前言
消息队列,通常有两种场景,一种是发布者订阅模式,一种是生产者消费者模式。发布者订阅模式,即发布者生产消息放入队列,多个监听的消费者都会收到同一份消息,也就是每个消费者收到的消息是一样的。生产者消费者模式,生产者生产消息放入队列,多个消费者同时监听队列,谁先抢到消息就会从队列中取走消息,最终每个消息只会有一个消费者拥有。
在大数据时代,传统的生产者消费者队列模式中的Topic数目可能从少量的几个变为海量topic。例如要实现一个全网爬虫抓取任务调度系统,每个大型的门户,SNS都会成为一个topic。在topic内部也会有海量的子网页需要抓取。在实现这样的一个任务分发调度系统时可能会遇到以下一些问题:
海量的topic,意味着我们可能会有海量的队列。针对爬虫场景,根据网页类型,一类网站对应到一个任务队列,不同的任务队列会有自己的生产者和消费者。
生产者和消费者会有多个,在业务峰值期间,产生较大并发访问,消息总量也是海量。针对爬虫任务消息总量可能就是全网的网页地址数量。
任务可能会有优先级,为了实现优先级高的任务优先调度,我们可能会在一个topic下再细分子队列。
消息消费不能丢失,如果是作为任务的调度消息,我们的消息丢失失零容忍的。
消费者模式中如果消费者因为种种原因处理失败或者超时,需要支持消息被重新调度。
在保证消息一定会被处理的前提下,我们也要避免少量消息因为各种原因处理堆积,而影响整个系统的吞吐。因为消息读区往往是轻量级,消息的处理是资源密集型。我们不希望因为消息读区堆积导致处理资源闲置。
解决方案
基于TableStore(表格存储)的跨分区高并发,主键自增列这个特性又很好的适配到我们的队列特性。支持海量,不同分区键下使用各自的自增主键,可以很好的实现海量队列。具体我们给出如下方案:
需要设计以下表:
1.任务消息表
2.消息消费checkpoint表
3.全量消息表
在介绍表设计之前,先做一些名词解释。
1.每个任务消息,我们假设已有一个唯一的id。
2.任务优先级,我们假设优先级范围是固定并且已经知道,如果任务优先级过多,可以分层,例如优先级1~100的映射到层级1。这里如果我们的任务没有优先级,那可以根据任务数据量级做一个简单的分桶,然后轮训抓取每个分桶中的任务。
3.两个游标,对应到每个topic的每个优先层级,我们需要记录2个游标位移点。一个是抓取扫描游标,一个是完成游标。扫描游标的定义是指当前任务当前优先层级下,被扫描到的最大位移位置。完成位移点表示改任务当前优先层级下,最大的抓取完成位移点,之前的任务都已经完成抓取。
表设计
任务消息表
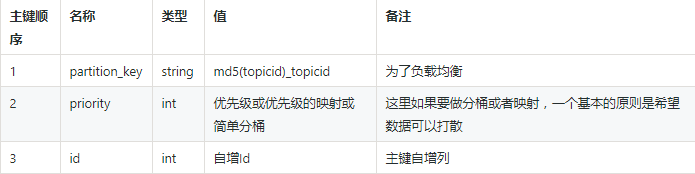
这里,每一个子任务都会被插入这张表,任务可能由不同的爬虫端抓取后产生子任务,在子任务产生的同时,任务的访问地址,访问优先级已经被固定。我们根据一个分层算法进行映射。所以主键前三列已经确定,插入TableStore(表格存储)后,id会自增生成,用于后续消费者读任务用。
消息消费checkpoint表
这张表用于消息消费的checkpoint。下面会结合schema具体说下checkpoint的内容。

这张表属性列上会有两列,一列用来表示抓取扫描位移点,一列记录完成位移点。这里checkpoint的记录需要使用条件更新,即我们只会确保原来值小于待更新的值才会更新。
全量消息表
我们用全量消息表存放我们的消息id以及对应属性,一个消息任务是否重复处理也通过这张表做判断。

在全网信息表中,有一列属性用来表示任务处理状态,消费者在拿到任务id时需要条件更新这张表对应的这个key,对应行不存在可以直接插入。如果已经存在,需要先读状态为非结束状态,版本为读到版本情况下再做更新。更新成功者意味着当前id的任务被这个消费者抢占。其中行不存在表示第一次爬取,如果存在非结束状态,表示之前的任务可能已经失败。
任务消费处理流程
下面我们用爬虫抓取全网网页做为例子来看下具体如何基于TableStore(表格存储)做消息队列并最终实现任务的分发:
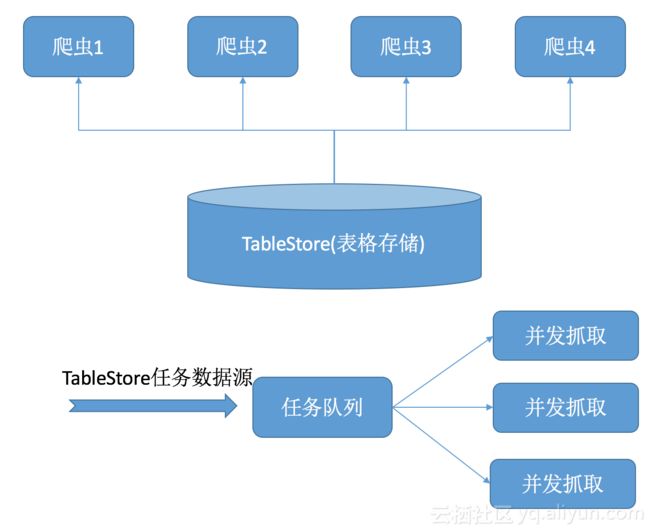
这张图展现了我们的整个爬虫框架,爬虫具体流程如下
不同的爬虫端会根据自身爬取进度定时从TableStore的爬虫任务表进行拉取爬虫任务,这里一般我们单线程GetRange访问TableStore,我们认为这里的任务读区速率会远大于抓取消费者的速度,从TableStore读区到的任务数据进入爬虫内存队列,然后进行下一轮任务消息读区。直到当前内存队列满后等待下轮唤醒继续抓取,如果有特殊需求可以并发拉取不同优先级。
初始对于每个任务的各个priority,他们的默认checkpoint都对应于TableStore的一个flag即Inf_Min,也就是第一行。
GetRange拉取到当前任务各优先级抓取任务后(例如我们可以设置从优先级高到低,一次最多200条,抓够200条进行一次任务抢占),爬虫会先根据具体优先级排序,然后按照优先级从高到低尝试更新网页信息表,进行爬取任务抢占,抢占成功后,该任务会被放进爬虫的内存任务队列给抓取线程使用。抢占成功同时我们也会更新一下爬虫任务表中的状态,和当前的时间,表示任务最新的更新时间,后续的任务状态检验线程会查看任务是否已经过期需要重新处理。注意这里假如有一个爬虫线程比较leg,是上一轮抢占任务后卡了很久才尝试更新这个时间,也没有问题。这种小概率的leg可能会带来重复抓取,但是不会影响数据的一致性。并且我们可以在内存中记录下每一步的时间,如果我们发现每一步内存中的时间超时也可以结束当前任务,进一步减少小概率的重复抓取。
当一轮的任务全部填充后,我们会根据当前拿到的最大任务表id+1(即爬虫任务表第三个主键,也就是自增主键)进行尝试当前任务对应优先级checkpoint表的更新(这里更新频率可以根据业务自由决定),更新的原则是新的id要大于等于当前id。如果更新成功后,可以使用当前更新值继续拉取,如果更新失败,意味着有另一个爬虫已经取得更新的任务,需要重新读一下checkpoint表获得最新的checkpoint id值,从该id继续拉取。
除了任务抓取线程以为,每个爬虫端可以有一个频率更低的任务进行任务完成扫描,这个任务用来最新的完成任务游标。扫描中getrange的最大值为当前拉取的起始位置,扫描的逻辑分以下几种:
扫描到该行已经更新为完成,此时游标可以直接下移
扫描到任务还是initial状态,一个任务没有被任何人设置为running,切被拉去过,原因是这个任务是一个重复抓取的任务,此时可以去url表中检查这个url是否存在,存在直接跳过。
扫描到任务是running,不超时认为任务还在执行,结束当轮扫描。如果检查时间戳超时,检查url表,如果内容已经存在,则有可能是更新状态回任务表失败,游标继续下移。如果内容也不存在,一种简单做法是直接在表对应优先级中put一个新任务,唯一的问题是如果是并发检查可能会产生重复的任务(重复任务通过url去重也可以解决)。另一种做法也是通过抢任务一样更新url表,更新成功者可以新建任务下移坐标。其余的人停止扫描,更新checkpoint为当前位置。更新成功者可以继续下移扫描直至尾部或者任务正常进行位置,然后更新checkpoint。
爬虫抓取每个任务完成后,会更新全网url表中的状态以及对应爬虫任务表中的状态,其中全网url的状态用来给后续抓取任务去重使用,爬虫任务表中的状态给上面步骤5的完成游标扫描线程使用判断一个任务是否已经完成。
整个写入子任务和读取我们可以抽象出下面这张图
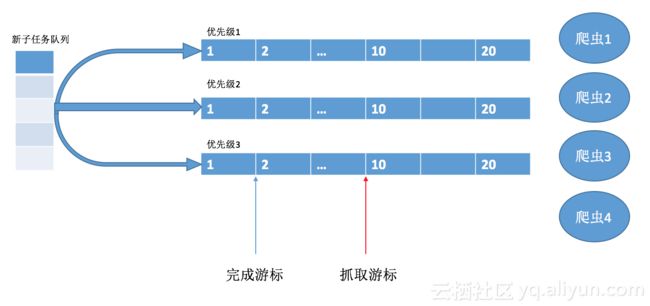
新任务会根据优先级并发写入不同的队列,其中图中编号就对应表格存储中的自增列,用户按照上面设计表结构的话,不需要自己处理并发写入的编号,表格存储服务端会保证唯一且自增,即新任务在对应队列末尾。爬虫读取任务的游标就是图中红色,蓝色对应完成的任务列表。两个游标在响应优先级下独立维护。
下面我们举个例子,如果一个爬虫任务拉取线程假如设置一次拉2个任务为例,
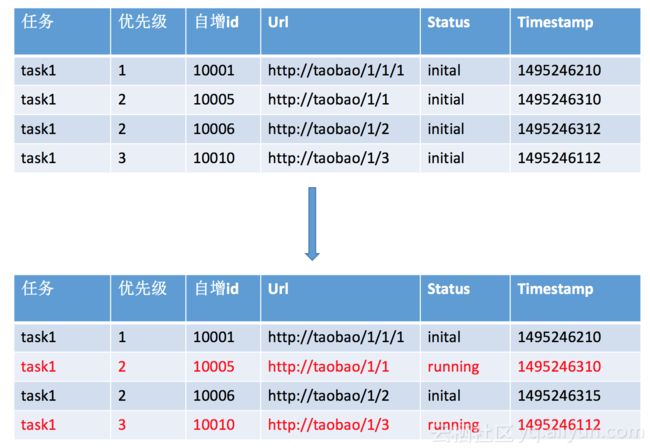
我们的爬虫任务表会从上面切换成下图,task1 priority=3的扫描游标更新到了10011,priority=2的扫描游标更新到10006。也就意味着扫描优先级3的下次会从10011开始,优先级2的会从10006开始。
并发处理
多爬虫拉取任务有重复,这部分我们通过条件更新大表决定了同一个网页不会同时被抓取。
多爬虫条件更新checkpoint表决定了我们整个拉取任务不会漏过当前拉到的一批任务,如果checkpoint更新如果条件失败任务继续进行,其他类型可重试错误会继续重试(例如服务短时间不可用,leg等。)这里只有可能导致其他爬虫唤醒后拉到重复数据,但是抓取因为抢占失败也不会重复拉取,并且新唤醒的客户端也会更新更大的游标,保证系统不会因为一个客户端leg而任务扫描游标滞后。
任务判定完成逻辑我们可以做分布式互斥,同时只有一个进程在判断。也可以在判断任务失败的时候进行条件更新原表,更新成功后再新插入一条新任务。
总结
最后我们再来看下整个设计中几个关键的问题是否满足
海量topic,TableStore(表格存储)天然的以一个分区键做为一个队列的能力使得我们可以很容易的实现海量的队列,数量级可以在亿级别甚至更多。
优先级,优先级对应一个主键列,依照优先级进行分层优先级高的会被优先getrange获得。
系统吞吐,整个系统中两个游标的设计,使得我们任务扫描游标每轮扫描后都会快速向下走,长尾任务不会阻碍对新任务的扫描。另一方面我们任务会在url大表上做抢占,避免不必要的重复抓取。
子任务不丢失,自增列的保证了新任务会用更大的值即排在当前队列末尾。另外有一个完成扫描线程,会确保新任务全部完成后才会更新,这个游标代表了最后整个任务是否完成。这个游标也保证了任务不会丢失。这个任务会对长尾的任务重新建一个任务并插入队列,新任务会被新爬虫端重新触发,也避免了因为一个客户端卡住而饿死的问题。