随着计算机技术的飞速发展以及视频采集设备的大规模应用,对于计算机视觉的研究也受到越来越多的关注。目标跟踪作为计算机视觉领域中的关键技术之一,被广泛地应用于军事制导,视觉导航,机器人,智能交通,公共安全等领域。在本文中我使用了三种算法综合实现了对多车辆的跟踪任务。
Github:https://github.com/xiaochus/Vehicle_Tracking
PS:文章中代码可能不够完全,完整的代码结构参考github给出的文件。
算法
- 目标检测: MOG2
- 目标跟踪: KCF
- 物体分类: CNN
环境
- Python 3.6
- OpenCV 3.2 + contrib
- Tensorflow-gpu 1.0
- Keras 1.2
目标检测
我们使用MOG2进行当前帧的目标检测任务。MOG2是一种背景减除算法,在之前的文章中进行了介绍。目标检测的代码如下所示:
import sys
import copy
import argparse
import cv2
import numpy as np
from keras.models import load_model
from utils.entity import Entity
camera = cv2.VideoCapture(video)
res, frame = camera.read()
y_size = frame.shape[0]
x_size = frame.shape[1]
# 导入CNN分类模型
model = load_model('model//weights.h5')
bs = cv2.createBackgroundSubtractorMOG2(detectShadows=True) # 定义MOG2
history = 20 # MOG2训练使用的帧数
frames = 0 # 当前帧数
counter = 0 # 当前目标id
cv2.namedWindow("detection", cv2.WINDOW_NORMAL)
while True:
res, frame = camera.read()
if not res:
break
# 使用前20帧训练MOG2
fg_mask = bs.apply(frame)
if frames < history:
frames += 1
continue
# 对帧图像进行膨胀与去噪声操作
th = cv2.threshold(fg_mask.copy(), 244, 255, cv2.THRESH_BINARY)[1]
th = cv2.erode(th, cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3)), iterations=2)
dilated = cv2.dilate(th, cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (8, 3)), iterations=2)
# 获得目标位置
image, contours, hier = cv2.findContours(dilated, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
在遍历检测框时,我们使用面积3000作为阈值对检测框进行过滤,去掉过小的检测框,以减轻分类模型运行的次数。
在提取目标之后,我们先对其进行重置大小,去均值等操作,然后将其送入CNN模型,判断是否为车辆。如果当前目标为车辆,那么就与跟踪列表中的对象进行对比。这里我们对比两者的IOU,即重叠度,只有当前目标与列表中所有的目标的重叠度都很小时,才会将当前目标加入跟踪列表。
for c in contours:
x, y, w, h = cv2.boundingRect(c)
if cv2.contourArea(c) > 3000:
# 提取目标
img = frame[y: y + h, x: x + w, :]
rimg = cv2.resize(img, (64, 64), interpolation=cv2.INTER_CUBIC)
image_data = np.array(rimg, dtype='float32')
image_data /= 255.
roi = np.expand_dims(image_data, axis=0)
# 分类
flag = model.predict(roi)
if flag[0][0] > 0.5:
e = Entity(counter, (x, y, w, h), frame)
# 排除重复目标
if track_list:
count = 0
num = len(track_list)
for p in track_list:
if overlap((x, y, w, h), p.windows) < iou:
count += 1
if count == num:
track_list.append(e)
else:
track_list.append(e)
counter += 1
矩形框重叠度函数:
def overlap(box1, box2):
"""
检查两个矩形框的重叠程度.
"""
endx = max(box1[0] + box1[2], box2[0] + box2[2])
startx = min(box1[0], box2[0])
width = box1[2] + box2[2] - (endx - startx)
endy = max(box1[1] + box1[3], box2[1] + box2[3])
starty = min(box1[1], box2[1])
height = box1[3] + box2[3] - (endy - starty)
if (width <= 0 or height <= 0):
return 0
else:
Area = width * height
Area1 = box1[2] * box1[3]
Area2 = box2[2] * box2[3]
ratio = Area / (Area1 + Area2 - Area)
return ratio
在处理完新的物体后,我们对跟踪列表中的对象进行处理。如果对象的中心接近帧边界,那么就将其从列表中移除。如果没有,那么就对该对象进行更新操作,激活其跟踪器。
if track_list:
tlist = copy.copy(track_list)
for e in tlist:
x, y = e.center
if 10 < x < x_size - 10 and 10 < y < y_size - 10:
e.update(frame)
else:
track_list.remove(e)
目标跟踪
KCF(kernelized correlation filters),全称核相关滤波,是一种鉴别式追踪方法。这类方法一般都是在追踪过程中训练一个目标检测器,使用目标检测器去检测下一帧预测位置是否是目标,然后再使用新检测结果去更新训练集进而更新目标检测器。而在训练目标检测器时一般选取目标区域为正样本,目标的周围区域为负样本,当然越靠近目标的区域为正样本的可能性越大。
我们定义了一个实体类,该类为每一个被检测到的物体实例化一个对象。对象实例化时会初始化一个KCF跟踪器。KCF跟踪器接受一个帧与目标的坐标位置。通过update()函数载入最新的帧,KCF跟踪器能够计算目标在当前帧中所处的位置。
# coding:utf8
import cv2
import numpy as np
class Entity(object):
def __init__(self, vid, windows, frame):
self.vid = vid
self.windows = windows
self.center = self._set_center(windows)
self.trajectory = [self.center]
self.tracker = self._init_tracker(windows, frame)
def _set_center(self, windows):
x, y, w, h = windows
x = (2 * x + w) / 2
y = (2 * y + h) / 2
center = np.array([np.float32(x), np.float32(y)], np.float32)
return center
def _init_tracker(self, windows, frame):
"""
初始化KCF跟踪器
"""
x, y, w, h = windows
tracker = cv2.Tracker_create('KCF')
tracker.init(frame, (x, y, w, h))
return tracker
def update(self, frame):
"""
更新目标位置
"""
self.tracker.update(frame)
ok, new_box = self.tracker.update(frame)
if ok:
x, y, w, h = int(new_box[0]), int(new_box[1]), int(new_box[2]), int(new_box[3])
self.center = self._set_center((x, y, w, h))
self.windows = (x, y, w, h)
self.trajectory.append(self.center)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 1)
cv2.putText(frame, "vehicle", (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1, cv2.LINE_AA)
cv2.polylines(frame, [np.int32(self.trajectory)], 0, (0, 0, 255))
分类数据
我们使用MIT的车辆与行人数据训练分类模型,数据为ppm格式,大小分别为128X128与128X64。为了使用数据统一并且符合CNN模型的输入,我们对其进行了处理操作,统一了大小。
# coding: utf8
import os
import cv2
def main():
path1 = 'cars128x128//'
path2 = 'pedestrians128x64//'
path3 = 'data//train//cars//'
path4 = 'data//train//pedestrians//'
for root, dirs, files in os.walk(path1):
for f in files:
n = f.split('.')[0]
img = path1 + f
image = cv2.imread(img)
resized_image = cv2.resize(image, (64, 64), interpolation=cv2.INTER_CUBIC)
cv2.imwrite(path3 + str(n) + '.jpg', resized_image)
for root, dirs, files in os.walk(path2):
for f in files:
n = f.split('.')[0]
img = path2 + f
image = cv2.imread(img)
resized_image = cv2.resize(image, (64, 64), interpolation=cv2.INTER_CUBIC)
cv2.imwrite(path4 + str(n) + '.jpg', resized_image)
if __name__ == '__main__':
main()
点击下载原始数据与处理好的数据。
CNN分类模型
我们使用了3层的CNN网络作为分类模型,每个卷积单元由卷积层、BN层、LeakyRelu与池化层组成。如下图:

CNN网络使用Keras进行定义,如下:
# coding: utf8
from keras.models import Sequential
from keras.regularizers import l2
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.layers.normalization import BatchNormalization
from keras.layers.advanced_activations import LeakyReLU
def cnn_net(size):
model = Sequential()
model.add(Convolution2D(16, 5, 5, W_regularizer=l2(5e-4), border_mode='same', input_shape=(size, size, 3)))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.1))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 5, 5, W_regularizer=l2(5e-4), border_mode='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.1))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3, W_regularizer=l2(5e-4), border_mode='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.1))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='Adam', metrics=['accuracy'])
return model
数据增强与模型训练
Keras提供了数据增强的功能,能够增加数据量并且防止过拟合。使用ImageDataGenerator能够将文件夹中的原始数据转化为生成器,供模型使用。
import os
import sys
import argparse
import pandas as pd
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import EarlyStopping
from keras.utils.visualize_util import plot
def data_process(size, batch_size_train, batch_size_val):
path = os.path.abspath(os.path.join(os.path.dirname("__file__"), os.path.pardir))
datagen1 = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
rotation_range=90,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
datagen2 = ImageDataGenerator(rescale=1. / 255)
train_generator = datagen1.flow_from_directory(
path + '//data//train',
target_size=(size, size),
batch_size=batch_size_train,
class_mode='binary')
validation_generator = datagen2.flow_from_directory(
path + '//data//validation',
target_size=(size, size),
batch_size=batch_size_val,
class_mode='binary')
return train_generator, validation_generator
模型训练函数如下所示,我们在训练的过程中引入了EarlyStopping,保证模型在准确度不再上升的时候自动结束训练。
def train(model, epochs, batch_size_train, batch_size_val, size):
train_generator, validation_generator = data_process(size, batch_size_train, batch_size_val)
earlyStopping = EarlyStopping(monitor='val_loss', patience=50, verbose=1, mode='auto')
hist = model.fit_generator(
train_generator,
nb_epoch=epochs,
samples_per_epoch=batch_size_train,
validation_data=validation_generator,
nb_val_samples=batch_size_val,
callbacks=[earlyStopping])
df = pd.DataFrame.from_dict(hist.history)
df.to_csv('hist.csv', encoding='utf-8', index=False)
model.save('weights.h5')
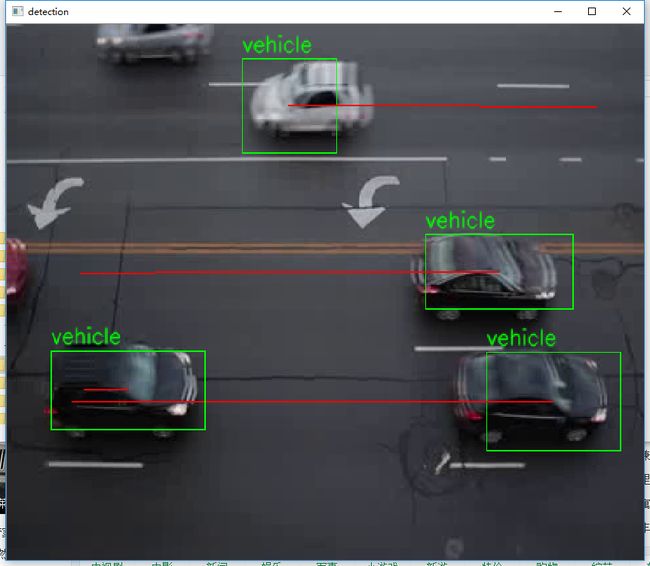
结果
运行下列命令,即可对video文件夹中保存的文件进行处理。
python track.py --file "car.flv"
效果如下图所示: