由于采用了分表操作,原来mysql的AUTO_INCREMENT这个就不能使用了。这里就是看看shardingjdbc的id生成规则。
首先shardingjdbc中有一个接口KeyGenerator,然后将实现这个接口,并且实现generateKey()这个方法。
import com.dangdang.ddframe.rdb.sharding.keygen.DefaultKeyGenerator;
import com.dangdang.ddframe.rdb.sharding.keygen.KeyGenerator;
public class ShardingIDConfig implements KeyGenerator{
@Override
public Number generateKey() {
DefaultKeyGenerator defaultKeyGenerator = new DefaultKeyGenerator();
return defaultKeyGenerator.generateKey();
}
}
KeyGenerator这个接口
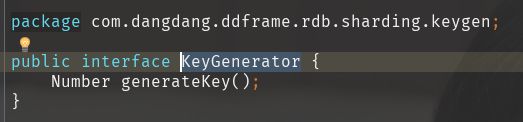
里面只有一个返回Number的
generateKey()
然后Ctrl+Alt+B看它的实现类

进入DefaultKeyGenerator
其他的先不看,主要看 generateKey()
@Override
public synchronized Number generateKey() {
//获取当前时间戳
long currentMillis = timeService.getCurrentMillis();
//判断this.lastTime <= currentMillis,如果true,下一步,如果false,抛出IllegalStateException
Preconditions.checkState(this.lastTime <= currentMillis, "Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", new Object[]{this.lastTime, currentMillis});
//当this.lastTime == currentMillis相当时,
if (this.lastTime == currentMillis) {
//4095L的二进制是0000111111111111
if (0L == (this.sequence = ++this.sequence & 4095L)) {
//获取下一个时间戳
currentMillis = this.waitUntilNextTime(currentMillis);
}
} else {
this.sequence = 0L;
}
//将currentMillis赋值给this.lastTime
this.lastTime = currentMillis;
if (log.isDebugEnabled()) {
log.debug("{}-{}-{}", new Object[]{(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")).format(new Date(this.lastTime)), workerId, this.sequence});
}
//最主要这里怎么操作的,每次最后一位都是偶数,弄得我有点烦躁,首先看一下运算符的顺序 (-)大于(<<)大于(|)
//先用currentMillis-EPOCH,得到时间差,左移22位,workerId左移12位,这样一弄必须是偶数了
//还有就是<<22和<<12这两个数有啥含义,没想明白
return currentMillis - EPOCH << 22 | workerId << 12 | this.sequence;
}
//获取下一个时间戳
private long waitUntilNextTime(long lastTime) {
long time;
for(time = timeService.getCurrentMillis(); time <= lastTime; time = timeService.getCurrentMillis()) {
;
}
return time;
}
//类初始化的时候EPOCH就确定了
static {
Calendar calendar = Calendar.getInstance();
calendar.set(2016, 10, 1);
calendar.set(11, 0);
calendar.set(12, 0);
calendar.set(13, 0);
calendar.set(14, 0);
EPOCH = calendar.getTimeInMillis();
}
现在的问题就是每次获得的Number.longVaule()都是偶数,和我之前设计表的奇偶数插入不同的表冲突了。
需要重写这句return currentMillis - EPOCH << 22 | workerId << 12 | this.sequence;
没办法,只能通过右移去判断是不是奇偶数。
在sharding.yml中将algorithmExpression: user${id.longValue() %2 }修改为algorithmExpression: user${(id.longValue() >> 22) %2 }

这样就可以用sharding自带的分布式id了。没有具体的环境
在Controller中添加用户的时候用这个id。

snowflake生成的ID
/**
* Twitter_Snowflake
* SnowFlake的结构如下(每部分用-分开):
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
* 加起来刚好64位,为一个Long型。
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
*/
public class SnowflakeIdWorker {
// ==============================Fields===========================================
/** 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L;
/** 机器id所占的位数 */
private final long workerIdBits = 5L;
/** 数据标识id所占的位数 */
private final long datacenterIdBits = 5L;
/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** 支持的最大数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/** 序列在id中占的位数 */
private final long sequenceBits = 12L;
/** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits;
/** 数据标识id向左移17位(12+5) */
private final long datacenterIdShift = sequenceBits + workerIdBits;
/** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** 工作机器ID(0~31) */
private long workerId;
/** 数据中心ID(0~31) */
private long datacenterId;
/** 毫秒内序列(0~4095) */
private long sequence = 0L;
/** 上次生成ID的时间截 */
private long lastTimestamp = -1L;
//==============================Constructors=====================================
/**
* 构造函数
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
//==============================Test=============================================
/** 测试 */
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0);
for (int i = 0; i < 1000; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}
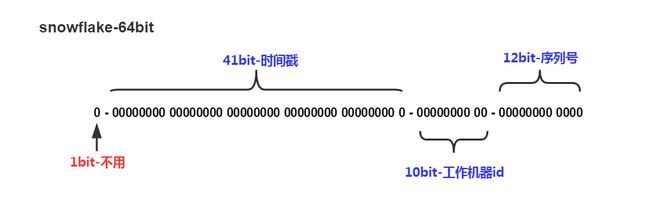
了解一下这个SnowflakeId的原理
snowflakeld的时钟回拨问题
在获取当前 Timestamp 时, 如果获取到的时间戳比前一个已生成 ID 的 Timestamp 还要小怎么办? Snowflake 的做法是继续获取当前机器的时间, 直到获取到更大的 Timestamp 才能继续工作 (在这个等待过程中, 不能分配出新的 ID)
从这个异常情况可以看出, 如果 Snowflake 所运行的那些机器时钟有大的偏差时, 整个 Snowflake 系统不能正常工作 (偏差得越多, 分配新 ID 时等待的时间越久)
从 Snowflake 的官方文档 (https://github.com/twitter/snowflake/#system-clock-dependency) 中也可以看到, 它明确要求 "You should use NTP to keep your system clock accurate". 而且最好把 NTP 配置成不会向后调整的模式. 也就是说, NTP 纠正时间时, 不会向后回拨机器时钟.
当然,这种分布式id方式有很多,比如说UUID,redis的EVAL和EVALSHA,instagram等等等。反正够我用的了。