基础组件介绍
QuorumPeerMain,服务端启动类;
QuorumPeer,集群中的一台server对象实例;
QuorunCnxManager,负责leader选举;
WorkerReceiver,
WorkerSender,
FastLeaderElection,leader选举算法;
QuorumVerifier,包括allMembers、votingMembers、observingMembers
QuorumServer,(serverId,serverAddress)
QuorumPeerConfig,包含所有配置文件的配置信息,从zoo.cfg解析得到;
ServerConfig,服务端基本配置;
JettyAdminServer,启动jetty服务器,用于通过调用url执行zookeeper命令;
ServerCnxnFactory,启动客户端监听,接收连接请求,负责socket读写;
ClientCnxn,客户端连接;
ContainerManager,负责清空container的znode,应当只在leader服务器运行;
ZooKeeperServer,zookeeper核心服务,使用CounDownLatch保证服务不会退出;
ZKDatabase,zookeeper内存数据库,封装对zk节点的操作
FileTxnSnapLog,实际对节点进行操作
Snapshot,内存数据的快照,存放于dataDir;
TxnLog,事务操作日志,存放于dataLogDir;
QuorumPocket,网络请求对象,所有server间的交互最终都封装成该对象;
Request,请求对象实体,写请求对象的hdr(header)不为空,读请求的hdr为空;
ZooKeeper启动流程
集群模式:
- 解析配置文件;(zoo.cfg -> QuorumPeerConfig)
- 加载ZKDatabase数据;(ZKDatabase)
- 根据snapshot初始化内存镜像;
- 判断txtlog是否存在zxid大于当前内存lastProcessedZxid,是则添加到内存镜像中,同时更新lastProcessedZxid;
- 启动ServerCnxnFactory;(ServerCnxnFactory,接收客户端连接)
- 启动AdminServer;(AdminServer,用于接收通过url执行的命令)
- 开始leader选举;(由QuorumCnxManager负责投票的接收和发送,FastLeaderElection实现具体的选举逻辑)
- 创建选举算法,当前只支持FastLeaderElection;
- 启动选举流程;
- 根据选举结果,执行各自的leader/follower/observer逻辑;
- follower.followLeader/observer.observeLeader:
- connectToLeader
- registerWithLeader (接收新的epoch)
- syncWithLeader
- leader.lead
- 删除过期session;
- 启动learner监听线程,每个连接的服务器由一个单独的LearnerHandler处理;
- syncFollower,同步leader和follower差异;
- 如果lastProcessedZxid == peerLastZxid, 发送diff消息,不进行操作;
- 如果lastProcessedZxid < peerLastZxid,发送trunc消息,follower放弃更新;
- 如果lastProcessedZxid > peerLastZxid,发送commit消息;
- 启动leader消息发送线程,用于将leader消息发送给follower;
- 循环监听follower发送到leader的消息,根据消息类型进行处理;
- syncFollower,同步leader和follower差异;
- 更新epoch;
- follower.followLeader/observer.observeLeader:
ServerState:
LOOKING, 该状态的server会发起投票逻辑,选举成功后转为FOLLOWING或LEADING状态;
FOLLOWING, 集群follower,可独立处理读请求,并能将写请求发送给leader;
LEADING, 集群Leader;
OBSERVING,observer,只能从leader同步数据;
LearnerType:
PARTICIPANT,可参与投票选举;
OBSERVER,无法发起投票;
Server交互
zookeeper集群配置中的服务器,默认都有选举权限,可手动配置为observer,此时只能从follower同步数据,不能发起投票;
默认选举算法实现类:FastLeaderElection,包含WorkerSender和WorkerReceiver线程;
选举过程管理类:QuorumCnxManager,包括消息发送(SendWorker)、接收(RecvWorker)以及连接监听(Listener)线程;
logicalclock,当前选举轮次;
1. 选主

服务启动时选主,启动QuorumPeer时,
- QuorumPeer.start(),调用startLeaderElection方法,初始化当前选票、选举算法以及初始化QuorumCnxManager,其中包括选举的消息发送、接收以及连接监听线程;
- QuorumPeer.run(),调用lookForLeader方法,开始leader选举;
- server的首张选票都投给自己(myid,lastProcessedZxid,currentEpoch)
- WorkerSender.run(),发送选票,如果选举的leader是自身,则直接入队;如果是其他server,则将选票加入到发送队列中,通过网络进行发送;
- QuorumCnxManager通过queueSendMap,对每个server都维持了一个发送队列;
- 如果当前server和目标server还没建立连接,则开始进行连接的创建,由QuorumCnxManager中的Listener监听连接请求,初始化SendWorker和RecvWorker线程;
- QuorumCnxManager.SendWorker.run(),从发送队列获取待发送消息进行发送;
- QuorumCnxManager.RecvWorker.run(),监听到请求消息,将消息添加到接收队列中recvQueue;
- WorkerReceiver.run(),从接收队列中获取消息进行解析,添加到recvqueue队列中;
- QuorumPeer从recvqueue获取消息,判断是否接收当前投票(n为当前接收到的选票,self为自身);
- n.electionEpoch>self.electionEpoch,
- 1.清空票箱
- 2.判断是否接收选票,接收则更新自身选票
- 3.重新发送投票;
- n.electionEpoch
- n.electionEpoch=self.electionEpoch,
- 判断是否接收当前选票,接收则更新自身选票,重新发送投票;
- n.electionEpoch=self.electionEpoch,
- n.electionEpoch>self.electionEpoch,
- 将选票加入票箱,统计投票,判断当前是否已收到所有服务器的投票,
- 是,等待一段时间,看后续有没有新的投票进来;
- 有新的投票进来,则继续下一轮投票;
- 无新的投票进来,判断当前服务是否为leader(是则更新服务状态为leading),否则改为following状态,结束投票;
- 否,继续投票;
- 是,等待一段时间,看后续有没有新的投票进来;
- leader执行lead方法,follower执行followLeader;(Leader,LearnerHandler,Follower,Learner,RequestProcessor)
- Leader.lead,leader启动监听线程,epoch+1,监听follower的请求,将leader已提交的提案同步给learner;
-
zookeeper选主时消息发送、接收逻辑如图所示:

选票(Vote)结构如下所示:
final private int version; //
final private long id; //当前zookeeper server的id,当前投票所选的leader id
final private long zxid; //会话id
final private long electionEpoch;//当前选举周期,每次投票时,通过logicalclock自增
final private long peerEpoch; //当前被选举的leader周期(leader的选举轮次)
//zxid由peerEpoch(高32位)和electionEpoch(低32位)和组成
electionEpoch,每执行一次leader选举,electionEpoch就会自增,用来标记leader选举的轮次;
peerEpoch,每次leader选举完成之后,都会选举出一个新的peerEpoch,用来标记事务请求所属的轮次;
判断是否接收当前选票的逻辑如下:
/*
* We return true if one of the following three cases hold:
* 1- New epoch is higher
* 2- New epoch is the same as current epoch, but new zxid is higher
* 3- New epoch is the same as current epoch, new zxid is the same
* as current zxid, but server id is higher.
*/
return ((newEpoch > curEpoch) ||
((newEpoch == curEpoch) &&
((newZxid > curZxid) || ((newZxid == curZxid) && (newId > curId)))));
ZAB相关文章:
https://cwiki.apache.org/confluence/display/ZOOKEEPER/ZooKeeperArticles
https://cwiki.apache.org/confluence/display/ZOOKEEPER/Zab1.0
2. 请求处理

1. 读请求
follower、leader可独立响应读请求,server间不需要交互;
2. 写请求
leader可单独响应写请求;
follower在接收到写请求后,需将请求转发给leader进行处理,leader返回结果后,follower再响应client请求;
主要功能类:
Leader(LeaderZooKeeperServer),LearnerHandler(处理follower请求),
Follower(FollowerZooKeeper),Learner(接收leader发送的proposal/commit等请求),
Server在接收到客户端请求之后,将请求提交给RequestProcessor进行处理;
Leader和Follower有各自的RequestProcessor处理链;
| ZooKeeperServer | RequestProcessor |
|---|---|
| LeaderZooKeeperServer | LeaderRequestProcessor->PrepRequestProcessor->ProposalRequestProcessor(SyncRequestProcessor->AckRequestProcessor)->CommitProcessor-> Leader.ToBeAppliedRequestProcessor->FinalRequestProcessor |
| FollowerZooKeeperServer | FollowerRequestProcessor-> CommitProcessor->FinalRequestProcessor;SyncRequestProcessor->SendAckRequestProcessor |
| ObserverZooKeeperServer | ObserverRequestProcessor->CommitProcessor->FinalRequestProcessor;SyncRequestProcessor |
| ReadOnlyZooKeeperServer | ReadOnlyRequestProcessor->PrepRequestProcessor->FinalRequestProcessor |
Follower RequestProcessor Chain:

Leader RequestProcessor Chain:

ProposalRequestProcessor:
- 将请求转发到下一个requestProcessor;
- 如果是事务请求,向follower发送proposal请求,成功后,调用SyncRequestProcessor将请求持久化到本地;
CommitProcessor:处理client请求或leader发起的commit请求;
- 将请求提交到后续RequestProcessor进行处理,根据请求的sessionId将请求分配给worker线程,因此同一个sessionId的读请求和写请求会分配给同一个worker线程,保证了请求的顺序性;请求最终由nextProcessor进行处理;
SyncRequestProcessor:将请求批量持久化到本地,如果有nextProcessor,再将请求转发给nextProcessor;
- leader端,如果是事务性请求,leader将proposal发送到follower后,调用syncRequestProcessor处理;
- follower端,follower收到leader发送的proposal请求后,将请求添加到队列中,由syncRequestProcessor处理;
- 滚动事务文件,将sessions和datatree保存至snapshot文件;
SendAckRequestProcessor:learner发送ack请求到leader;
AckRequestProcessor:
- leader处理ack请求,向所有follower发送commit请求,同时也通知所有observer;
- 请求入队列,由CommitProcessor进行处理,最终由FinalRequestProcessor进行本地持久化调用;
FollowerRequestProcessor:将请求转发到下一个RequestProcessor,对于事务请求,同时会将请求发给leader;
FinalRequestProcessor:执行实际的查询和事务请求;
Server - Client交互
1. 请求处理基本流程
-
ServerCnxnFactory接收客户端请求;
- readable
- 连接请求
- 如果请求sessionId为0,则新建session
- 否则首先关闭sessionId对应的session,再重新打开
- 其他请求
- 读请求
- 写请求
- 连接请求
- writeable
- 服务端结果响应
- readable
-
ServerCnxnFactory将客户端请求提交给RequestProcessor进行处理;
NIOServerCnxnFactory:
NIOServerCnxn
AcceptThread(接收客户端连接请求) -> SelectorThread(接收客户端io请求) -> WorkerService(执行具体io操作)
ConnectionExpirerThread(关闭过期连接)
NettyServerCnxnFactory:
NettyServerCnxn
CnxnChannelHandler(处理客户端请求)
2. session管理
session设计:
zookeeper session设计,主要出于2方面考虑。
- 为了满足临时节点的问题,当session断开时,需要将关联的临界节点都删除。
- 同一个client连接服务端进行的操作,必需顺序执行,通过同样的sessionid将请求交由同一个线程进行处理,保证了请求的顺序执行。
- 服务端接收到客户端连接请求时,创建session;
- 由SessionTracker维护对session的操作,包括检测过期的session,调用SessionExpirer关闭session;
SessionTracker
session管理,负责过期session的检测,以及调用session清除方法;
SessionExpirer
提交session关闭请求,关闭session;
LocalSession:通过localSessionsEnabled在配置文件中配置;
1. 创建
客户端与服务端建立连接后,发送ConnectRequest到服务端,服务端接收到请求后,创建session,设置owner为当前LearnerHandler(一个LearnerHandler对应一个Learner);
如果请求的zxid大于服务端lastProcessedZxid,返回连接异常,客户端需要连接其他服务器;
如果连接请求自带的sessionid=0,则创建新的session,否则校验sessionId和passwd是否合法,是则重新激活对应的session,设置session owner为连接的服务器;
2. 激活
session激活:
- 客户端访问follower,follower会更新本地session过期时间;在follower响应leader的ping请求时,会将本地session过期时间同步给leader;
- 客户端访问leader,直接更新session过期时间;
session激活时,重新计算过期时间,将session转移到新的过期时间对应的桶中,SessionTracker.touchSession;
3. 过期
session过期策略:分桶,每个桶以过期时间为id,关联一系列过期时间相同的session;
执行过期超过时,发送closeSession请求,删除内存数据库中该sessionId关联的所有临时节点;
4. 校验
对于客户端的事务请求,由PrepRequestProcessor校验session的有效性,服务端可能返回SessionExpiredException和SessionMovedException异常(由于网络原因,session未过期,但客户端与新的服务器建立了连接);
http://www.leexide.com/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/zookeeper/651.html
3. 写数据
Leader处理:
Leader将需要发送的Proposal入队列,由LearnerHandler启动的独立线程获取并发送给Follower;
LearnerHandler同时监听Follower的ACK请求,收到响应后加入投票队列,判断当前收到的投票是否已满足多数;满足则将发送commit请求给follower,同时通知observer,最后本机提交当前Proposal;否则继续等待响应;
Follower处理:
事务请求转发到Leader;
收到Leader的Proposal请求时,等待写磁盘,写成功后,发送ACK响应;
收到commit请求时,本地提交该Proposal;
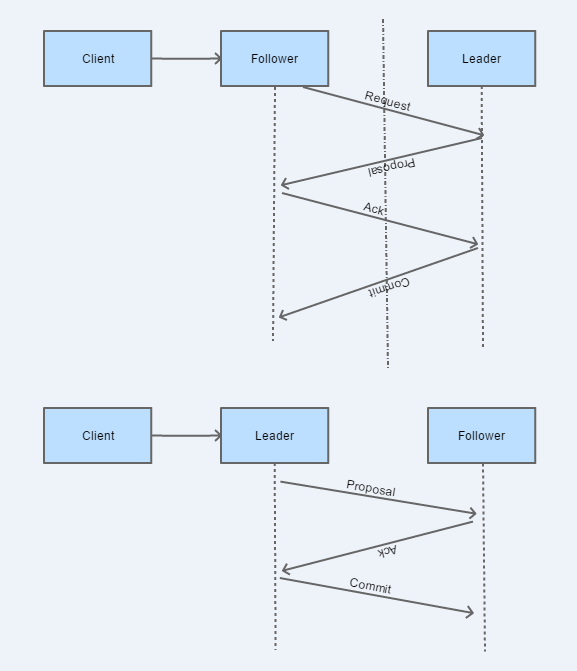
ZooKeeper请求处理流程:
http://blog.csdn.net/u011277123/article/details/53637037
4. 读数据
leader/follower接收到client读请求后,返回请求结果;
5. Watcher管理
zookeeper维护2各watch列表,节点数据的watch和子节点的watch;
watcher是一次性监听,触发后需要重新设置监听;
异步通知;
- watcher触发
| Trigger | EventType | Watches |
|---|---|---|
| setData/reconfig | EventType.NodeDataChanged | path |
| create | EventType.NodeCreated | path |
| create | EventType.NodeChildrenChanged | parent_path |
| delete/deleteContainer | EventType.NodeDeleted | path |
| delete/deleteContainer | EventType.NodeChildrenChanged | parent_path |
- watcher设置
| Trigger | Watches |
|---|---|
| getChildren/getChildren2 | child_path |
| getData | path |
| setWatches | path |
| exists | path |
note:上述内容是个人学习zookeeper源码后的理解,难免有不当之处,欢迎交流。