本次分享主题
pika 是360 DBA和基础架构组联合开发的类redis 存储系统, 完全支持Redis协议,用户不需要修改任何代码, 就可以将服务迁移至pika. 有维护redis 经验的DBA 维护pika 不需要学习成本
pika 主要解决的是用户使用redis的内存大小超过50G, 80G 等等这样的情况, 会遇到比如启动恢复时间长, 一主多从代价大, 硬件成本贵, 缓冲区容易写满等等问题. pika 就下针对这些场景的一个解决方案
pika 目前已经开源, github地址:
https://github.com/Qihoo360/pika
重点:
- pika 的单线程的性能肯定不如redis, pika是多线程的结构, 因此在线程数比较多的情况下, 某些数据结构的性能可以优于redis
- pika 肯定不是完全优于redis 的方案, 只是在某些场景下面更适合. 所以目前公司内部redis, pika 是共同存在的方案, DBA会根据业务的场景挑选合适的方案
本次分享分成4个部分
- 大容量redis 容易遇到的问题
- pika 整体架构
- pika 具体实现
- pika vs redis
背景
redis 提供了丰富的多数据结构的接口, 在redis 之前, 比如memcache 都认为后端只需要存储kv的结构就可以, 不需要感知这个value 里面的内容. 用户需要使用的话通过json_encode, json_decode 等形式进行数据的读取就行. 但是其实redis 类似做了一个微创新, redis 提供了多数据结构的支持, 让前端写代码起来更加的方便了
因此redis 在公司的使用率也是越来越广泛, 用户不知不觉把越来越多的数据存储在redis中, 随着用户的使用, DBA 发现有些redis 实例的大小也是越来越大. 在redis 实例内存使用比较大的情况下, 遇到的问题也会越来越多, 因此DBA和我们一起实现了大容量redis 的解决方案
最近半年公司每天redis 的访问情况

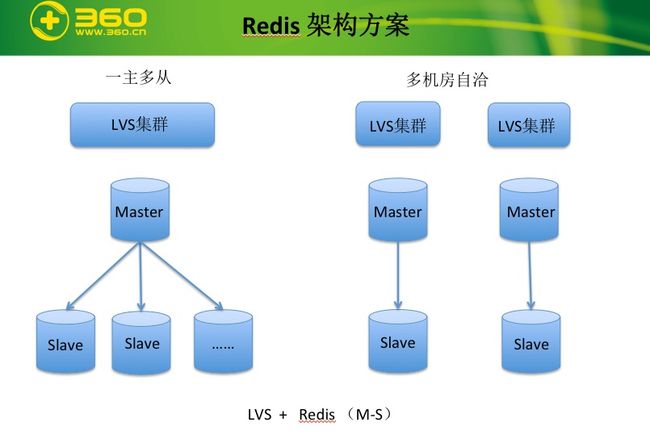
redis 架构方案
大容量redis 遇到的问题
- 恢复时间长
我们线上的redis 一般同时开启rdb 和 aof.
我们知道aof的作用是实时的记录用户的写入操作, rdb 是redis 某一时刻数据的完整快照. 那么恢复的时候一般是通过 rdb + aof 的方式进行恢复, 根据我们线上的情况 50G redis 恢复时间需要差不多70分钟
- 一主多从, 主从切换代价大
redis 在主库挂掉以后, 从库升级为新的主库. 那么切换主库以后, 所有的从库都需要跟新主做一次全同步, 全量同步一次大容量的redis, 代价非常大.
- 缓冲区写满问题
为了防止同步缓冲区被复写,dba给redis设置了2G的巨大同步缓冲区,这对于内存资源来讲代价很大. 当由于机房之间网络有故障, 主从同步出现延迟了大于2G以后, 就会触发全同步的过程. 如果多个从库同时触发全同步的过程, 那么很容易就将主库给拖死
- 内存太贵
我们一般线上使用的redis 机器是 64G, 96G. 我们只会使用80% 的空间.
如果一个redis 的实例是50G, 那么基本一台机器只能运行一个redis 实例. 因此特别的浪费资源
总结: 可以看到在redis 比较小的情况下, 这些问题都不是问题, 但是当redis 容量上去以后. 很多操作需要的时间也就越来越长了
pika 整体架构
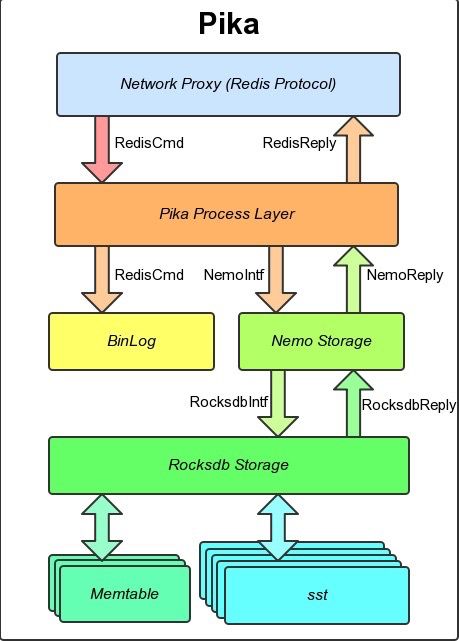
主要组成:
- 网络模块 pink
- 线程模块
- 存储引擎 nemo
- 日志模块 binlog
pink 网络模块
- 基础架构团队开发网络编程库, 支持pb, redis等等协议. 对网络编程的封装, 用户实现一个高性能的server 只需要实现对应的DealMessage() 函数即可
- 支持单线程模型, 多线程worker模型
- github 地址: https://github.com/baotiao/pink
线程模块
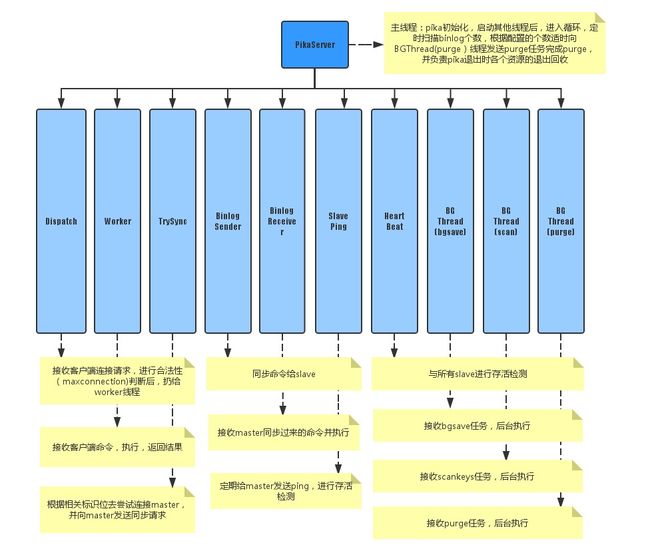
pika 基于pink 对线程进行封装. 使用多个工作线程来进行读写操作,由底层nemo引擎来保证线程安全,线程分为11种:
PikaServer:主线程
DispatchThread:监听端口1个端口,接收用户连接请求
ClientWorker:存在多个(用户配置),每个线程里有若干个用户客户端的连接,负责接收处理用户命令并返回结果,每个线程执行写命令后,追加到binlog中
Trysync:尝试与master建立首次连接,并在以后出现故障后发起重连
ReplicaSender:存在多个(动态创建销毁,本master节点挂多少个slave节点就有多少个),每个线程根据slave节点发来的同步偏移量,从binlog指定的偏移开始实时同步命令给slave节点
ReplicaReceiver:存在1个(动态创建销毁,一个slave节点同时只能有一个master),将用户指定或当前的偏移量发送给master节点并开始接收执行master实时发来的同步命令,在本地使用和master完全一致的偏移量来追加binlog
SlavePing:slave用来向master发送心跳进行存活检测
HeartBeat:master用来接收所有slave发送来的心跳并恢复进行存活检测
bgsave:后台dump线程
scan:后台扫描keyspace线程
purge:后台删除binlog线程
存储引擎 nemo
- Pika 的存储引擎, 基于Rocksdb 修改. 封装Hash, List, Set, Zset等数据结构
我们知道redis 是需要支持多数据结构的, 而rocksdb 只是一个kv的接口, 那么我们如何实现的呢?
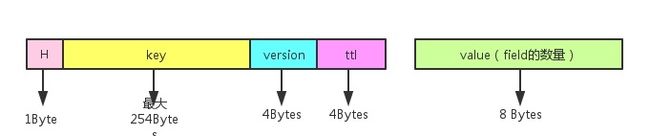
比如对于Hash 数据结构:
对于每一个Hash存储,它包括hash键(key),hash键下的域名(field)和存储的值 (value).
nemo的存储方式是将key和field组合成为一个新的key,将这个新生成的key与所要存储的value组成最终落盘的kv键值对。同时,对于每一个hash键,nemo还为它添加了一个存储元信息的落盘kv,它保存的是对应hash键下的所有域值对的个数。
每个hash键、field、value到落盘kv的映射转换

每个hash键的元信息的落盘kv的存储格式
比如对于List 数据结构:
顾名思义,每个List结构的底层存储也是采用链表结构来完成的。对于每个List键,它的每个元素都落盘为一个kv键值对,作为一个链表的一个节点,称为元素节点。和hash一样,每个List键也拥有自己的元信息。
每个元素节点对应的落盘kv存储格式

每个元信息的落盘kv的存储格式

其他的数据结构实现的方式也类似, 通过将hash_filed 拼成一个key, 存储到支持kv的rocksdb 里面去. 从而实现多数据结构的结构
日志模块 binlog
Pika的主从同步是使用Binlog来完成的.
binlog 本质是顺序写文件, 通过Index + offset 进行同步点检查.
解决了同步缓冲区太小的问题
支持全同步 + 增量同步
master 执行完一条写命令就将命令追加到Binlog中,ReplicaSender将这条命令从Binlog中读出来发送给slave,slave的ReplicaReceiver收到该命令,执行,并追加到自己的Binlog中.
当发生主从切换以后, slave仅需要将自己当前的Binlog Index + offset 发送给master,master找到后从该偏移量开始同步后续命令
为了防止读文件中写错一个字节则导致整个文件不可用,所以pika采用了类似leveldb log的格式来进行存储,具体如下:
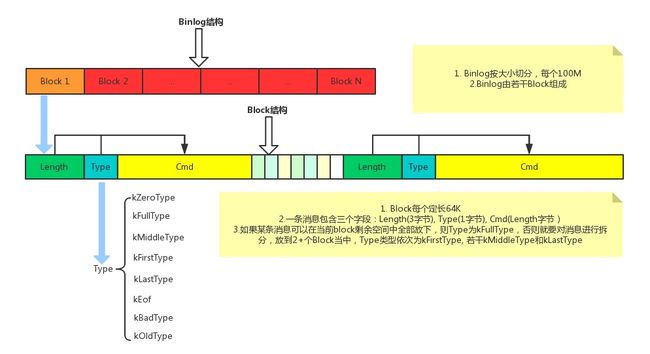
主要功能
pika 线上架构

主从架构
旁白: 为了减少用户的学习成本, 目前pika 的主从同步功能是和redis完全一样, 只需要slaveof 就可以实现主从关系的建立, 使用起来非常方便
背景
- Pika Replicate
pika支持master/slave的复制方式,通过slave端的slaveof命令激发
salve端处理slaveof命令,将当前状态变为slave,改变连接状态
slave的trysync线程向master发起trysync,同时将要同步点传给master
master处理trysync命令,发起对slave的同步过程,从同步点开始顺序发送binlog或进行全同步
- Binlog
pika同步依赖binlog
binlog文件会自动或手动删除
当同步点对应的binlog文件不存在时,需要通过全同步进行数据同步
全同步
-
简介
需要进行全同步时,master会将db文件dump后发送给slave
通过rsync的deamon模式实现db文件的传输 -
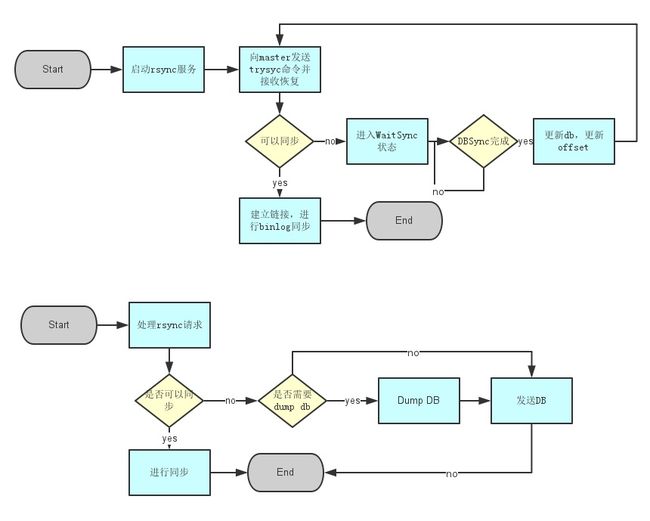
实现逻辑
slave在trysnc前启动rsync进程启动rsync服务
master发现需要全同步时,判断是否有备份文件可用,如果没有先dump一份
master通过rsync向slave发送dump出的文件
slave用收到的文件替换自己的db
slave用最新的偏移量再次发起trysnc
完成同步
-
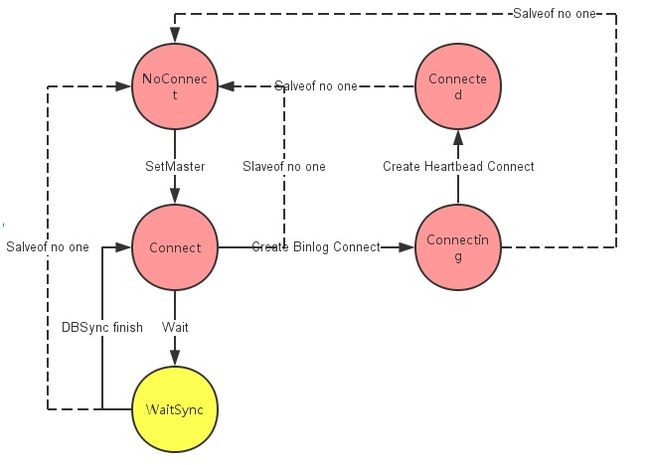
Slave连接状态
No Connect:不尝试成为任何其他节点的slave
Connect:Slaveof后尝试成为某个节点的slave,发送trysnc命令和同步点
Connecting:收到master回复可以slaveof,尝试跟master建立心跳
Connected: 心跳建立成功
WaitSync:不断检测是否DBSync完成,完成后更新DB并发起新的slaveof
主从命令同步

上图1是一个主从同步的一个过程(即根据主节点数据库的操作日志,将主节点数据库的改变过程顺序的映射到从节点的数据库上),从图1中可以看出,每一个从节点在主节点下都有一个唯一对应的BinlogSenderThread。
(为了说明方便,我们定一个“同步命令”的概念,即会改变数据库的命令,如set,hset,lpush等,而get,hget,lindex则不是)
主要模块的功能:
WorkerThread:接受和处理用户的命令;
BinlogSenderThread:负责顺序地向对应的从节点发送在需要同步的命令;
BinlogReceiverModule: 负责接受主节点发送过来的同步命令
Binglog:用于顺序的记录需要同步的命令
主要的工作过程:
1.当WorkerThread接收到客户端的命令,按照执行顺序,添加到Binlog里;
2.BinglogSenderThread判断它所负责的从节点在主节点的Binlog里是否有需要同步的命令,若有则发送给从节点;
3.BinglogReceiverModule模块则做以下三件事情:
a. 接收主节点的BinlogSenderThread发送过来的同步命令;
b. 把接收到的命令应用到本地的数据上;
c. 把接收到的命令添加到本地Binlog里
至此,一条命令从主节点到从节点的同步过程完成
BinLogReceiverModule的工作过程:
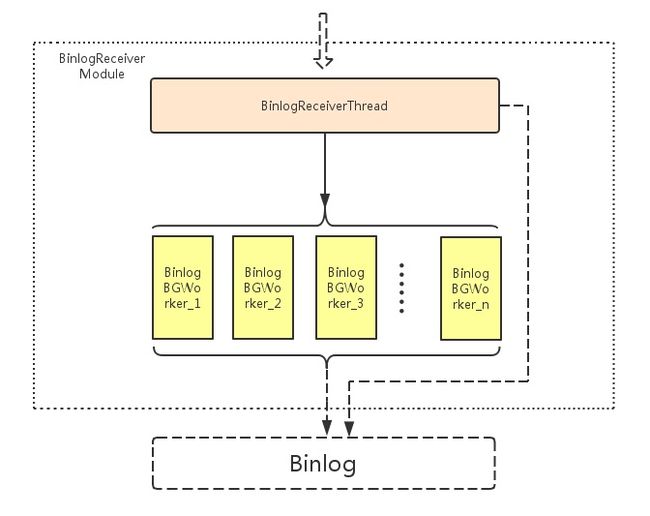
上图2是BinLogReceiverModule(在源代码中没有这个对象,这里是为了说明方便,抽象出来的)的组成,从图2中可以看出BinlogReceiverModule由一个BinlogReceiverThread和多个BinlogBGWorker组成。
BinlogReceiverThread: 负责接受由主节点传送过来的命令,并分发给各个BinlogBGWorker,若当前的节点是只读状态(不能接受客户端的同步命令),则在这个阶段写Binlog
BinlogBGWorker:负责执行同步命令;若该节点不是只读状态(还能接受客户端的同步命令),则在这个阶段写Binlog(在命令执行之前写)
BinlogReceiverThread接收到一个同步命令后,它会给这个命令赋予一个唯一的序列号(这个序列号是递增的),并把它分发给一个BinlogBGWorker;而各个BinlogBGWorker则会根据各个命令的所对应的序列号的顺序来执行各个命令,这样也就保证了命令执行的顺序和主节点执行的顺序一致了
之所以这么设计主要原因是:
a. 配备多个BinlogBGWorker是可以提高主从同步的效率,减少主从同步的滞后延迟;
b. 让BinlogBGWorker在执行执行之前写Binlog可以提高命令执行的并行度;
c. 在当前节点是非只读状态,让BinglogReceiverThread来写Binlog,是为了让Binglog里保存的命令顺序和命令的执行顺序保持一致;
数据备份
不同于Redis,Pika的数据主要存储在磁盘中,这就使得其在做数据备份时有天然的优势,可以直接通过文件拷贝实现
流程:
打快照:阻写,并在这个过程中或的快照内容
异步线程拷贝文件:通过修改Rocksdb提供的BackupEngine拷贝快照中文件,这个过程中会阻止文件的删除
快照内容
当前db的所有文件名
manifest文件大小
sequence_number
同步点: binlog index + offset

秒删大量的key
在我们大量的使用场景中. 对于Hash, zset, set, list这几种多数据机构,当member或者field很多的时候,用户有批量删除某一个key的需求, 那么这个时候实际删除的就是rocksdb 底下大量的kv结构, 如果只是单纯暴力的进行删key操作, 那时间肯定非常的慢, 难以接受. 那我们如何快速删除key?
刚才的nemo 的实现里面我们可以看到, 我们在value 里面增加了version, ttl 字段, 这两个字段就是做这个事情.
Solution 0:暴力删除每一个member,时间复杂度O(m) , m是member的个数;
优点:易实现;
缺点:同步处理,会阻碍请求;
Solution 1: 启动后台线程,维护删除队列,执行删除,时间复杂度O(m)
优点:不会明显阻住server;
缺点:仍然要O(m)去删除members,可以优化删除的速度;
Redis 是怎么做的?
旧版本的Del接口,在实际free大量内存的时候仍然会阻塞server;
新版增加了lazy free,根据当前server的负载,多次动态free;
Solution 2: 不删除, 只做标记, 时间复杂度O(1)
优点:效率就够了;
缺点:需要改动下层rocksdb,一定程度破坏了rocksdb的封装,各个模块之间耦合起来;
方案:
Key的元信息增加版本,表示当前key的有效版本;
操作:
Put:查询key的最新版本,后缀到val;
Get:查询key的最新版本,过滤最新的数据;
Iterator: 迭代时,查询key的版本,过滤旧版本数据;
Compact:数据的实际删除是在Compact过程中,根据版本信息过滤;
目前nemo 采用的就是第二种, 通过对rocksdb 的修改, 可以实现秒删的功能, 后续通过修改rocksdb compact的实现, 在compact 的过程中, 将历史的数据淘汰掉
数据compact 策略
rocksdb 的compact 策略是在写放大, 读放大, 空间放大的权衡.
那么我们DBA经常会存在需求尽可能减少空间的使用, 因此DBA希望能够随时触发手动compact, 而又尽可能的不影响线上的使用, 而rocksdb 默认的手动compact 策略是最高优先级的, 会阻塞线上的正常流程的合并.
rocksdb 默认的 manual compact 的限制
a) 当manual compact执行时,会等待所有的自动compact任务结束, 然后才会执行本次manual compact;
b) manual执行期间,自动compact无法执行
- 当manual执行很长时间,无法执行自动compact,导致线上新的写请求只能在memtable中;
- 当memtable个数超过设置的level0_slowdown_writes_trigger(默认20),写请求会出被sleep;
- 再严重一些,当超过level0_stop_writes_trigger(默认24),完全停写;
为了避免这种情况,我们对compact的策略进行调整,使得自动compact一直优先执行,避免停写;
总结:
- 恢复时间长
pika 的存储引擎是nemo, nemo 使用的是rocksdb, 我们知道 rocksdb 启动不需要加载全部数据, 只需要加载几M的log 文件就可以启动, 因此恢复时间非常快 - 一主多从, 主从切换代价大
在主从切换的时候, 新主确定以后, 从库会用当前的偏移量尝试与新主做一次部分同步, 如果部分同步不成功才做全同步. 这样尽可能的减少全同步次数 - 缓冲区写满问题
pika 不适用内存buffer 进行数据同步, pika 的主从同步的操作记录在本地的binlog 上, binlog 会随着操作的增长进行rotate操作. 因此不会出现把缓冲区写满的问题 - 内存昂贵问题
pika 的存储引擎nemo 使用的是rocksdb, rocksdb 和同时使用内存和磁盘减少对内存的依赖. 同时我们尽可能使用SSD盘来存放数据, 尽可能跟上redis 的性能.
pika vs redis
pika相对于redis,最大的不同就是pika是持久化存储,数据存在磁盘上,而redis是内存存储,由此不同也给pika带来了相对于redis的优势和劣势
优势:
- 容量大:Pika没有Redis的内存限制, 最大使用空间等于磁盘空间的大小
- 加载db速度快:Pika 在写入的时候, 数据是落盘的, 所以即使节点挂了, 不需要rbd或者aof,pika 重启不用重新加载数据到内存而是直接使用已经持久化在磁盘上的数据, 不需要任何数据回放操作,这大大降低了重启成本。
- 备份速度快:Pika备份的速度大致等同于cp的速度(拷贝数据文件后还有一个快照的恢复过程,会花费一些时间),这样在对于百G大库的备份是快捷的,更快的备份速度更好的解决了主从的全同步问题
劣势:
由于Pika是基于内存和文件来存放数据, 所以性能肯定比Redis低一些, 但是我们一般使用SSD盘来存放数据, 尽可能跟上Redis的性能。
总结:
从以上的对比可以看出, 如果你的业务场景的数据比较大,Redis 很难支撑, 比如大于50G,或者你的数据很重要,不允许断电丢失,那么使用Pika 就可以解决你的问题。
而在实际使用中,大多数场景下pika的性能大约是Redis的50%~80%,在某些特定场景下,例如range 500,pika的性能只有redis的20%,针对这些场景我们仍然在改进
在360内部使用情况:
粗略的统计如下:
当前每天承载的总请求量超过100亿, 实例数超过100个
当前承载的数据总量约3 TB
性能对比
Server Info:
CPU: 24 Cores, Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz
MEM: 165157944 kB
OS: CentOS release 6.2 (Final)
NETWORK CARD: Intel Corporation I350 Gigabit Network Connection
测试过程, 在pika 中先写入150G 大小的数据. 写入Hash key 50个, field 1千万级别.
redis 写入5G 大小的数据
Pika:
18个线程
redis:
单线程
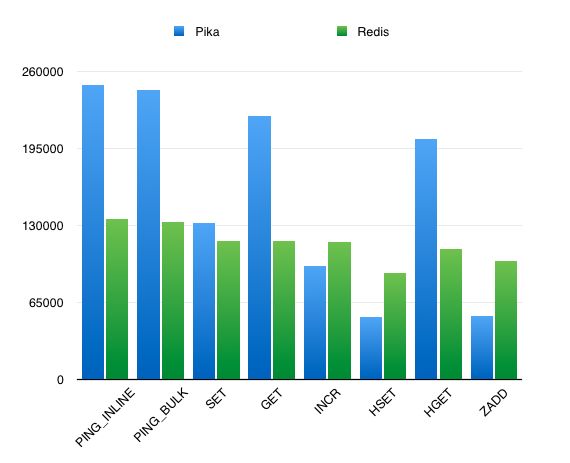
结论: pika 的单线程的性能肯定不如redis, pika是多线程的结构, 因此在线程数比较多的情况下, 某些数据结构的性能可以优于redis
wiki
github 地址:
https://github.com/Qihoo360/pika
github wiki:
https://github.com/Qihoo360/pika/wiki/pika介绍
FAQ
- 如果我们想使用新DB, 那核心问题是如何进行数据迁移. 从redis迁移到pika需要经过几个步骤?
开发需要做的:
开发不需要做任何事,不用改代码、不用替换driver(pika使用原生redis的driver),什么都不用动,看dba干活就好
dba需要做的:
1.dba迁移redis数据到pika
2.dba将redis的数据实时同步到pika,确保redis与pika的数据始终一致
3.dba切换lvs后端ip,由pika替换redis
迁移过程中需要停业务/业务会受到影响吗:
然而并不会
迁移是无缝且温和的吗:
那当然
- 这个和你们公司内部的bada 有什么区别?
我们之前在bada 上面支持过redis 的多数据结构, 并且兼容redis协议, 但是遇到了问题.
在分布式系统里面, 对key 的hash 场景的通常是两种方案:
- 以BigTable 为代表的, 支持range key 的hash 方案. 这个方案的好处是可以实现动态的扩展
- 以Dynamo 为代表的, 取模的hash 方案. 这个方案的好处是时间简单
我们bada 目前支持的是取模的hash 方案, 在实现redis 的多数据结构的时候, 比如hash 我们采用key取模找到对应的分片. 那么这样带来的问题是由于多数据结构里面key 不多, field 比较多的场景还是大部分的情况, 因此极容易照成分片的不均匀, 性能退化很明显.
- 为什么pika 使用多线程而不是像redis 单线程的结构
因为redis 所有的操作都是对于内存的操作, 因此理论上redis 的每次操作的时间都不会太长, 因此多线程就可以满足需求. 而pika 由于涉及到磁盘IO, 你们操作的时间就会长一点, 而且IO操作的时间是不均匀的, 因此多线程的效果会更好一些
360基础架构组公众号:
