java初中级程序员面试题及答案
java基础
1,封装可以使代码模块化,隐藏细节,继承可以扩展已经存在的模块(类),他们的目的都是代码重用,多态则是实现另一个目的,接口重用,保证类在继承和派生的时候,使用"家谱"中的任意一个实例的正确调用.
多态:同意操作作用于不同对象,可以有不同的解释,产生不同的行为的执行结果,多态存在的三个条件:a.类的继承,b.子类重写父类的方法,c.父类的引用指向子类的对象
2.final, finally, finalize 的区别
final 关键字 ,作用类和变量和方法,作用在类上说明不能派生出子类,作用在变量上,必须在声明 的时候初始化,而且在以后的引用只能被读取,被final修饰的方法只能使用,不能被修改和重写,作用在方法上常用于模板方法.
finally是在异常处理是提供任何情况的清理操作,在代码逻辑中常用于释放资料.
finalize是方法名,java技术中允许在垃圾收集器把对象从内存中清除之前做的清理工作,这个方法是垃圾回收器确定这个对象没有被引用时调用的,这个对象时Object的方法,子类覆盖finalize一般用于整理系统资源或其他清理工作,finalize总是在垃圾收集器删除对象之前调用的.
3.Exception、Error、运行时异常与一般异常有何异同
java中异常都是派生于Throwable类的一个实例.下面是异常类层次结构

从上图可以看出所有的异常都是Throwable的子类,可以分为两个分支Error和Exception,通常Error异常都是描述java运行时系统错误和资源耗尽,大多数和代码编写和执行的操作无关,应用程序不该抛出这样的异常.
Exception异常有派生出两个分支,一个是运行时异常(RuntimeException),另外是其他异常由程序错误导致的异常属于RuntimeException,而程序本身没有问题而由像IO,网络导致的异常属于其他异常的范畴.
另外两个概念:unchecked exception,非检查异常:包括runtimeException和Error派生出的异常,对于运行时异常java编译器不要求进行异常处理,由程序员自己处理
checked exception,受检异常,编译异常,java编译器必须要求处理,或catch或抛出
4.int 和 Integer 有什么区别,Integer的值缓存范围
对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为falseI
5.说说反射的用途及实现
通过反射,我们可以在运行期动态的获取类型成员以及成员变量,程序中一般的对象类型都是在编译期间确定,而java反射机制可以动态的创建对象,已经访问和该更对象的属性.
Java反射机制是一个非常强大的功能,在很多的项目比如Spring,Mybatis都都可以看到反射的身影。通过反射机制,我们可以在运行期间获取对象的类型信息。利用这一点我们可以实现工厂模式和代理模式等设计模式,同时也可以解决java泛型擦除等令人苦恼的问题。
6.说说自定义注解的场景及实现
SOURCE 源码级别,注解只存在源码中,功能是与编译器交互,用于代码检测。如@Override,@SuppressWarings。额外效率损耗发生在编译时
CLASS 字节码级别,注解存在源码与字节码文件中,主要用于编译时生成额外的文件,如XML,Java文件等,但运行时无法获得。这个级别需要添加JVM加载时候的代理(javaagent),使用代理来动态修改字节码文件
RUNTIME 运行时级别,注解存在源码,字节码与Java虚拟机中,主要用于运行时反射获取相关信息
7.Session与Cookie区别
cookie是一种客户端保存状态的机制,session是一种服务器端保存状态的机制,当浏览器访问web服务时,浏览器会将访问的部分信息已键值对的方式保存在本地,下次再访问同一个服务时,浏览器会将cookie的key发送给服务器,服务器会先判断这个key是否存在对应的session如果没有,将创建一个session保存在服务器端,如果有session会将session信息检索出来
8.session 分布式处理
处理的方案大致有五种,粘性session,通过配置nginx可以实现,用户通过Nginx访问了A服务,会在A服务产生用户的session信息,当在此访问时,nginx还会把请求转发给有用户信息的服务器(A),
服务器session复制,当用户访问A服务器产生session之后,服务器会以广播的方式的通知其他的服务器更新最新的session信息,通过配置容器集群的配置文件实现
session共享:使用分布式缓存方案比如memcached、Redis,但是要求Memcached或Redis必须是集群,用户访问A服务器,会生产session,当前服务会更新seesion到缓存数据库中
9.列出自己常用的JDK包
1、java.lang
2、java.sql
3、java.io
4、java.math
5、java.text
6、java.net
7、java.util
8、java.awt
9、java.applet
10、java.nio
10.MVC设计思想
MVC英文即Model-View-Controller,即把一个应用的输入、处理、输出流程按照Model、View、Controller的方式进行分离,这样一个应用被分成三个层——模型层、视图层、控制层.
MVC思想的服务java设计模式的单一职责原则,分层各司其职,对于代码的管理扩展和维护提供了更多的遍历.
说下SpringMvc的设计思路:
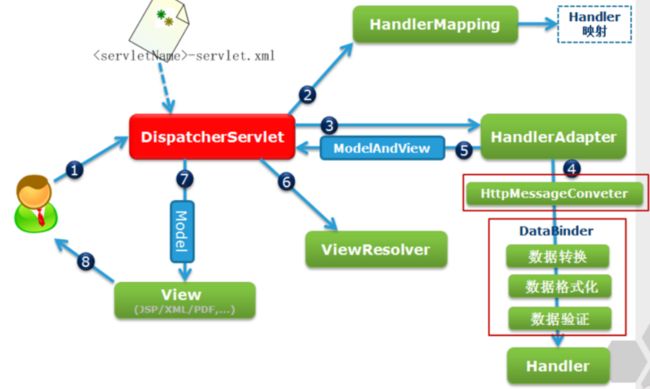
首先用户请求进来,DispatcherServlet收到用户请求,对请求url进行解析,得到请求资源标识符(uri),然后调用handerMapping获得hander对应的所有对象(包括controller和拦截器),以handerExecuteChain返回,核心控制器(DispatcherServlet)根据hander调用合适的handerAdapter(如果获取handerAdapter成功,将执行拦截器的前置方法)
在hander调用前,核心控制器会提取request的参数,传到到hander入参,在填充hander入参的过程中,spring会根据你的配置,做一下合适的数据转换,入时间转换,MessageConvter接口(转换器)
hander执行完之后会返回一个modelAndView对象给核心控制器,根据modelAndView核心控制器会选择合适的viewResolver返回,viewResovler根据modelAndView渲染视图
11.什么是Java序列化和反序列化,如何实现Java序列化?或者请解释Serializable 接口的作用
我们有时候将一个java对象变成字节流的形式传出去或者从一个字节流中恢复成一个java对象,这就是序列换和返序列换,实现serializable接口只是一个空接口,做标识用的,告诉jvm这个对象时可以被序列化的.
12.Object类中常见的方法,为什么wait notify会放在Object里边?
synchronized的锁是任意对象,所有任意对象都可以调用wait和notify,所以wait和notify属于Object,换中专业点的说法是这些方法(wait,notiry)操作同步线程时,都必须标识操作线程的锁,只有同一个锁上的等待线程,可以被同一个锁的notify唤醒,不可以被不通锁上的notify唤醒,等待和唤醒必须是同一个锁,而锁又是任意对象所以说wait和notify是在object对象上的.
Java常见集合
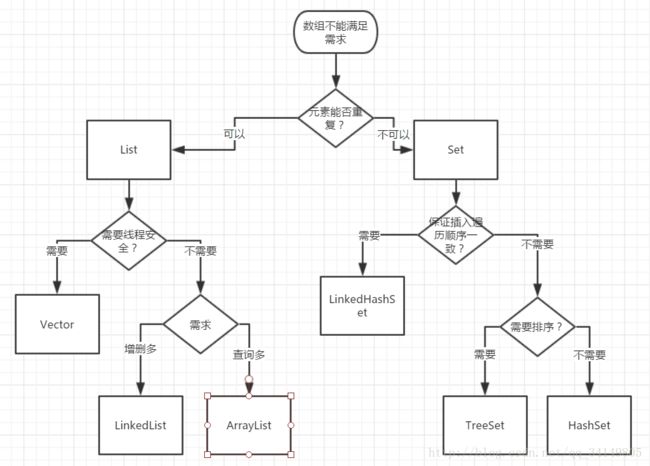
1.List和set区别
类图如下:

先说下集合和数组的区别:
长度区别:数组长度固定.集合可变 .内容区别:数组可以是引用类型和基本类型,集合只能是引用类型.
元素区别,数组只能是一种类型,集合可以使多中类型(一般只存一种类型)
集合的基本方法:
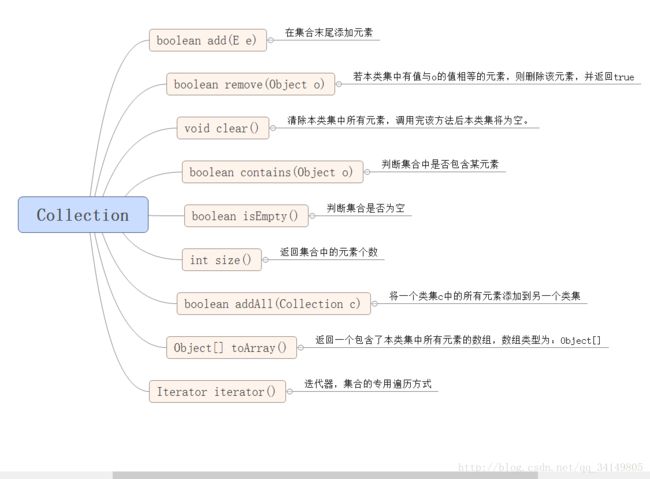
ArrayXxx:底层数据结构是数组,查询快,增删慢
LinkedXxx:底层数据结构是链表,查询慢,增删快
HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals()
TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序

如何使用它们:
Set和hashCode以及equals方法的联系
hashCode是本地方法,它与对象在内存中的地址有关,equals是比较两个对象的内容是否相等,HashSet根据hasCode的值判断插入位置,equals判断插入位置上的对象是否相等,有以必须要重写这个两个方法.
使用HashSet 的add()方法插入元素的时候:
|- HashSet会自动调用元素的hashCode()方法。
|- 然后根据hashCode()方法的返回值 来决定元素要插入的位置。
|- 如果该位置上已经存在元素了 则会调用该元素equals()方法进行比较。
|- 如果两个元素相等 则丢掉欲插入的元素。
|- 如果两个元素不相等 则新元素会被加入到另一个位置(通过冲突检测来决定哪一个位置),这样就消除了重复。]
List 和 Map 区别
Collection、Set、List和Map都是接口,不能被实例化。
Set和List都继承自Collection,而Map则和Collection没什么关系。
Set和List的区别在于Set不能重复,而List可以重复。
Map和Set与List的区别在于,Map是存取键值对,而另外两个则是保存一个元素

HashMap 和 ConcurrentHashMap 的区别
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
总结ConcurrentHashMap就是一个分段的hashtable ,根据自定的hashcode算法生成的对象来获取对应hashcode的分段块进行加锁,不用整体加锁,提高了效率,
HashMap 的工作原理及代码实现,什么时候用到红黑树
JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。
当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。
针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。
JDK 1.8 以后哈希表的 添加、删除、查找、扩容方法都增加了一种 节点为 TreeNode 的情况:
添加时,当桶中链表个数超过 8 时会转换成红黑树;
删除、扩容时,如果桶中结构为红黑树,并且树中元素个数太少的话,会进行修剪或者直接还原成链表结构;
查找时即使哈希函数不优,大量元素集中在一个桶中,由于有红黑树结构,性能也不会差。
