Flume的官网地址:http://flume.apache.org/FlumeUserGuide.html#exec-source
source,sink,channel:https://www.iteblog.com/archives/948
简介Flume:
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输系统,Flume提供在日志采集系统中定制各类的数据发送方,用于接收数据,同时提供对数据进行简单的处理,并写到各个数据接收方中的过程。
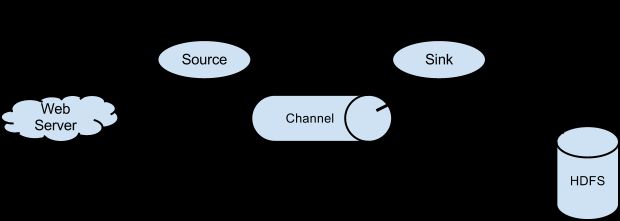
流程结构:
Flume的主要结构分为三部分:source,channel,sink;其中source是源头,负责采集日志;channel是管道,负责传输和暂时的存储;sink为目的地,将采集的日志保存起来;
根据需求对Flume的三部分进行组合,构成一个完整的agent,处理日志的传输;PS:agent为flume处理消息的单位,数据经过agent进行传输。
具体配置:
(启动flume的服务要安装JDK)
source:包括的配置为{Avro,Thrift,Exec,Spooling,...}
sink:包括的配置为{HDFS,Hive,Avro,Thrift,Logger,...}
channel:包括的配置为{Memory,JDBC,Kafka,File,...}
PS:具体的配置参考Flume的官网进行查询;
一个简单的Flume的配置为:
Sample example:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1 #定义数据的入口
a1.sinks = k1 #定义数据的出口
a1.channels = c1 #定义管道
# Describe/configure the source
a1.sources.r1.type = netcat #定义数据源的类型
a1.sources.r1.bind = localhost #监听地址
a1.sources.r1.port = 44444 #监听端口
# Describe the sink
a1.sinks.k1.type = logger #定义数据出口,出口类型
# Use a channel which buffers events in memory
a1.channels.c1.type = memory #临时存储文件的方式
a1.channels.c1.capacity = 1000 #存储大小
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 #配置连接的方式
a1.sinks.k1.channel = c1
source源的配置:(常见配置)
1.Avro配置:需要配置-channels,type,bind,port四组参数;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro #type为组件的名称,需要填写avro,avro方式使用RPC方式接收,故此需要端口号
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.bind = 0.0.0.0#限制接收数据的发送方ID,0.0.0.0是接收任何IP,不做限制
a1.sources.r1.port = 4141 #接收端口(与flume的客户端的sink相呼应)
Avro的配置的话需要:需要在客户端和接收端都要配置相应的Avro配置才可。
2.exec source配置:可以通过指定操作对日志进行读取,使用exec时需要指定shell命令,对日志进行读取;exce的配置就是设定一个Linux命令,通过这个命令不断的传输数据;我们使用命令去查看tail -F 命令去查看日志的尾部;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exce #type为组件的名称,采用命令行的方式进行读取数据
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.command = tail -F /var/log/secure #监控查看日志的尾部进行输出的操作
3.spooling-directory source配置:spo_dir可以读取文件夹里的日志,使用时指定一个文件夹,可以读取文件夹中的所有文件,该文件夹下的文件不可以进行再打开编辑的操作,spool的目录下不可包含相应的子目录;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = spooldir #type为组件的名称,需要填写spooldir为spool类型
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.spoolDir = /home/hadoop/flume/logs #spool接收的目录信息
4.Syslogtcp source配置:Syslogtcp监听tcp端口作为数据源;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = syslogtcp #type为组件的名称,需要填写syslogtcp,监听端口号dd
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.port = 5140 #端口号
a1.sources.r1.host = localhost #发送方的IP地址
5.HTTP Source配置:是HTTP POST和GET来发送事件数据,使用Hander程序实现转换;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = http #type为组件的名称,需要填写http类型
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.handler= org.example.rest.RestHandler
a1.sources.r1.handler.nickname=random.props
sink源的配置:(常见配置)
sink会消费channel中的数据,然后送给外部数据源或者source;
1.Hive sink:hive的数据是只限制了text和JSON数据直接在hive的表中或partition中;
hive的sink的主要参数详解:
type:构建的类型的名字,此处填写hive;
hive.metastore:Hive metastore的URL;
hive.database:Hive database 名字;
hive table:Hive table名字;
使用hive的额话需要进行先创建表的过程:
create table weblogs ( id int , msg string )
partitioned by (continent string, country string, time string)
clustered by (id) into 5 buckets
stored as orc;
a1.channels = c1
a1.channels.c1.type = memory
a1.sinks = k1
a1.sinks.k1.type = hive
a1.sinks.k1.channel = c1
a1.sinks.k1.hive.metastore = thrift://127.0.0.1:9083
a1.sinks.k1.hive.database = logsdb
a1.sinks.k1.hive.table = weblogs
a1.sinks.k1.hive.partition = asia,%{country},%y-%m-%d-%H-%M
a1.sinks.k1.useLocalTimeStamp = false
a1.sinks.k1.round = true
a1.sinks.k1.roundValue = 10
a1.sinks.k1.roundUnit = minute
a1.sinks.k1.serializer = DELIMITED
a1.sinks.k1.serializer.delimiter = "\t"
a1.sinks.k1.serializer.serdeSeparator = '\t'
a1.sinks.k1.serializer.fieldnames =id,,msg
2.Logger Sink:Logs是INFO level,This sink is the only exception which doesn’t require the extra configuration explained in the Logging raw data section.
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
3.Avro Sink:
需要配置hostname和port,需要在两端都要安装Avro的客户端:
type:组件名称,此处填写Avro;
hostname和port:填写地址;
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 10.10.10.10
a1.sinks.k1.port = 4545
4.Kafka Sink:
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
Channel 配置:(常见配置)
1.Memory Chanel:
使用Memory作为中间的缓存;
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
2.JDBC Channel:
a1.channels = c1
a1.channels.c1.type = jdbc
3.Kafka Channel:
a1.channels.channel1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.channel1.kafka.bootstrap.servers = kafka-1:9092,kafka-2:9092,kafka-3:9092
a1.channels.channel1.kafka.topic = channel1
a1.channels.channel1.kafka.consumer.group.id = flume-consumer
4.File Channel:
a1.channels = c1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /mnt/flume/checkpoint
a1.channels.c1.dataDirs = /mnt/flume/data
source源的配置:(常见配置)
1.Avro配置:需要配置-channels,type,bind,port四组参数;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro #type为组件的名称,需要填写avro,avro方式使用RPC方式接收,故此需要端口号
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.bind = 0.0.0.0#限制接收数据的发送方ID,0.0.0.0是接收任何IP,不做限制
a1.sources.r1.port = 4141 #接收端口(与flume的客户端的sink相呼应)
Avro的配置的话需要:需要在客户端和接收端都要配置相应的Avro配置才可。
2.exec source配置:可以通过指定操作对日志进行读取,使用exec时需要指定shell命令,对日志进行读取;exce的配置就是设定一个Linux命令,通过这个命令不断的传输数据;我们使用命令去查看tail -F 命令去查看日志的尾部;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exce #type为组件的名称,采用命令行的方式进行读取数据
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.command = tail -F /var/log/secure #监控查看日志的尾部进行输出的操作
3.spooling-directory source配置:spo_dir可以读取文件夹里的日志,使用时指定一个文件夹,可以读取文件夹中的所有文件,该文件夹下的文件不可以进行再打开编辑的操作,spool的目录下不可包含相应的子目录;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = spooldir #type为组件的名称,需要填写spooldir为spool类型
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.spoolDir = /home/hadoop/flume/logs #spool接收的目录信息
4.Syslogtcp source配置:Syslogtcp监听tcp端口作为数据源;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = syslogtcp #type为组件的名称,需要填写syslogtcp,监听端口号dd
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.port = 5140 #端口号
a1.sources.r1.host = localhost #发送方的IP地址
5.HTTP Source配置:是HTTP POST和GET来发送事件数据,使用Hander程序实现转换;
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = http #type为组件的名称,需要填写http类型
a1.sources.r1.channels = c1 #匹配agent创建的channel即可
a1.sources.r1.handler= org.example.rest.RestHandler
a1.sources.r1.handler.nickname=random.props
sink源的配置:(常见配置)
sink会消费channel中的数据,然后送给外部数据源或者source;
1.Hive sink:hive的数据是只限制了text和JSON数据直接在hive的表中或partition中;
hive的sink的主要参数详解:
type:构建的类型的名字,此处填写hive;
hive.metastore:Hive metastore的URL;
hive.database:Hive database 名字;
hive table:Hive table名字;
使用hive的额话需要进行先创建表的过程:
create table weblogs ( id int , msg string )
partitioned by (continent string, country string, time string)
clustered by (id) into 5 buckets
stored as orc;
a1.channels = c1
a1.channels.c1.type = memory
a1.sinks = k1
a1.sinks.k1.type = hive
a1.sinks.k1.channel = c1
a1.sinks.k1.hive.metastore = thrift://127.0.0.1:9083
a1.sinks.k1.hive.database = logsdb
a1.sinks.k1.hive.table = weblogs
a1.sinks.k1.hive.partition = asia,%{country},%y-%m-%d-%H-%M
a1.sinks.k1.useLocalTimeStamp = false
a1.sinks.k1.round = true
a1.sinks.k1.roundValue = 10
a1.sinks.k1.roundUnit = minute
a1.sinks.k1.serializer = DELIMITED
a1.sinks.k1.serializer.delimiter = "\t"
a1.sinks.k1.serializer.serdeSeparator = '\t'
a1.sinks.k1.serializer.fieldnames =id,,msg
2.Logger Sink:Logs是INFO level,This sink is the only exception which doesn’t require the extra configuration explained in the Logging raw data section.
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
3.Avro Sink:
需要配置hostname和port,需要在两端都要安装Avro的客户端:
type:组件名称,此处填写Avro;
hostname和port:填写地址;
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 10.10.10.10
a1.sinks.k1.port = 4545
4.Kafka Sink:
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
Channel 配置:(常见配置)
1.Memory Chanel:
使用Memory作为中间的缓存;
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
2.JDBC Channel:
a1.channels = c1
a1.channels.c1.type = jdbc
3.Kafka Channel:
a1.channels.channel1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.channel1.kafka.bootstrap.servers = kafka-1:9092,kafka-2:9092,kafka-3:9092
a1.channels.channel1.kafka.topic = channel1
a1.channels.channel1.kafka.consumer.group.id = flume-consumer
4.File Channel:
a1.channels = c1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /mnt/flume/checkpoint
a1.channels.c1.dataDirs = /mnt/flume/data