[TOC]
参考
1. Rocksdb的SST
2. 深入 LevelDB 数据文件 SSTable 的结构
3. Rocksdb BlockBasedTable Format
4. 浅析RocksDB的SSTable格式
5. RocksDB. BlockBasedTable源码分析
6. leveldb handbook
7. RocksDB(MyRocks)源码学习
0. 前言
本文大部分内容直接摘抄自 LevelDB handbook,同时结合了其他大神的学习分享
1. 总体结构
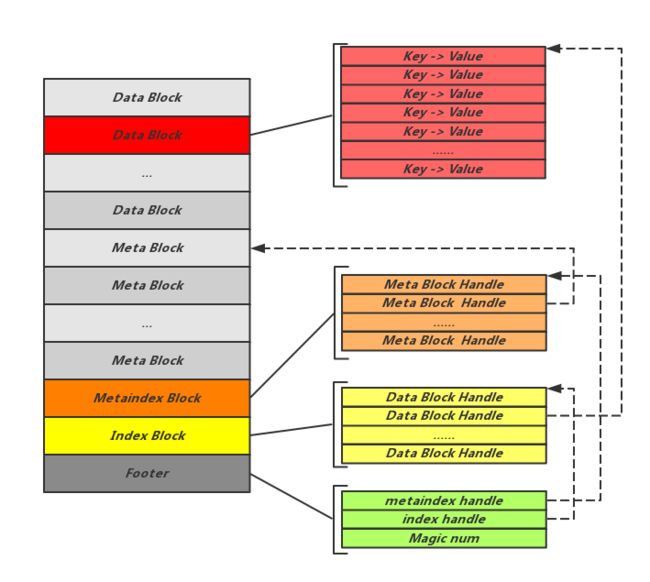
伪码表示文件架构组织如下:
[data block 1]
[data block 2]
...
[data block N]
[meta block 1: filter block] (see section: "filter" Meta Block)
[meta block 2: stats block] (see section: "properties" Meta Block)
[meta block 3: compression dictionary block] (see section: "compression dictionary" Meta Block)
[meta block 4: range deletion block] (see section: "range deletion" Meta Block)
...
[meta block K: future extended block] (we may add more meta blocks in the future)
[metaindex block]
[index block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
如图所示,SST 文件从头到尾分成5个部分。
| 名称 | 占用空间 | 说明 |
|---|---|---|
| Footer | 固定48字节 | 指出 IndexBlock 和 MetaIndexBlock 在文件中的偏移量信息,它是元信息的元信息,它位于 sstable 文件的尾部 |
| IndexBlock | 占用一个 block 空间 | 记录了 DataBlock 相关的元信息 |
| MetaIndexBlock | 占用一个 block 空间 | 各个元信息的Block,包括Filter、Properties(整个table的属性信息)、Compression dictionary、Range deletion tombstone |
| MetaBlock | 可能占用多个 block空间 | 存储布隆过滤器的二进制数据 及其他元信息数据 |
| DataBlock | 可能占用多个 block空间 | 存储实际的数据即键值对内容 |
一个 block默认的block大小为4k,通常设置为64k(对应配置项:table_options.block_size)。
rocksdb的 sst 文件源于leveldb,主要的区别就是在于 MetaBlock 部分,rocksdb 的内容更多,leveldb 的 MetaBlock 当前只有 Filter 的内容。
这里有个疑问:IndexBlock 仅一个,是否够用呢?这个疑问放到下一篇文章进行解答
2. 数据结构
2.1. Block 结构
5个部分的数据结构,除了 Footer,其他的物理结构都是 Block 形式。
Block 在硬盘上存储的时候,会在实际数据之后加上5个字节的额外内容:compression type、crc

2.1.1. DataBlock
data block中存储的数据是leveldb中的keyvalue键值对。其中一个data block中的数据部分(不包括压缩类型、CRC校验码)按逻辑又以下图进行划分:

struct Entry {
varint sharedKeyLength;
varint unsharedKeyLength;
varint valueLength;
byte[] unsharedKeyContent;
byte[] valueContent;
}
struct DataBlock {
Entry[] entries;
int32 [] restartPointOffsets;
int32 restartPointCount;
}
一个 DataBlock 的默认大小只有 4K 字节,所以里面包含的键值对数量通常只有几十个。如果单个键值对的内容太大一个 DataBlock 装不下咋整?
这里就必须纠正一下,DataBlock 的大小是 4K 字节,并不是说它的严格大小,而是在追加完最后一条记录之后发现超出了 4K 字节,这时就会再开启一个 DataBlock。这意味着一个 DataBlock 可以大于 4K 字节,如果 value 值非常大,那么相应的 DataBlock 也会非常大。DataBlock 并不会将同一个 Value 值分块存储。
第一部分(Entry)用来存储key-value数据。由于sstable中所有的key-value对都是严格按序存储的,用了节省存储空间,并不会为每一对key-value对都存储完整的key值,而是存储与上一个key非共享的部分,避免了key重复内容的存储。
每间隔若干个key-value对,将为该条记录重新存储一个完整的key。重复该过程(默认间隔值为16),每个重新存储完整key的点称之为Restart point。
Restart point的目的是在读取sstable内容时,加速查找的过程。
由于每个Restart point存储的都是完整的key值,因此在sstable中进行数据查找时,可以首先利用restart point点的数据进行键值比较,以便于快速定位目标数据所在的区域;
当确定目标数据所在区域时,再依次对区间内所有数据项逐项比较key值,进行细粒度地查找;
该思想有点类似于跳表中利用高层数据迅速定位,底层数据详细查找的理念,降低查找的复杂度。
每一个数据项(Entry)的格式如下:

一个Entry分为5部分内容:
- 与前一条记录key共享部分的长度,为0则表示该 Entry 是一个重启点;
- 与前一条记录key不共享部分的长度;
- value长度;
- 与前一条记录key非共享的内容;
- value内容;
举例如下:
restart_interval=2
entry one : key=deck,value=v1
entry two : key=dock,value=v2
entry three: key=duck,value=v3

三组entry按上图的格式进行存储。值得注意的是restart_interval为2,因此每隔两个entry都会有一条数据作为restart point点的数据项,存储完整key值。因此entry3存储了完整的key。
此外,第一个restart point为0(偏移量),第二个restart point为16,restart point共有两个,因此一个DataBlock数据段的末尾添加了下图所示的数据:

尾部数据记录了每一个restart point的值(每个重启点都是4字节),以及所有restart point的个数(4字节)。
2.1.2. MetaBlock 结构
MetaBlock 中,LevelDB 仅有 Filter 数据,RocksDB 除了 Filter 还有其他的元信息数据。这里只分析下 Filter 数据 - FilterBlock。
为了加快sstable中数据查询的效率,在直接查询datablock中的内容之前,leveldb首先根据filter block中的过滤数据判断指定的datablock中是否有需要查询的数据,若判断不存在,则无需对这个datablock进行数据查找。
filter block存储的是data block数据的一些过滤信息。这些过滤数据一般指代布隆过滤器的数据,用于加快查询的速度,关于布隆过滤器的详细内容,可以见《Leveldb源码分析 - 布隆过滤器》。
struct FilterEntry {
byte[] rawbits;
}
struct FilterBlock {
FilterEntry[n] filterEntries;
int32[n] filterEntryOffsets;
int32 offsetArrayOffset;
int8 baseLg; // 分割系数
}

filter block存储的数据主要可以分为两部分:(1)过滤数据(2)索引数据。
其中索引数据中,filter i offset表示第i个filter data在整个filter block中的起始偏移量,filter offset's offset表示filter block的索引数据在filter block中的偏移量。
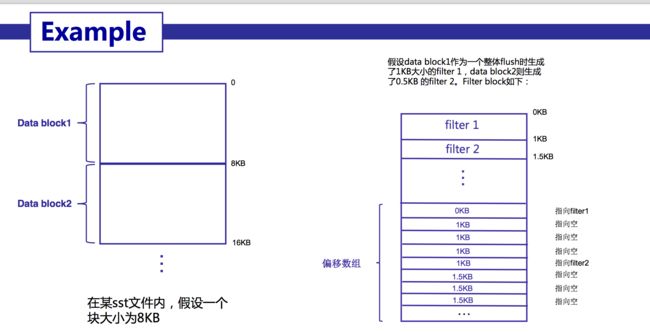

在读取filter block中的内容时,可以首先读出filter offset's offset的值,然后依次读取filter i offset,根据这些offset分别读出filter data。
Base Lg默认值为11,表示每2KB的数据,创建一个新的过滤器来存放过滤数据。这里的 2K 字节的间隔是严格的间隔,这样才可以通过 DataBlock 的偏移量和大小来快速定位到相应的布隆过滤器的位置 FilterOffset,再进一步获得相应的布隆过滤器位图数据。
一个sstable只有一个filter block,其内存储了所有block的filter数据. 具体来说,filter_data_k 包含了所有起始位置处于 [basek, base(k+1)]范围内的block的key的集合的filter数据,按数据大小而非block切分主要是为了尽量均匀,以应对存在一些block的key很多,另一些block的key很少的情况。
至于为什么 LevelDB 的布隆过滤器数据不是整个块而是分成一段一段的,这个原因笔者也没有完全整明白,估计是为了防止 bit 位太多之后,访问 bit 数组的时候容易造成 cache miss。期待有读者可以提供更多思路。
2.1.3. MetaIndexBlock 结构
对于只有 FilterBlock 的情况下,meta index block用来存储filter block在整个sstable中的索引信息。
meta index block只存储一条记录:
该记录的key为:"filter."与过滤器名字组成的常量字符串
该记录的value为:filter block在sstable中的索引信息序列化后的内容,索引信息包括:(1)在sstable中的偏移量(2)数据长度。
2.1.4. IndexBlock 结构
与meta index block类似,index block用来存储所有data block的相关索引信息。
indexblock包含若干条记录,每一条记录代表一个data block的索引信息。
一条索引包括以下内容:
- key,取值是大于等于其索引block的最大key,并且小于下一个block的最小key;
- 该data block起始地址在sstable中的偏移量;
- 该data block的大小;
IndexBlock和 DataBlock 一样,采取了前缀压缩,只不过间隔为2(DataBlock 默认为16)
这里有两个点值得注意:
1. 为什么BlockHandle的offset和size的单位是字节数而不是block?
因为SSTable中的block大小是不固定的,虽然option中可以指定block_size参数,但SSTable中存储数据时,并未严格按照block_size对齐,所以offset和size指的是偏移字节数和长度字节数;跟Innodb中的B+树索引block偏移有区别。这样做主要有两个原因:
- RocksDB可以存储任意长度的key和任意长度的value(不同于Innodb,限制每行数据的大小为16384个字节),而同一个key-value是不能跨block存储的,极端情况下,比如我们的单 个 value 就很大,已经超过了 block_size,那么对于这种情况,SSTable 就没法进 行存储了。所以通常,实际的 Block 大小都是要略微大于 block_size 的;
- 从另外一个角度看,如果严格按照block_size对齐存储数据,必然有很多block通过补0的方式对齐,浪费存储空间;
2. 为什么key不是采用其索引的DataBlock的最大key?
主要目的是节省空间;假设其索引的block的最大key为"acknowledge",下一个block最小的key为"apple",如果DataBlockIndex的key采用其索引block的最大key,占用长度为len("acknowledge");采用后一种方式,key值可以为"ad"("acknowledge" < "ad" < "apple"),长度仅为2,并且检索效果是一样的。
2.5. Footer 结构
以上各部分都是 Block 的结构,只有 Footer 不同,是一个定长的格式。
// 见format.h
class Footer {
public:
Footer() : Footer(kInvalidTableMagicNumber, 0) {}
Footer(uint64_t table_magic_number, uint32_t version);
......
private:
uint32_t version_;
ChecksumType checksum_;
BlockHandle metaindex_handle_;
BlockHandle index_handle_;
uint64_t table_magic_number_ = 0;
};
序列化后,Footer的长度固定,为48个字节(旧)或53字节(新),格式如下:
// legacy footer format:
// metaindex handle (varint64 offset, varint64 size)
// index handle (varint64 offset, varint64 size)
// to make the total size 2 * BlockHandle::kMaxEncodedLength
// table_magic_number (8 bytes)
// new footer format:
// checksum type (char, 1 byte)
// metaindex handle (varint64 offset, varint64 size)
// index handle (varint64 offset, varint64 size)
// to make the total size 2 * BlockHandle::kMaxEncodedLength + 1
// footer version (4 bytes)
// table_magic_number (8 bytes)
Footer 中的信息,指明了 MetaIndexBlock 和 IndexBlock的位置,进而找到 MetaBlock 和 DataBlock。
读取 SST文件的时候,就是从文件末尾,固定读取这48或53字节,进而得到了 Footer 信息。
2.6. BlockHandle 结构
另外可以发现,MetaIndexBlock、IndexBlock和 Footer 中,起到指针作用的value 结构都是offset+value,对应的就是 BlockHandle 的结构。
// 见format.h
class BlockHandle {
public:
BlockHandle();
BlockHandle(uint64_t offset, uint64_t size);
......
private:
uint64_t offset_;
uint64_t size_;
}
为了节省空间,BlockHandle 的offset 和 size 两个字段,都是使用 varint64编码后,连续存放在一起,编码后的大小<=20字节。
void BlockHandle::EncodeTo(std::string* dst) const {
// Sanity check that all fields have been set
assert(offset_ != ~static_cast(0));
assert(size_ != ~static_cast(0));
PutVarint64Varint64(dst, offset_, size_);
}
3. SST 读写流程
3.1. 写流程
写 SST 文件的逻辑,主要在BlockBasedTableBuilder类以下两个函数。
Flush 接口:当一个 DataBlock 满了之后,就需要将 DataBlock输入到磁盘。此时会根据 Block 的 offset 去触发 FilterBlock 的生成(当超过2^BaseLg,就会创建新的 FilterBlock)
-
Finish 接口:当结束的时候,会依次把IndexBlock、MetaBlock、MetaIndexBlock、Footer 写入文件,见下图:
 MetaBlock 的写入顺序
MetaBlock 的写入顺序
整体流程如下:
- 判断Key的类型,如果是范围删除类型,即kTypeRangeDeletion,写入range_del_block
- 如果是值类型,即需要被写入Data Block的Key,需要判断被写入的Block是否已经达到了限定的大小,如果超过了限定的数值,需要被Flush
- 将Key-Value写入Data Block:r->data_block.Add(key, value)
- 每次写入需要更新SST的Version元信息,即SST的边界的最大、最小Key:smallest_key、largest_key
- 完成Meta Block 和MetaIndex Block的写入,保存的是一个handle,即一个block的指针,包括偏移量offset_和size_
- 更新Version的元信息
3.1. 读流程
RocksDB 读数据首先在Memtable中查找,之后是Immutable Memtable,最后再去SST文件中查找。只有当 Memtable 和Immutable Memtable都没有找到时,才会进入到 SST 文件的读流程。
- 通过Version中记录的信息遍历Level中的所有SST文件,利用SST文件记录的边界最大,最小key- smallest_key和largest_key来判断查找的key是否有可能存在
- 如果在该Level中可能存在,调用TableReader的接口来查找SST文件
- 首先通过SST文件中的Filter来初判key是否存在(查询方式见 FilterBlock 小节的介绍)
- 如果存在key存在,进入Data Block中查找
- 在Data Block利用Block的迭代器BlockIter利用二分查找BinarySeek或者前缀查找PrefixSeek
- 如果查找成功则返回,如果该Level不存在查找的Key,继续利用Version中的信息进行下一个Level的查找,直到最大的一个Level