数据下载
提取密码:reaj
在MySQL主要操作有
- 查询select(重点)
- 条件查找(重点)
- 分组和聚合group by(重点)
- 函数(了解,可以现查)
- 子查询(重点)
- 表联结join(重点)
- 存储过程(了解)
- 索引操作(重点)
- 增删查改(了解)
- 查询优化(重点)
一、查询select
1、通过select ...from ...可以查看表内各列内容,*是指所有列
SELECT * FROM data.company;

2、使用 limit表示显示多少行的数据
SELECT positionId,city FROM data.dataanalyst
limit 3;
3、使用 order by升序排列
SELECT * FROM data.dataanalyst
order by positionId
limit 10
4、使用 order by desc降序排列
SELECT * FROM data.dataanalyst
order by positionId desc;

二、条件查找
1、过滤使用where
SELECT * FROM data.dataanalyst
where companyId=4184;
2、对中文过滤要加双引号 " "
SELECT * FROM data.dataanalyst
where city="杭州";
3、区间过滤使用>、<、between and
SELECT * FROM data.dataanalyst
where companyId between 20 and 60;
4、多选使用 in()
SELECT * FROM data.dataanalyst
where companyId in(53,101);
5、排除用 <>或者 !=或者 not in()
SELECT * FROM data.dataanalyst
where city !="北京";
6、多条件并列查找 “且”使用where and
SELECT * FROM data.dataanalyst
where city !="北京"
and education="本科";
7、“或”使用or,and优先级高于or
SELECT * FROM data.dataanalyst
where city !="北京"
and positionId=148830
or companyId=70;

8、模糊过滤查找使用 like以及 %代表省略部分,相反是not like
SELECT * FROM data.dataanalyst
where secondType like '%开发';
9、 mysql中空值null和空字符' '是不同的,空值不等于空字符。判断NULL用is null 或者 is not null。 sql语句里可以用ifnull函数来处理。判断空字符串' ',要用 ='' 或者 <>''。空字符串之间可以比较,空值之间无法比较。
也就是说统计满足条件为a=b或者a<>b时的个数时,只要a或者b中包含null就无法统计在内。所以排除掉a=b剩下部分所对应的条件应该是:
where a<>b or a is null or b is null
三、分组
group by分组,功能类似数据透视表。
1.计数:统计各个分组中有多少项
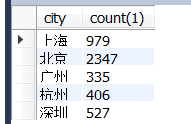
SELECT city,count(city) FROM data.dataanalyst
group by city;
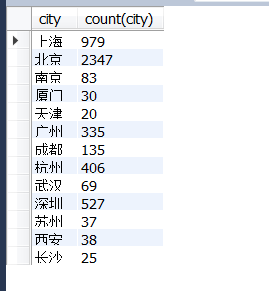
另外, count( * )、count(1)是对不为null的行进行计数,因此某一行只要不是所有列都为null(即只要是存在的记录),就会被计数。
count(field)是对field列不为null的行进行统计,因此某一行的该列为null,则不予计数 。若改field为主键,三者等价
2.不重复计数使用 count(distinct )
SELECT city,count(positionId),count(distinct companyId) FROM data.dataanalyst
group by city;

3.多分类计数:
SELECT city,education,count(1) FROM data.dataanalyst
group by 1,2;

4.having-针对分组后结果的过滤
SELECT city,count(1) FROM data.dataanalyst
group by city
having count(positionId)>=100;
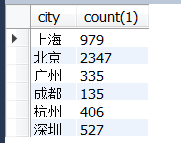
5.用嵌套函数if()代替where语句
SELECT city,count(1) FROM data.dataanalyst
group by city
having count(if(industryField like '%电子商务%',1,null))>=50;
等价于
SELECT city,count(1) FROM data.dataanalyst
where industryField like '%电子商务%'
group by city
having count(positionId)>=50;
四、函数
详细参数可以参考:
http://www.cnblogs.com/kissdodog/p/4168721.html
截取函数left/right/locate/substr/length
left(salary,locate('k',salary)), 返回截取
locate('-',salary), 返回位置
length(salary) 返回长度
substr(salary,开始位置,截取长度) 返回截取
avg()平均数
max()最大值
year()时间函数返回年
now()返回现在时间
monthname()返回月份
SELECT
left(salary,locate('k',salary)-1) as min,
substr(salary,locate('-',salary)+1,length(salary)-locate('-',salary)-1) as max,
salary FROM data.dataanalyst;

五、子查询
即select的嵌套结构
1.构造子查询
select (min+max)/2 as average,salary from
(SELECT
left(salary,locate('k',salary)-1) as min,
substr(salary,locate('-',salary)+1,length(salary)-locate('-',salary)-1) as max,
salary FROM data.dataanalyst)as t

SELECT * FROM data.dataanalyst
where average=(select max(average) from data.dataanalyst)
查询表中平均最大的信息
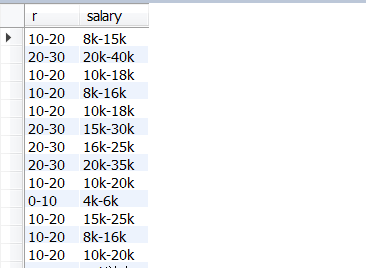
2.使用case分层
group by 与case区别是:group by分类汇总结果,只显示到类;case是分层,显示每一条的层情况
select
case
when (max+min)/2<=10 then '0-10'
when (max+min)/2<=20 then '10-20'
when (max+min)/2<=30 then '20-30'
else '30+'
end as r,
salary from
(SELECT
left(salary,locate('k',salary)-1) as min,
substr(salary,locate('-',salary)+1,length(salary)-locate('-',salary)-1) as max,
salary FROM data.dataanalyst)as t
3.子查询作为where的条件
可以看到分组过滤后的确切条目情况,职位数大于200的城市的条目信息:
select * from data.dataanalyst
where city in
(SELECT city FROM data.dataanalyst
group by city having count(positionId)>200)
举例:
SELECT * FROM new_schema.score
where cno='3-105' and DEGREE>all(select degree from new_schema.score
where cno='3-245')
SELECT * FROM new_schema.score
where cno='3-105' and DEGREE>any(select degree from new_schema.score
where cno='3-245')
SELECT * FROM new_schema.score
where cno='3-105' and DEGREE not in(select degree from new_schema.score
where cno='3-245')
select a.* from new_schema.score as a
where a.DEGREE<(SELECT avg(DEGREE) FROM new_schema.score as b
where b.cno=a.cno) #特别注意,与分类后的均值比较
引入sql用于比较情况下any和all的区别
Any:>Any 表示至少大于一个值,即大于最小值。
All: >All 表示大于每一个值。换句话说,它表示大于最大值
六、连接join
1、上下连接两个表使用A UNION B(注意保持同字段名)
SELECT SNAME AS NAME, SSEX AS SEX, SBIRTHDAY AS BIRTHDAY FROM new_schema.STUDENT where ssex="女"
UNION
SELECT TNAME AS NAME, TSEX AS SEX, TBIRTHDAY AS BIRTHDAY FROM new_schema.TEACHER where tsex="女"
2、将两个表通过某个键值连接
select * from data.dataanalyst as d
join data.company as c on d.companyId=c.companyId
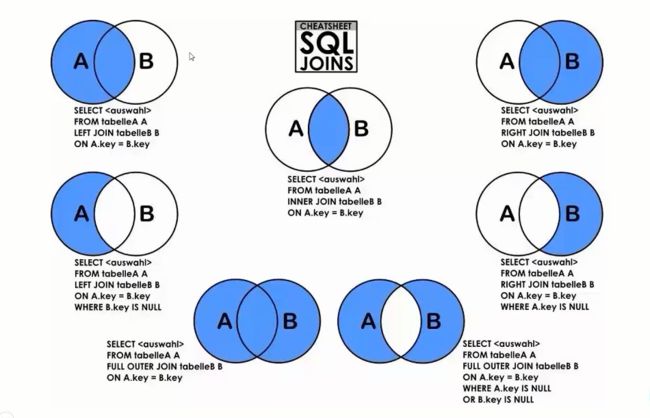
join 相当于inner join 取交集
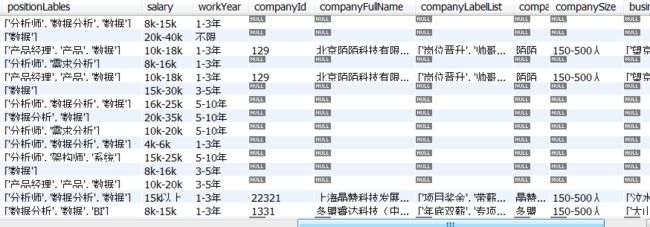
左联结:返回左表的全部和右表匹配的部分
select * from data.dataanalyst as d
left join (select * from data.company
where companySize='150-500人') as c on d.companyId=c.companyId
3、 mysql全联结没有outer join或者full outer join,所以全联结使用
left join union right join 的结构
SELECT u.user_id,a.user_id,account_type FROM `user` u
LEFT join test_account a on u.user_id=a.user_id
union
SELECT u.user_id,a.user_id,account_type FROM `user` u
right join test_account a on u.user_id=a.user_id
4、多表连接使用一个join on实现顺序联结(join后多表用()包起来,键值用and连接):
SELECT u.user_id,a.user_id,c.user_id,account_type,contact_fullname
FROM `user` u
LEFT join (test_account a,user_contact c)
on u.user_id=a.user_id and u.user_id=c.user_id
此时包含了所有u表user_id对应的u表数据,u、a表共同user_id部分对应的a表数据,u、a、c表共同user_id部分对应的c表数据,可以理解为是一种漏斗型联立。
5、针对联结后取数据,如果数据量比较大,多表联结取数据时间过长时,可以使用先取数据再联结的方式
七、存储过程
存储过程是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。可以看做是可编程的函数。
语法:
CREATE PROCEDURE 过程名 ([IN|OUT|INOUT] 参数名 数据类型) 过程体
DELIMITER //
CREATE PROCEDURE myproc(OUT s int)
BEGIN
SELECT COUNT(*) INTO s FROM students;
END
//
DELIMITER ;
分隔符
MySQL默认以";"为分隔符,如果没有声明分割符,则编译器会把存储过程当成SQL语句进行处理,因此编译过程会报错,所以要事先用“DELIMITER //”声明当前段分隔符,让编译器把两个"//"之间的内容当做存储过程的代码,不会执行这些代码;“DELIMITER ;”的意为把分隔符还原。
参数
存储过程根据需要可能会有输入、输出、输入输出参数,如果有多个参数用","分割开。MySQL存储过程的参数用在存储过程的定义,共有三种参数类型,IN,OUT,INOUT:
IN:参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值,相当于输入
OUT:该值可在存储过程内部被改变,并可返回,相当于输出
INOUT:调用时指定,并且可被改变和返回,相当于改变输入并输出
过程体
过程体的开始与结束使用BEGIN与END进行标识。
例如
DELIMITER //
CREATE PROCEDURE num_from_employee (IN emp_id INT, OUT count_num INT )
READS SQL DATA
BEGIN
SELECT COUNT(*) INTO count_num
FROM employee
WHERE d_id=emp_id ;
END
//
DELIMITER ;
八、索引操作
PRIMARY KEY(索引不包含重复值)
1、PRIMARY KEY 约束唯一标识数据库表中的每条记录。
2、主键必须包含唯一的值。
3、主键列不能包含 NULL 值。
4、每个表都应该有一个主键,并且每个表只能有一个主键。
创建主键:
CREATE TABLE 'wb_blog'(
'id' smallint(8) unsigned NOT NULL PRIMARY KEY,#在这里为id字段加上主键
'catid' smallint(5) unsigned NOT NULL DEFAULT '0',
'title' varchar(80) NOT NULL DEFAULT '',
'content' text NOT NULL
) ;
对于没有主键的表进行补主键:
ALTER TABLE wb_blog ADD PRIMARY KEY ('id');
撤销主键:
ALTER TABLE wb_blog DROP PRIMARY KEY;
普通索引(可以存在重复值)
创建普通索引的一个作用是可以优化查询速度(特别是存在重复值的列)
创建索引
CREATE INDEX index_name ON table_name (column_list)
删除索引
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
九、增删查改
1、增insert into
insert into student (name,money,sex,phone) values ('hk',10000,'男',188);
2、删DELETE FROM
DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20);
3、查SELECT from
SELECT * from students limit 5;#查询5条
4、改update set
update student set money=100;#不指定条件,修改所有
十、查询优化
explain来获取查询执行计划的信息
explain
SELECT * FROM `tqzc_info`
- id:包含一组数字,表示查询中执行select子句或操作表的顺序;如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行;id如果相同,可以认为是一组,从上往下顺序执行。
- select_type:示查询中每个select子句的类型(简单OR复杂)
a. SIMPLE:查询中不包含子查询或者UNION
b. PRIMARY:查询中若包含子部分,最外层查询则被标记为PRIMARY
c. SUBQUERY:在SELECT或WHERE列表中包含了子查询,该子查询被标记为SUBQUERY
d. DERIVED:在FROM列表中包含的子查询被标记为:DERIVED(衍生)用来表示包含在from子句中的子查询的select,mysql会递归执行并将结果放到一个临时表中。服务器内部称为"派生表",因为该临时表是从子查询中派生出来的
e. UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED
f. UNION RESULT:从UNION表获取结果的SELECT被标记为UNION RESULT - type:表示MySQL在表中找到所需行的方式,又称“访问类型”,常见类型如下:
ALL, index, range, ref, eq_ref, const, system, NULL
从左到右,性能从最差到最好
a. ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
b. index:Full Index Scan,index与ALL区别为index类型只遍历索引树
c. range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。显而易见的索引范围扫描是带有between或者where子句里带有<, >查询。当mysql使用索引去查找一系列值时,例如IN()和OR列表,也会显示range
d. ref:使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录行
e. eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
f. const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量
g. NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引。例如从一个索引列里选取最小值可以通过单独索引查找完成。 - possible_keys:此次查询中可能选用的索引,指出能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
- key:此次查询中确切使用到的索引,若没有使用索引,显示为NULL
- key_len表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
- ref:显示索引的那一列被使用了。
- rows:显示此查询一共扫描了多少行. 这个是一个估计值,直观显示 SQL 的效率好坏, 原则上 rows 越少越好
- filtered: 表示此查询条件所过滤的数据的百分比
- extra: 额外的信息
a. Using filesort:表示 MySQL 需额外的排序操作, 不是通过索引列进行排序,由于这样的查询 CPU 资源消耗大,所以没有特殊排序要求建议去掉或者改为索引列排序。
b. Using index:"覆盖索引扫描", 表示查询在索引树中就可查找所需数据, 不用扫描表数据文件, 往往说明性能不错。
c. Using temporary:查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高, 建议优化。
优化点:
1、最有效:应尽量避免全表扫描,首先应考虑在 join on 或者where 及 order by 涉及的列上建立索引,但是该列有大量重复数据不建议在该列上建立索引。索引虽然可以提高相应的 select 效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以一个表的索引数较好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要
create index index_name on table_name (column_list)
2、exists()适合内表比外表数据大的情况,其他情况下in与exists效率差不多,可任选一个使用
select * from a where exists(select * from b where b.num=a.num)
3、不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
select id from t where substring(name,1,3)=’abc’
改为
select id from t where name like ‘abc%’
4、尽量少用 select * from t ,用具体的字段列表代替*,避免返回用不到的任何字段。
5、若果中间过程查询量比较大,可以创建中间表
6、尽量避免使用前置百分号
select id from t where name like ‘%c%’
改为
select id from t where name like ‘c%’
7、使用子查询:针对联结后取数据,如果数据量比较大,多表联结取数据时间过长时,可以使用先取数据再联结的方式