最近在学习机器学习,虽然早就对kmeans有所耳闻,但一直没腾出时间来实现。本着自己实现一遍是最好的理解原则,决定自己手动实现一遍。
Kmeans是一种聚类算法。用于将一份数据,按照相似性进行聚合分类,将相似的信息聚合到一起。
需要指定簇的个数,即需要将信息分成几份。如谷歌的新闻,将相类似的新闻聚集在一起提供给用户搜索,阅读。
基本的逻辑如下:
1.随机初始化k个簇中心。(一般随机取k个样本点)
2.计算每个样本点到每个簇中心的距离,将其归入到最近的簇中。
3.重新计算每个簇的簇中心(一般计算簇中所有样本点的均值),移动簇中心到新的中心。
接下来,按照上述逻辑,来简单实现kmeans算法。
import numpy as np
import matplotlib.pyplot as plt
随机初始化两组数据
首先初始化两组数据,用于测试。两组数据最好能明确分开。方便观察测试。
x1 = np.random.randint(1,100,size=(10,))
x2 = np.random.randint(200,300,size=(10,))
y1 = np.tan(x1)
y2 = np.tan(x2)
plt.scatter(x1,y1,s =20,alpha=1.0,c = 'green')
plt.scatter(x2,y2,s = 20,alpha=1.0,c = 'blue')
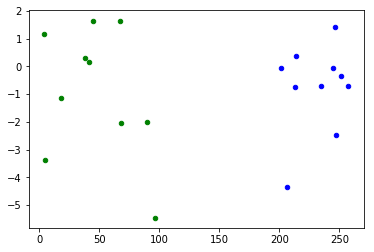
初始化的蓝绿两组数据
data1 = np.vstack((x1,y1)).T
data2 = np.vstack((x2,y2)).T
data = np.vstack((data1,data2))
随机选取中心点
def init_k_center(data,k):
data_size = data.shape[0]
centoids = np.random.choice(range(data_size),size=k)
centers = data[centoids]
return centers
聚类。将数据按最近中心点进行聚集
def cluster(data,centers):
data_group = {}
data_size = data.shape[0]
for c_idx in range(centers.shape[0]):
data_group[c_idx] = []
for i in range(0,data_size):
da = data[i]
min_dis = np.linalg.norm(da-centers[0])
min_center_idx = 0
#找出最近的中心点
for c_idx in range(1,centers.shape[0]):
dis = np.linalg.norm(da-centers[c_idx])
if dis < min_dis:
min_dis = dis
min_center_idx = c_idx
data_group[min_center_idx].append(da)
return data_group
重新规划中心点
def re_center(data_group):
centers = []
for key,value in data_group.items():
#重新计算中心点
value = np.array(value)
#计算所有点的均值
center = np.mean(value,axis=0)
centers.append(center)
return centers
辅助函数,画点数据
def draw_center_group(centers,data_group):
colors = ["green","blue"]
ci = 0
for value in data_group.values():
value = np.array(value)
plt.scatter(value[:,0],value[:,1],s = 20,alpha=0.5,c = colors[ci])
ci += 1
for i in range(0,len(centers)):
center = centers[i]
plt.scatter(center[0],center[1],s =50,alpha=1.0,c = 'red')
plt.show()
组合到一起
def kmeans(data,k):
#初始化k个中心
init_centers = init_k_center(data,k)
prev_center = init_centers
draw_center(init_centers,data)
data_group = None
for i in range(100):
#聚集。将数据根据中心点的距离分别分到k个簇中。
data_group = cluster(data,prev_center)
#重新规划中心点
after_center = re_center(data_group)
after_center = np.array(after_center)
#计算前后两次中心点的距离
diff = np.linalg.norm(after_center-prev_center)
print("After %d steps, diff is :%g"%(i,diff))
if diff < 0.2:
break
prev_center = after_center
new_centers = after_center
draw_center_group(new_centers,data_group)
kmeans(data,2) # 将数据分为两份
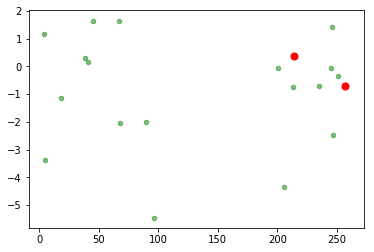
红色表示随机初始化的中心点
After 0 steps, diff is :111.548
After 1 steps, diff is :58.2868
After 2 steps, diff is :0
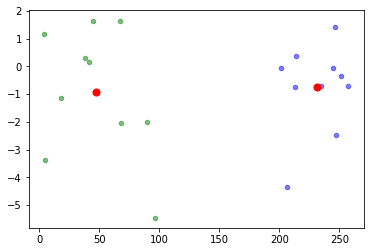
经过kmeans算法调整后的中心点及各自的数据
至此,一个简单的kmeans算法就完成了!