Redis 复制
Redis通过持久化技术(RDB/AOF)保证即使缓存服务器重启数据也基本不会丢失。当我们部署一台单节点Redis服务器时,假若磁盘损坏,服务将会直接不可用,并且数据丢失,这对应用层面来讲是绝对不能够容忍的。为了避免单节点故障,通常会部署多个副本在不同的服务器来保证Redis的高可用性。Redis提供了Replication功能,当一台Master服务器数据更新后,自动同步到Slave上。
Master-Slave机制下,Master负责读写,Slave一般负责读。默认配置Slave是只读的,如果在Slave上直接进行写操作会报错误。
(error) READONLY You can't write against a read only slave.
如果希望Slave可以直接进行写操作,设置slave-read-only yes即可。当然建议设置为no。
实践
创建redis.conf,端口7991为Master,端口7992为Slave。
mkdir -p cluster-7991/{config,log,data,pid}
mkdir -p cluster-7992/{config,log,data,pid}
分别为两个Redis实例配置文件,将配置文件配置在config目录下,名为redis.conf。
port 7991
bind 0.0.0.0
daemonize yes
protected-mode yes
appendonly yes
dir /Users/wujunbin/Work/redis-cluster/cluster-7991/
#repl-diskless-sync yes
port 7992
bind 0.0.0.0
SLAVEOF 127.0.0.1 7991
daemonize yes
protected-mode yes
appendonly yes
dir /Users/wujunbin/Work/redis-cluster/cluster-7992/
#repl-diskless-sync yes
注意在Slave的的配置文件中加入slaveof用于指定当前实力是谁的slave。
启动redis-server
redis-server cluster-7991/config/redis.conf &
redis-server cluster-7992/config/redis.conf &
redis-cli 进入查看
:~/Work/redis-cluster$redis-cli -p 7991
127.0.0.1:7991> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=7992,state=online,offset=70,lag=0
master_replid:ee41a261a4aa0c89ffeca4776e23a5598f896c7f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:70
connected_salves:1表明了连接了一个slave节点。接下来插入数据。
127.0.0.1:7991> set hello world
OK
登录Slave节点查看
:~/Work/redis-cluster$redis-cli -p 7992
127.0.0.1:7992> get hello
"world"
127.0.0.1:7992>
成功的取出了数据,说明主从配置成功。
同步原理
首先引用一张图
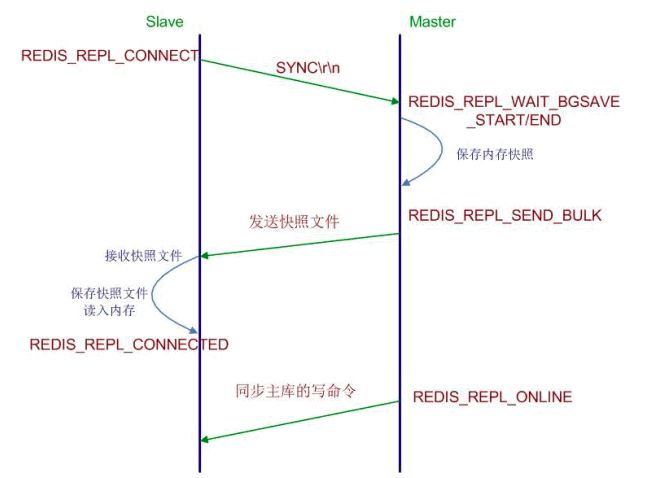
主要分为三个阶段
-
Slave发送sync命令或者psync请求初始化。 -
Master判断是否增量初始化。如果不是,生成dump.rdb文件,并将该文件传输给Slave。如果是,则将积压队列中命令偏移量之后的命令发送给Slave。 - 初始化之后
Master对Slave进行增量更新,一旦有更新传输写命令给Slave节点。
Sync和Psync
试想一下Slave的某个流程:启动-Master数据同步-停止-启动。最后一步的启动,因为Slave在停止前已经接受了Master的数据同步,所以本地是有数据的。所以是不需要将Master的dump.rdb全部传输给Slave。只需要将Slave停止之后的所有写命令在Slave再次启动后传输给Slave,即可完成数据同步。Redis为了完成这一点在Master维护了一个命令积压队列(默认大小1M,有效时常1个小时)。每一次Master的写入命令会放入这个队列,并同步写命令和写命令在队列中的偏移量给Slave。Slave除了执行写命令也会记录这个命令的偏移量。当Slave再次启动时发送PSYNC + Master Run ID + 命令偏移量到Master。Master收到psync指令,首先判断run id是不是自己,如果是再根据命令偏移量从队列中查找。如果找到直接同步偏移量之后的命令给Slave。如果偏移量不在队列中那么无法满足增量复制,Master就会生成dump.rdb进行同步。
无硬盘复制
当Redis使用一主多从的集群架构时,每次和Slave全量同步,Redis都会执行一次快照,同时对硬盘进行读写,导致性能下降。Redis提供了
repl-diskless-sync yes参数。指定后,在复制初始化时就会直接将生成到dump.rdb数据的内容通过网络传输给Slave,而不需要先存储在磁盘上。
Master崩溃,Slave切换为Master
当Master崩溃时,在Slave中使用SLAVEOF NO ONE命令将从数据库提升为主数据库继续服务。然后重新启动崩溃的Reids实例,该实例就变成了Slave然后从Master再次同步数据。
参考文章:http://www.ywnds.com/?p=5489