服务端创建步骤
步骤1.创建ServerBootstrap实例,ServerBootStrap是Netty服务端的启动辅助类,它提供了一系列的方法用于设置服务端启动的相关参数。底层通过门面模式对各种功能进行抽象和封装。ServerBootStrap只有一个无参的构造函数,是因为它的参数太多,而且未来会发生变化,所以引入了Builder模式。
步骤2.设置并绑定Reactor线程池-EventLoopGroup,负责处理所有注册到被线程多路复用器Selector上的Channel,Selector的轮询操作由绑定的EventLoop线程run方法驱动。
步骤3.设置并绑定服务端Channel。利用工厂类,通过反射创建NioServerSocketChannel对象。
步骤4.链路建立的时候创建并初始化ChannelPipeline。ChannelPipeline本质就是一个负责处理网络事件的职责链,负责管理和执行Channelhandler.网络事件以事件流的形式在ChannelPipeline中流转,根据ChannelHandler的执行策略调度ChannelHandler的执行-------采用策略模式和责任链模式。
步骤5。添加并设置Channelhandler.采用适配器模式,用户可以添加自己的实现,完成大多数的功能定制。----适配器模式。
步骤6:绑定并启动箭筒端口。
步骤7:Selector轮询。由Reactor线程NioEventLoop负责调度和执行Selector轮询操作,选择准备就绪的Channel集合。
步骤8:当轮询到准备就绪的Channel之后,就由Reactor线程执行ChannelHandler
ByteBuf源码精读
1.传统java的NIO的byteBuffer的缺点?
第一,ByteBuffer长度固定,一旦分配完成,它的容量不能动态扩展和收缩,当需要编码的POJO对象大于ByteBuffer的容量时,会发生索引越界异常;
第二,ByteBuffer只有一个标识位置的指针position,读写的时候需要手工调用flip()和rewind()等,使用者必须小心谨慎的处理这些API
第三,ByteBuffer的API功能有限,一些高级和实用的特性它不支持,需要使用者自己编程实现。
ByteBuf的实现原理图

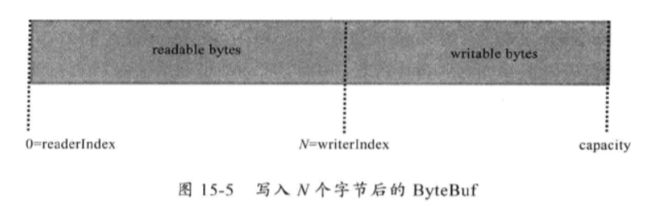




ByteBuf对于内存的使用情况描述?
从内存分配的角度看,ByteBuf可以分为两类:
第一类,堆内存(HeapByteBuf)字节缓冲区:特点是内存的分配和回收速度快,可以被JVM自动回收;缺点是如果进行Socket的I/O读写,需要额外做一次内存复制,将堆内存对应的缓冲区复制到内核Channel中,性能会有一定程度的下降
第二类,直接内存(DirectByte)字节缓冲区:非堆内存,它在堆外进行内存分配,相比于堆内存,它的分配和回收速度会慢一些,但是将它写入或者读取时,由于少了一次内存复制,速度比堆内存块。
总结:在IO通信线程的读写缓冲区使用直接内存,后端业务消息的编解码模块使用HeapByteBuf。
从内存回收角度看,ByteBuf也可分为两类
第一类:基于对象池的ByteBuf,可以重用ByteBuf对象,它自己维护了一个内存池,可以循环利用创建的ByteBuf,提升内存的使用效率,降低由于高负载导致的频繁GC。但是内存池的管理和维护更加复杂,使用起来更加谨慎。
第二类:普通ByteBuf。
ByteBuf的动态扩容
动态扩展缓冲区的原理,是新建一个更大的缓冲区,把在原来缓冲区的内容复制到新的缓冲区,然后就有更大的空间可以写入了。中间涉及内存的分配和内存复制,所以扩容的成本较高。
netty缓存扩容的策略一方面要让扩容能满足后面写入的需求,不能扩容之后,马上缓冲区又被填满,又需要再一次的扩容。另一方面不能一次性扩容太多,导致内存浪费。所以一般是先倍增,再步增,举个例子,原来缓存区1M,扩容到2M,再扩容到4M,再扩容到8M,如果再继续倍增,那扩容的内存就太多了,之后就采取每次扩容4M的方式,扩容到12M,再扩容到16M。
PooledByteBuf内存池原理
为了集中管理内存的分配和释放,同时提高分配和释放内存时候的性能,很多框架和应用都会通过预先申请一大块内存,然后通过提供的分配和释放接口来使用内存。这样一来,对内存的管理就被集中到几个类或者函数中,由于不再频繁使用系统调用来申请和释放内存,应用或者系统的性能也会大大提高。在这种设计思路下,预先申请的那一块内存就被成为Memmory Arena。
不同的框架,Memory Arena的实现不同,Netty的PoolArena是由多个chunk组成的大块内存区域,而每个chunk则由一个或者多个page组成,因此,对内存的组织和管理也就主要集中在如何管理和组织Chunk和Page上了。
Chunk主要用来组织和管理多个page的内存分配和释放,在Netty中,Chunk中的Page被构建成一颗二叉树。假设一个Chunk由16个page组成,name这些P啊啊个将会按照如下分布。

当一个节点被分配出去之后,这个节点就会被标记为已分配,自这个节点以下所有节点在后面的内存分配中被忽略,采用深度优先算法。
ChannelPipeline和ChannelHandler
这种机制类似于Servlet和Filter过滤器,这类拦截器实际上是职责链模式的一种变形,主要是为了方便时间的拦截和用户业务逻辑的定制。它将Channel的数据管道抽象为ChannelPipeline,消息在ChannelPipeline中流动和传递。ChannelPipeline持有IO事件拦截器ChannelHandler,由ChannelHandler对IO事件进行拦截和处理,可以方便得通过新增和删除ChannelHandler来实现不同业务逻辑定制。
EventLoop和EventLoopGroup
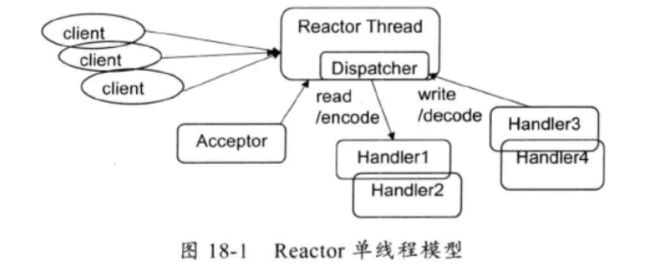
1.Reactor线程模型-单线程模型。
所有的IO操作都在同一个NIO线程上面完成。模型如下
2.Reactor线程模型-多线程模型,有一组NIO线程来处理IO操作。
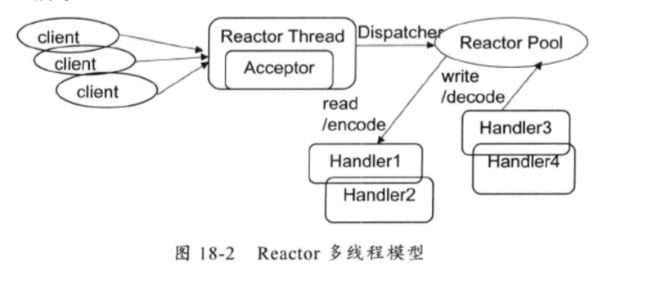
多线程模型的特点:第一有专门一个NIO线程Accpetor线程用于监听服务端,接受客户端的TCP连接请求;第二读写由一个NIO线程池负责,线程池可以采用标准的JDK线程池实现;第三一个NIO线程可以同时处理N条链路,但是一个链路对应一个NIO线程。
主从Reactor多线程模型
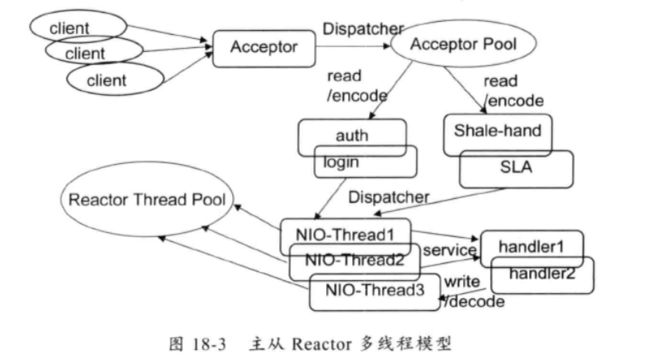
主从Reactor多线程模式的特点:服务端用于就收客户端连接的不再是一个单独的NIO线程,而是一个单独的NIO线程池。Accptor接受到客户端TCP连接请求并处理完成后,将新创建的SocketChannel注册到IO线程池的某个IO线程上。Acceptor线程池仅仅用于客户端的登录,握手和安全认证,一旦链路建立成功,就将链路注册到后端subReactor线程池的IO线程上。
2.Netty的线程模型
Netty的线程模型并不是一成不变的,它实际取决于用户启动参数的配置。通过设置不同的启动参数,Netty可以同时支持Reactor单线程模型、多线程模型和主从Reactor多线程模型。
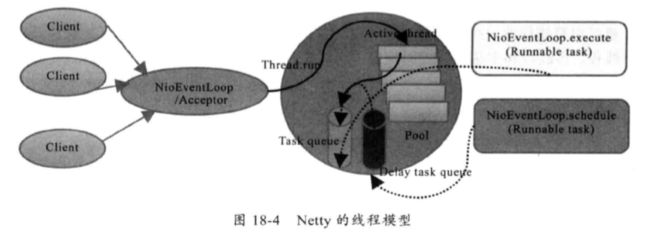
服务端启动的时候,创建了两个NioEventLoopGroup,他们实际上是两个独立的Reactor线程池,一个用于接受客户端的TCP连接,另一个用于处理IO相关的读写操作,或者执行系统Task、定时任务Task等。通过调整线程池个数、是否共享线程池等方式,Netty的Reactor线程模型可以在单线程、多线程和主从线程间切换。
3.NioEventLoop的主要任务
第一、负责IO的读写
第二、创建系统Task,通过调用NioEventLoop的execute方法实现,Netty有很多系统Task,创建他们的主要原因是:当IO线程和用户线程同时操作网络资源时,为了防止并发操作导致的锁竞争,将用户线程的操作封装成Task放入消息队列中,由IO线程负责执行,这样就实现了局部无锁化。
第二、定时任务。