外一个数可以随便放
mov bx, num1此时放到了BX里
mul bx无符号乘法,字操作数,所以结果放到DX:AX中
mov square_num1, ax但是在这里我们只取AX中的数据,这就造成了超出一定的范围之后,结果会错误,不过100以内的演示是没有问题的
mov ax, num2
mov bx, num2
mul bx
mov square_num2, ax
mov ax, square_num1
sub ax, square_num2
现在我们已经得到了结果了,接下来是把这个结果显示到屏幕上,显示的是字符,所以我们要把结果的数值变为对应的ASCII值
为了让主程序简洁,所以我们就再写一个函数
;整数值转asc码
transform2 proc
cmp ax, 0
jge LW;新的一条指令,当大于等于时转移
neg ax ;如果是负数,转成正数
putchar '-' ;调用宏输出负号标记
LW:
mov cx, 0; cx清零待用,功能是看数直结果需要几个字符来表示
cal_loop:一看就是循环用的标号
mov dx,0 ;dx清0,准备除法
mov bx,10
div bx ;整数除以10,div指令是无符号除法,分为字节型与字型两种,具体用哪一种取决于div reg中reg这个寄存器的位数,其中字节除法的结果商在al中,余数在ah中,字除法商在ax中,余数在dx中,所以当前这句话的余数在dx中
push dx ;余数dx入栈
inc cx ;新指令,就是相当于i++,是一个自加的指令,指令每运行一次cx加一计,算需要几位asc2码 (前面清零是为了这里用)
cmp ax,0
jne cal_loop;只要ax不等于0,就一直取出余数
show_loop:
pop dx ;取出余数
add dl,30h; '0'把余数的数值对应的ASCII码算出来
putchar dl 调用宏打印字符
loop show_loop;新指令,很重要,是循环语句的重要部分,之前我们的那种跳转循环是利用自己的cmp指令来控制的(相当于while),而现在可以用cx的计数来控制(相当于for循环),loop每循环一次cx就会减一,当cx=0时,循环结束跳出
ret
WriteInt
endp
最后是主函数
mov ax, stack
mov ss, ax
mov ax, data
mov ds, ax
putstr prompt1
;输入第一个数
call transform1
mov num1, ax
;输入第2个数
call transform1
mov num2, ax
mov ax, num1
mov bx, num1
mul bx
mov square_num1, ax
mov ax, num2
mov bx, num2
mul bx
mov square_num2, ax
mov ax, square_num1
sub ax, square_num2
call transform2
mov ah, 4ch ;返回dos
int 21h
到此我们把所有重要的部分都过了一遍了,代码我基本也把注释写清楚了,只要自己找两个数据自己人肉编译一下,基本就理解了。
接下来是最后一部分,大致理解一下汇编思路
一般来说一个程序需求我们都是可以理解的,我感觉难点在于如何用汇编语言描述,这次这个例题中如何将一个字符,转为对应的数值比较难的,看似一个减48的操作并不难,但是由于要处理正负号、回车、空格的问题导致有些寄存器中的数据需要被保护,进而增加了程序的复杂性,所以在汇编中要时刻保持对于寄存器的敏锐,时刻关注指令对于寄存器的影响(尤其是那些有默认寄存器的指令比如mul,甚至是DOS功能下的默认寄存器使用都是需要注意的)
2018.5.8补
前面所写的这些在正确性上或许会有不严谨甚至是有疏漏的地方,后续我还会再查一遍
今天想说的是,之前有几点我没有注意到,今天在我汇编老师的指导下才注意到
(1)程序中缺少“边界限制”,这个限制指的就是对于用户不合法的输出,程序应该能够处理
举个例子:
比如明明应该输入0-9的字符,结果输入了一个‘#’,这个时候程序应该给出一定的反馈,比如
input error这种提示语,并且让用户重新输入才行
(2)第二个就是要通过测试来发现自己程序的缺陷,并且最好改正过来
举例
比如你的程序只能输出单一字符,不能输出12 345这种,那我最好就要考虑如何解决这个问题(千万不要只是完成功能就完了,那样不太好。。。)