编程范式巡礼第二季 并发那些事
继续上周的编程范式话题,今天想聊一下并发范式。
并发也算一种范式?
真正的并发式编程,绝不只是调用线程API或使用synchronized、lock之类的关键字那么简单。从宏观的架构设计,到微观的数据结构、流程控制乃至算法,相比通常的串行式编程都可能发生变化。毫不夸张的说,是又一场思想和技术上革命。
在日常开发中,并发编程难度是比较高的,属于高级程序员才能掌握的内容。其难点在哪里,我们日常习惯的是线性思维,这与并发编程的多维世界观是不同的,提升思考的维度无疑是艰难。但还好,在大神们的努力下,已逐渐化繁为简,这也是并发范式带来的力量。在并发领域有许多的模型,让我们来巡礼一下。
模型1:线程与锁
并发编程以资源共享和竞争为主线。这意味着程序设计将围绕进程的划分与调度、进程之间的通信与同步等来展开。合理的并发式设计需要诸多方面的权衡考量。
线程是对底层硬件过程的形式化,是并发编程的核心。不同的线程各自独立运行,有如一个个的平行宇宙。但是,并发编程并不仅仅串行化编程的叠加,主要的差异在于,线程之间存在共享和竞争。共享资源会带来哪些问题呢?
- 问题1:脏读
当线程1对共享数据进行修改时,线程2有可能会读到处于中间状态的数据,这个问题称之为脏读。
解决的思路比较简单,就是让线程1仅提交最终修改结果,在修改过程中产生并使用快照数据。这种类似影分身的技术称之为MVCC(Multi-Version Concurrency Control)。
- 问题2:丢失更新
当线程1对数据进行修改时,如果线程2同时修改,由于采用了MVCC,双方各自无法看到,那最终提交时,很可能会造成其中一个线程结果与预期不一致,这个问题称为丢失更新。
其解决方法是加锁,在修改前进行加锁,一旦占用,则第二个线程无法获取。
脏读和丢失更新是需要同时考虑的,所以标准的多线程处理是同时使用到了MVCC和锁这两个技术。
- 问题3:幻读
在已解决了丢失更新和脏读的情况下,下面要考虑多次读取的情况。如下图所示,线程1对数据集进行了多次读取,但是部分数据在线程2中进行了更新,这时候出现了线程1在没有任何作为的情况下,两次读取不一致的情况!!!这个问题称为幻读。
解决幻读的方法是扩大数据的锁范围,不仅仅是更改过的记录,所有读取的记录都要加锁。
- 综述
这就是目前我们最主流的并发与锁的实现思路方法,有非常广泛的使用。不知道大家读完这段的感觉怎么,我看的时候,第一个感觉是复杂,真的非常的烧脑,由于大量概念的堆积对于初学者来说非常不友好;第二个感觉是矛盾,按照最终幻读的解决方案,实际上就是放弃了程序间的并行,绕了一圈,又回到了原点。正因为如此,目前主流的数据库,实际上默认都是放弃对于幻读问题解决的,这也是开发上的一大坑。
综合的来看,这种解决方式学习成本很高,而且还没能解决全部的问题,并不能让人满意。有没有更好点的方法,让我们继续。
模型2:函数式编程与Lambda架构
传统并发模型中,最令人纠结的无疑就是共享数据访问这块了。若不爽,就另辟蹊径。我们能不能不对共享数据进行写入呢?有什么样的程序是只读不写的呢,大神们已经找到了答案,就是上周介绍的函数式编程。
首先想说明的事,纯函数式的编程功能上并不完备,有非常多的缺陷,但其有一个天然的适用场景,就是数学运算分析,也就是我们现在时常挂在嘴边的大数据计算。
由于抛弃掉了共享状态,其代码的健壮性和扩展性得到了大大的增强,只要有足够的计算资源就可以处理无限大的数据。
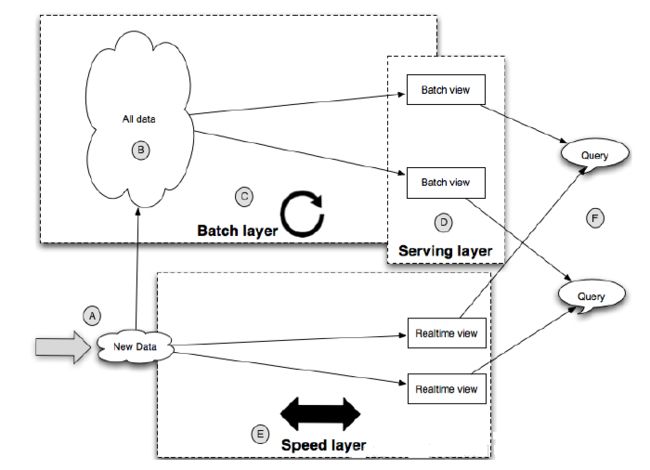
函数式编程思维比较数学化,难度是比较高的,在此基础上,诞生了Lambda框架,是对应用模式的固化,有助于降低学习成本和大范围推广。Lambda框架既使用了可以进行大规模批处理的MapReduce技术,也使用了可以快速处理数据并及时反馈的流处理技术,这样的混搭能够为大数据问题提供扩展性、响应性和容错性都能优秀的解决方案。
Lambda架构也可以这样来描述:在该架构中,被读取的数据是不可变的,在并行处理过程中数据会依次进入批处理系统(batch system)与流处理系统。从逻辑上看,传输过程发生了两次,一次是在批处理中,一次是在流处理中。在查询时,当这两者都返回结果后,才算是完成一次完整的查询。
模型3:Actor
函数式编程模型的应用使得并发编程的应用踏入了工业级,带动了大数据的热潮。但是其解决思路是抛弃了可变状态,服务是有损的。对于必须提供无损服务的场景该如何进行改进呢。
从最一开始线程与锁的模型中,我们可以看到串行化是最重的解决方案,但是为了串行化,我们需要MVCC、锁等一系列的工具,比较复杂,Actor模型就是用来简化此类操作的。
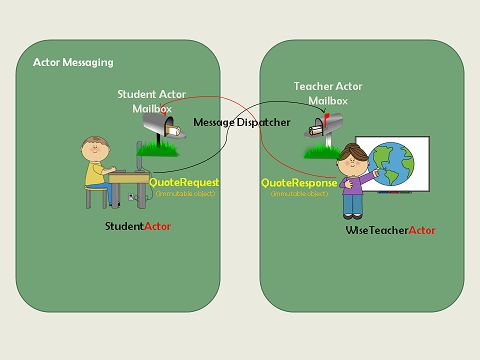
Actor模型中抽象出了两个概念Actor和Mailbox,Actor就是指代共享数据,Mailbox管理数据的操作。对于每个Actor的操作,要通过mailbox来进行,在mailbox端实现了队列的控制,从而实现了序列化的效果。
Actor模型会带来一些额外的好处:
- 用Actor来定义共享数据,边界非常清晰,实现了与主线代码的解耦,最大化减少了序列化的影响,可以有效提升性能。
- Actor中引入了消息的概念,是位置透明的,天然支持了分布式的部署。
- 在概念清晰之后,代码得到了简化,下面摘录一段Actor的代码,可以看到是封装了并发相关的技术细节,非常的简洁。
class Pong extends Actor {
def act() {
var pongCount = 0
while (true) {
receive {
case Ping =>
if (pongCount % 1000 == 0)
Console.println("Pong: ping " + pongCount)
sender ! Pong
pongCount = pongCount + 1
case Stop =>
Console.println("Pong: stop")
exit()
}
}
}
}
模型4:原子变量
很多情况下我们需要一个高效的、线程安全的并发解决方案。高效意味着耗用资源要少,程序处理速度要快;线程安全也非常重要,这个在多线程下能保证数据的正确性。有一个解决方案是原子变量。
通常情况下,在Java里面,++i或者--i不是线程安全的,这里面有三个独立的操作:获得变量当前值,为该值+1/-1,然后写回新的值。在没有额外资源可以利用的情况下,只能使用加锁才能保证读-改-写这三个操作是“原子性”的。
下面是示例代码:
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
在这里采用了CAS操作,每次从内存中读取数据然后将此数据和+1后的结果进行CAS操作,如果成功就返回结果,否则重试直到成功为止。而compareAndSet利用JNI来完成CPU指令的操作。
原子变量在一些对性能有极端要求的系统中(比如Jetty、Tomcat)有非常广泛的应用,是一种精益求精的体现,其在可靠性和性能方面表现很突出,但在易用性方面比较偏计算机思维,理解难度较大,并不够简洁,需要反复练习才能掌握。
小结
在今天的篇文章中,列举了并发范式的四个主流模型:线程与锁、函数式编程、Actor、原子变量。可以看到,每个模型都是在功能、性能和易用之间寻求了一种平衡,并没有一种模型在功能、性能和易用三方面同时达到最优,也就是说没有银弹。
这是我们面对并发问题时的困境,也是挑战,也正说明了并发并不是一个简单的线性问题,我们需要针对具体场景、具体问题进行分析,寻找最适合的解决方法,这也是开发人员需要养成的一种重要素养。