python中内置了很多有用的函数,调用前来贼鸡儿爽。
调用函数需要知道函数的名称和参数。
这是Python的官方文档介绍内置函数。
http://docs.python.org/3/library/functions.html#abs
数学相关
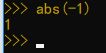
abs(x) 求绝对值
abs()函数返回参数的绝对值
fabs()与abs()的区别
abs()是一个内置函数,fabs()在math模块中定义
fabs()函数只适用于float和integer类型, abs()也适用于复数类型。

min()求最小值
返回给参数最小值
-
初级用法
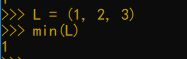 image.png
image.png - 中级用法
key属性的运用
当key参数不为空时,就以key的函数对象为判断的标准。
如果我们想找出value中绝对值最小的数,就可以配合lamda先进行处理,再找出最小值
price = {"HPQ": 37.2, 'FB': 10.75, 'AAPL': 612.78}
min(price, key=lambda k: price[k])
结果如下:

- 高级用法
找出字典中最小的那组数据
price = {"HPQ": 37.2, 'FB': 10.75, 'AAPL': 612.78}
min_price = min(zip(price.value(), price.key()))
print(min_price)
结果如下:

max()求最大值
用法min()相似
中级用法
当key参数不为空时,就以key的函数对象为判断的标准。
如果我们想找出一组数中绝对值最大的数,就可以配合lamda先进行处理,再找出最大值
a = [-9, -8, 1, 2, -1, 6]
max(a, key=lambda x:abs(x))
结果如下:
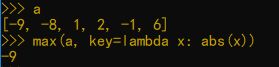
sum(): 求和
语法:sum(iterable[, start])
参数:
iterable -- 可迭代的
start -- 指定相加的参数,如果没有设置这个值,默认为0。

sorted() 排序
sort与sorted的区别
| sort | sorted |
|---|---|
| 在原有的列表上排序 | 排序之后返回一个新列表 |
- 初级用法
g = [1, 4, 6, 8, 9, 3, 5]
print(sorted(g))
print("--------------------")
print(sorted((1, 4, 6, 8, 9, 3, 5)))
print("--------------------")
print(sorted("gafrtp"))
# 反序
print("--------------------")
print(sorted(g, reverse=True))
结果如下:

- 高级用法
有时候,我们要处理的数据内的元素不是一维的,而是二维的甚至是多维的,那要怎么进行排序呢?这时候,sorted()函数内的key参数就派上用场了!从帮助信息上可以了解到,key参数可传入一个自定义函数。
L = [('a', 1), ('b', 2), ('c', 6), ('d', 4), ('e', 3)]
sorted(L, key=lambda x:x[0])
sorted(L, key=lambda x:x[1])
sorted(L, key=lambda x:x[0], reverse=True)
sorted(L, key=lambda x:x[1], reverse=True)
这里,列表里面的每一个元素都为二维元组,key参数传入了一个lambda函数表达式,其x就代表列表里的每一个元素,然后分别利用索引返回元素内的第一个和第二个元素,这就代表了sorted()函数利用哪一个元素进行排列。而reverse参数就如同上面讲的一样,起到逆排的作用。默认情况下,reverse参数为False

参考博客:
https://www.cnblogs.com/brad1994/p/6697196.html
divmod() 获取上和余数
divmod(a,b)方法返回的是a//b(商)以及a%b(余数),返回结果类型为tuple
>>> divmod(9, 2)
(4, 1)
>>> divmod(9, 2)[0]
4
>>> divmod(9, 2)[1]
1
pow() 获取乘方数
与math.pow的区别
| pow | math.pow() |
|---|---|
| 可以在幂乘之后除数求余 | 只能幂乘 |
1、pow(x,y):这个是表示x的y次幂。
2、pow(x,y,z):这个是表示x的y次幂后除以z的余数
>>> pow(2, 4)
16 这个是2**4
>>> pow(2, 4, 5)
1 这个是2**4/5的余数
round() 方法返回浮点数x的四舍五入值.
语法:
round( x [, n] )
参数:
x -- 数字表达式
n -- 表示从小数点位数, 其中x需要四舍五入, 默认值为0
>>> print ("round(70.23456) : ", round(70.23456))
round(70.23456) : 70
>>> print ("round(56.659,1) : ", round(56.659,1))
round(56.659,1) : 56.7
>>> print ("round(80.264, 2) : ", round(80.264, 2))
round(80.264, 2) : 80.26
>>> print ("round(100.000056, 3) : ", round(100.000056, 3))
round(100.000056, 3) : 100.0
>>> print ("round(-100.000056, 3) : ", round(-100.000056, 3))
round(-100.000056, 3) : -100.0
range() 生成一个a到b的数组, 左闭右开
语法:
range(start, stop[, step])
参数说明:
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
- stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
- step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
Python3.x 中 range() 函数返回的结果是一个整数序列的对象,而不是列表。
>>> list(range(10)) # 从0到10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(1, 11)) # 从1到11
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(range(0, 30, 5)) # 步长为5
[0, 5, 10, 15, 20, 25]
>>> list(range(0, 10, 3)) # 步长为3
[0, 3, 6, 9]
>>> list(range(0, -10, -1)) # 负数
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> list(range(0))
[]
>>> list(range(1, 0))
[]
萌萌哒的分割线
类型转换
int() 转为int形
语法:int(x base)
x -- 字符串或数字
base -- 进制数, 默认是十进制
>>> int() # 不传入参数
0
>>> int(3)
3
>>> int(3.6) # 浮点数将向下取整
3
>>> int("12", 16) #如果是带参数base的话,12要以字符串的形式进行输入,12 为 16进制
18
>>> int("0xa", 16)
10
>>> int('10', 16)
16
>>> int(100, 2) # 出错,base 被赋值后函数只接收字符串
参考博客:https://www.cnblogs.com/guyuyuan/p/6827987.html?utm_source=itdadao&utm_medium=referral
float() 转为浮点型
语法:float(x)
x -- 整数或字符串
>>> float(1)
1.0
>>> float(-123.6)
-123.6
>>> float("123")
123.0
str() 转为字符型
语法:str(object="")
>>> str(s)
'asfg'
>>> dict = {"a": 1, "b": 2}
>>> str(dict)
"{'a': 1, 'b': 2}"
bool() 转为布尔型
语法:bool([x])
x -- 要进行转换的参数
>>> bool()
False
>>> bool(0)
False
>>> bool(1)
True
>>> issubclass(bool, int) #bool 是int子类
True
-------------------------------------------------------
>>> bool("") # 空字串 False
False
>>> bool("a")
True
-------------------------------------------------------
>>> bool(()) # 空元组
False
>>> bool((0,)) # 非空
True
>>> bool([]) # 空列表
False
>>> bool([1])
True
>>> bool({}) # 空字典
False
>>> bool({"a": 1})
True
bytes()
desc: bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。
bytes([source[, encoding[, error]]])
- 如果 source 为整数,则返回一个长度为 source 的初始化数组。
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列。
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数。
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。如果没有输入任何参数,默认就是初始化数组为0个元素。
>>> a = bytes([1, 2, 3, 4])
>>> a
b'\x01\x02\x03\x04'
>>> type(a)
>>> a = bytes("helloi", 'ascii')
>>> a
b'helloi'
>>> type(a)
list() 将元组转化为列表
元组与列表类似, 区别在于元组值不能修改,元组放在()中, 列表放在[]
语法: list(iterable)
>>> t = (123, "Goole", "asdas")
>>> list(t)
[123, 'Goole', 'asdas']
>>> str = "sadas"
>>> list(str)
['s', 'a', 'd', 'a', 's']
>>> dict_date = {"a": 1, "b": 2, "c": 3} # 字典好像不能直接转
>>> list(dict_date)
['a', 'b', 'c']
iter() 返回一个可迭代的对象
用来生成迭代器
语法: iter(object[, sentine])
object -- 支持迭代的集合
sentinel -- 如果传递了第二个参数, 则参数 object 必须是一个可调用的对象(如,函数),此时,iter 创建了一个迭代器对象,每次调用这个迭代器对象的next()方法时,都会调用 object。
>>> l = [1, 3, 4]
>>> ite = iter(l)
>>> ite
>>> ite.__next__()
1
>>> ite.__next__()
3
>>> ite.__next__()
4
>>> ite.__next__()
Traceback (most recent call last):
File "", line 1, in
StopIteration
dict() 转化为字典
创建一个字典
语法:dict(**kwarg)
dict(mapping, **kwarg)
dict(iterable, **kwarg)
**kwargs ---关键字
mapping --- 元素的容器
iterable --- 可迭代对象
>>> dict() # 创建字典
{}
>>> dict(a="a", b="b", c="c") # 传入关键字
{'a': 'a', 'b': 'b', 'c': 'c'}
>>> dict(zip(["one", "two", "three"], [1,2,3])) # 映射函数方式来构造字典
{'one': 1, 'two': 2, 'three': 3}
>>> dict([('one', 1), ('two', 2), ("three", 3)]) # 可迭代对象方式来构造字典
{'one': 1, 'two': 2, 'three': 3}
enumerate() 返回一个枚举对象
函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
语法: enumerate(iterable, [start=0])
seasons = ["Spring", "Summer", "Fall", "Winter"]
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1))
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
__________________ 分割线________________
普通for 循环
>>> i = 0
>>> seq = ["one", "two", "three"]
>>> for element in seq:
... print(i, seq[i])
... i += 1
...
0 one
1 two
2 three
enumerate 循环
>>> seq = ["one", "two", "three"]
>>> for i, element in enumerate(seq):
... print(i, seq[i])
...
0 one
1 two
2 three
————————————————————补充———————————————————
# 如果要统计文件的行数,可以这样写
>>>count = len(open(filepath, 'r').readlines())
>>>1
# 这种方法简单,但是可能比较慢,当文件比较# 大时甚至不能工作。
可以利用enumerate():
>>>count = 0
>>>for index, line in enumerate(open(filepath,'r')):
>>> count += 1
>>>1
>>>2
>>>3
参考博客:https://www.cnblogs.com/quietwalk/p/7997850.html
tuple() 函数将列表转换为元组。
语法:tuple(seq)
seq --- 要转换为元组的序列
>>> list = ["Google", "tabao", "baidu"]
>>> tuple1 = tuple(list)
>>> tuple1
('Google', 'tabao', 'baidu')
set() 转化为set
desc: 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
语法: set([iterable])
返回新的集合
>>> x = set("runoob")
>>> y = set("google")
>>> x,y
({'u', 'o', 'r', 'b', 'n'}, {'o', 'g', 'e', 'l'})
>>> x&y # 交集
{'o'}
>>> x | y # 并集
{'l', 'u', 'o', 'r', 'b', 'g', 'n', 'e'}
>>> x - y # 差集
{'b', 'r', 'n', 'u'}
hex() 转化为16进制
语法:hex(x)
>>> hex(12233)
'0x2fc9'
>>> hex(-12)
'-0xc'
oct() 转化为8进制
语法:oct(x)
>>> oct(12)
'0o14'
>>> oct(-12)
'-0o14'
bin() 转化为2进制
语法:bin(x)
>>> bin(1)
'0b1'
>>> bin(-1)
'-0b1'
chr() 转化为数字为相应的ASCII码
描述: 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
>>> chr(0x31) # 十六进制
'1'
>>> chr(0x61)
'a'
>>> chr(49) # 十进制
'1'
>>> chr(97)
'a'
ord() 转化ASCII字符为相应的数字
语法:ord(c)
>>> ord("a")
97
>>> ord("b")
98
>>> ord("c")
99
相关操作
eval(): 执行一个表达式, 或字符串作为运算。
描述:eval() 函数用来执行一个字符串表达式,并返回表达式的值。
语法:eval(expression[, globals[, locals]])
- expression -- 表达式
- globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
>>> x = 7
>>> eval('3 * x')
21
>>> eval('pow(2, 2)')
4
>>> eval('2+2')
4
>>> n = 81
>>> eval("n+4")
85
可以把list,tuple,dict和string相互转化。
参考博客:https://www.cnblogs.com/liu-shuai/p/6098246.html
详解:
https://www.cnblogs.com/dadadechengzi/p/6149930.html
exec() 执行Python语句
没用过
map() 根据提供的函数对指定序列做出映射
描述:
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
ensp; 用法灵活,结合lambda 使用。
语法:
map()函数语法:
map(function, iterable, ...)
- function 函数, 有两个参数
- iterable 一个或多个序列
返回值:
Python 2 列表
Python3 迭代器
>>> def square(x):
... return pow(x, 2)
...
>>> map(square, [1,2,3,4,5])
filter() 对指定序列执行过滤操作
描述: 用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
语法: filter(function, iterable)
function -- 判断函数
iterable -- 可迭代对象
返回值
返回一个迭代对象
>>> def is_odd(n):
... return n % 2 == 1
...
>>> tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
>>> newlist = list(tmplist)
>>> print(newlist)
[1, 3, 5, 7, 9]
过滤1-100中平方根是整数的数:
>>> import math
>>> def is_sqr(x):
... return math.sqrt(x) % 1 == 0
...
>>> tmplist = filter(is_sqr, range(1, 101))
>>> newlist = list(tmplist)
>>> print(newlist)
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
reduce() 对参数序列中元素进行累积
描述:函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
注意:在python3.0以后, reduce不在内建函数中了, 要用它就要from functools import reduce
语法:
reduce(function, iterable[, initializer])
- function 函数, 有两个参数
- iterable 可迭代对象
- initializer 可选, 初始参数
>>> from functools import reduce
>>> reduce(lambda x, y: x+y, [1, 2, 3])
6
>>> reduce(lambda x, y: x+y, [1, 2, 3], 9)
15
-----------------------------------------------------
from functools import reduce
def add(x,y):
return x + y
print (reduce(add, range(1, 101)))
result=5050
————————————————————————————————
统计某字符串重复的次数
>>> from functools import reduce
>>> sentences = ['The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. ']
>>> word_count =reduce(lambda a,x:a+x.count("learning"),sentences,0)
>>> print(word_count)
>>> 2
zip() 将iterable分组合并。返回一个zip对象
函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换。
语法:
zip([iterable, ...])
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> c = [4, 5, 6, 7, 8]
>>> zipped = zip(a, b) # 返回一个对象
>>> zipped
>>> list(zipped)
[(1, 4), (2, 5), (3, 6)]
>>> list(zip(a, c)) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>>
>>> a1, a2 = zip(*zip(a, b)) # 与zip相反, *zip可以理解为解压, 返回二维矩阵。
>>> list(a1)
[1, 2, 3]
>>> list(a2)
[4, 5, 6]
————————————————————————————————
>>> v1 = {1:11, 2:22}
>>> v2 = {3:33, 4:44}
>>> v3 = {5:55, 6:66}
>>> v = list(zip(v1, v2, v3)) # 压缩
>>> print(v)
[(1, 3, 5), (2, 4, 6)]
>>> w = zip(*zip(v1, v2, v3)) # 解压
>>> print(list(w))
[(1, 2), (3, 4), (5, 6)]
参考博客:https://www.cnblogs.com/wushuaishuai/p/7766470.html
hash() 返回一个对象的hash值,
用于获取取一个对象(字符串或者数值等)的哈希值
语法:
hash(obj)
>>> hash('test') # 字符串
740618988
>>> hash(1) # 数字
1
>>> hash(str([1, 2, 3])) # 集合
2097662348
>>> hash(str(sorted({'1':1}))) # 字典
1162454008
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
- isinstance() 与 type()的区别
>**type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。**
>>> class A:
... pass
>>> class B(A):
... pass
>>> isinstance(A(), A)
True
>>> type(A()) == A
True
>>> isinstance(B(), A)
True
>>> type(B()) == A
False
语法:
isinstance(obj, classinfo)
- object -- 实例对象。
- classinfo -- 可以是直接或间接类名、基本类型或者由它们组成的元组。
>>> a = 2
>>> isinstance(a, int)
True
>>> isinstance(a, str)
False
>>> isinstance(a, (str, int, list)) # 是元组中的一个返回True
True
issubclass() 方法用于判断参数 class 是否是类型参数 classinfo 的子类。
语法:
issubclass(class, classinfo)
>>> class A:
... pass
>>> class B(A):
... pass
>>> print(issubclass(B,A))
True
reversed() 生成一个反序列的迭代器
语法: reversed(seq)
seq -- 要转换的序列, 可以是tuple, string, list或者range
>>> seqstring = 'Runoob' # 字符串
>>> print(list(reversed(seqstring)))
['b', 'o', 'o', 'n', 'u', 'R']
>>> seqtuple = ('R', 'u', 'n', 'o', 'o', 'b') # 元组
>>> print(list(reversed(seqtuple)))
['b', 'o', 'o', 'n', 'u', 'R']
>>> seqrange = range(5, 9)
>>> print(list(reversed(seqrange)))
[8, 7, 6, 5]
>>> seqlist = [1, 2, 4, 3, 5] # 列表
>>> print(list(reversed(seqlist)))
[5, 3, 4, 2, 1]
详解博客:
https://blog.csdn.net/sxingming/article/details/51353379
globals() 返回当前全局变量的字典
函数会以字典类型返回当前位置的全部全局变量。
其他
hasattr(obj, name)
判断一个对象里面是否有name属性或者name方法,返回BOOL值,有name特性返回True, 否则返回False。
需要注意的是name要用括号括起来
getattr(obj, name)
获取对象object的属性或者方法,如果存在打印出来,如果不存在,打印出默认值,默认值可选。
需要注意的是,如果是返回的对象的方法,返回的是方法的内存地址,如果需要运行这个方法,
可以在后面添加一对括号。
setattr(obj, name, values)
给对象的属性赋值,若属性不存在,先创建再赋值。
join()
用于将序列中的元素以指定的字符连接生成一个新的字符串。
语法:
str.join(seq)
seq --- 要连接的元素序列
返回值:
返回通过指定字符连接序列中元素后生成的新字符串
>>> str = "-"
>>> seq = ("a", "b", "c")
>>> str = str.join(seq)
>>> print(str)
a-b-c
>>> str = "".join(seq)
>>> str
'abc'
参考博客:
https://www.cnblogs.com/cenyu/p/5713686.html
本文主要参考菜鸟教程, 觉得不错点个赞呗。