Java源代码,去掉注释:
》使用Eclipse,Ctrl+F打开替换窗体,输入/\*(.|[\r\n])*?\*/和//.*$分别替换/**/和//这两种注释【注意勾选替换面板中得正则表达式选项】
》然后将代码复制到文本工具中(如:EditPlus),这一步主要是为了避免在下一步中,直接将Eclipse中的代码,复制到MyBase中会产生乱码的问题。
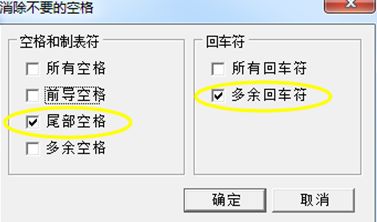
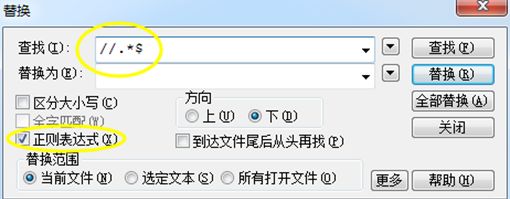
》然后再从Editplus中拷贝代码到MyBase中,在MyBase中Ctrl+A全选代码后,使用【编辑】-【移除空格】-【选择尾部空格、多余空格、多余回车符】然后点击【确定】即可删除多余的空行、空格等信息
注意:选择一下两项,可以在删除多余空格的前提下,保持代码的格式
操作快捷键:Ctrl+A全选,然后Ctrl+Shift+E,勾选【尾部空格】和【多余空格】,点击确定即可。
》将处理完的代码拷贝到word文档中即可。
注意:替换是勾选正则表达式选项,否则提示查找不到字符串
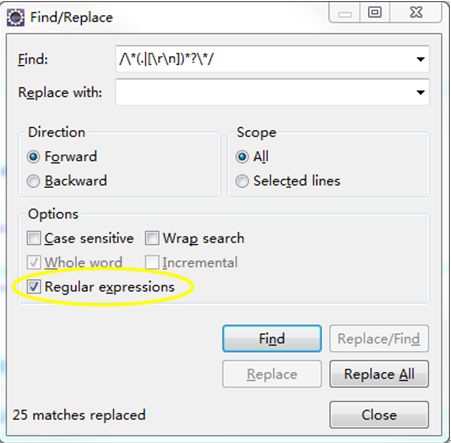
EditPlus:同样注意勾选正则表达式
//.*$替换单行注释
网上的方法:
http://hi.baidu.com/cowskin/item/2d7360f099a2242d753c4c35
由于公司软件要申请版权,要求去掉注释,写了两个个正则表达式
去掉/**/(eclipse)----------------/\*(.|[\r\n])*?\*/
去掉//(eclipse)------------------ //.*$
去掉import(eclipse)------------ import.*$
去掉空行(ue)------%[ ^t]++^p
第一个正则表达式参考这个
http://ostermiller.org/findcomment.html
Finding Comments in Source Code Using Regular Expressions
Many text editors have advanced find (and replace) features. When I’mprogramming, I like to use an editor with regular expression search andreplace. This feature is allows one to find text based on complex patternsrather than based just on literals. Upon occasion I want to examine each of thecomments in my source code and either edit them or remove them. I found that itwas difficult to write a regular expression that would find C style comments(the comments that start with /* and end with */) because my text editor doesnot implement the “non-greedy matching” feature of regular expressions.
First Try
When first attempting this problem, most people consider the regularexpression:
/\*.*\*/
This seems the natural way to do it. /\* finds the start of the comment(note that the literal * needs to be escaped because * has a special meaning inregular expressions), .* finds any number of any character, and \*/ finds theend of the expression.
The first problem with this approach is that .* does not match new lines.
/* First comment
first comment—line two*/
/* Second comment */
Second Try
This can be overcome easily by replacing the . with [^] (in some regularexpression packages) or more generally with (.|[\r\n]):
/\*(.|[\r\n])*\*/
This reveals a second, more serious, problem—the expression matches toomuch. Regular expressions are greedy, they take in as much as they can.Consider the case in which your file has two comments. This regular expressionwill match them both along with anything in between:
start_code();
/* First comment */
more_code();
/* Second comment */
end_code();
Third Try
To fix this, the regular expression must accept less. We cannot acceptjust any character with a ., we need to limit the types of characters that canbe in our expressions:
/\*([^*]|[\r\n])*\*/
This simplistic approach doesn’t accept any comments with a * in them.
/*
* Common multi-line comment style.
*/
/* Second comment */
Fourth Try
This is where it gets tricky. How do we accept a * without accepting the *that is part of the end comment? The solution is to still accept any characterthat is not *, but also accept a * and anything that follows it provided thatit isn’t followed by a /:
/\*([^*]|[\r\n]|(\*([^/]|[\r\n])))*\*/
This works better but again accepts too much in some cases. It will acceptany even number of *. It might even accept the * that is supposed to end thecomment.
start_code();
/****
* Common multi-line comment style.
****/
more_code();
/*
* Another common multi-line commentstyle.
*/
end_code();
Fifth Try
What we tried before will work if we accept any number of * followed byanything other than a * or a /:
/\*([^*]|[\r\n]|(\*+([^*/]|[\r\n])))*\*/
Now the regular expression does not accept enough again. Its workingbetter than ever, but it still leaves one case. It does not accept commentsthat end in multiple *.
/****
* Common multi-line comment style.
****/
/****
* Another common multi-line commentstyle.
*/
Solution
Now we just need to modify the comment end to allow any number of *:
/\*([^*]|[\r\n]|(\*+([^*/]|[\r\n])))*\*+/
We now have a regular expression that we can paste into text editors thatsupport regular expressions. Finding our comments is a matter of pressing thefind button. You might be able to simplify this expression somewhat for yourparticular editor. For example, in some regular expression implementations, [^]assumes the [\r\n] and all the [\r\n] can be removed from the expression.
This is easy to augment so that it will also find // style comments:
(/\*([^*]|[\r\n]|(\*+([^*/]|[\r\n])))*\*+/)|(//.*)
ToolExpression and UsageNotes
nedit(/\*([^*]|[\r\n]|(\*+([^*/]|[\r\n])))*\*+/)|(//.*)
Ctrl+F to find, put in expression, check the Regular Expression check box.[^] does not include new line
grep(/\*([^*]|(\*+[^*/]))*\*+/)|(//.*)
grep -E “(/\*([^*]|(\*+[^*/]))*\*+/)|(//.*)” Does not support multi-line comments, willprint out each line that completely contains a comment.
perl/((?:\/\*(?:[^*]|(?:\*+[^*\/]))*\*+\/)|(?:\/\/.*))/
perl -e“$/=undef;print<>=~/((?:\/\*(?:[^*]|(?:\*+[^*\/]))*\*+\/)|(?:\/\/.*))/g;”< Prints out all thecomments run together. The (?: notation must be used for non-capturingparenthesis. Each / must be escaped because it delimits the expression.$/=undef; is used so that the file is not matched line by line like grep.
Java"(?:/\\*(?:[^*]|(?:\\*+[^*/]))*\\*+/)|(?://.*)"
System.out.println(sourcecode.replaceAll(“(?:/\\*(?:[^*]|(?:\\*+[^*/]))*\\*+/)|(?://.*)”,””));Prints out the contents of the stringsourcecode with the comments removed. The (?: notation must be used fornon-capturing parenthesis. Each \ must be escaped in a Java String.
An Easier Method Non-greedy Matching
Most regular expression packages support non-greedy matching. This meansthat the pattern will only be matched if there is no other choice. We canmodify our second try to use the non-greedy matcher *? instead of the greedymatcher *. With this new tool, the middle of our comment will only match if itdoesn’t match the end:
/\*(.|[\r\n])*?\*/
ToolExpression and UsageNotes
nedit/\*(.|[\r\n])*?\*/
Ctrl+F to find, put in expression, check the Regular Expression check box.[^] does not include new line
grep/\*.*?\*/
grep -E ‘/\*.*?\*/’ Doesnot support multi-line comments, will print out each line that completelycontains a comment.
perl/\*(?:.|[\r\n])*?\*/
perl -0777ne ‘print m!/\*(?:.|[\r\n])*?\*/!g;’ Prints out all the comments run together.The (?: notation must be used for non-capturing parenthesis.
/ does not have to be escaped because ! delimits the expression.
-0777 is used to enable slurp mode and -n enables automatic reading.
Java"/\\*(?:.|[\\n\\r])*?\\*/"
System.out.println(sourcecode.replaceAll(“/\\*(?:.|[\\n\\r])*?\\*/”,””));Prints out the contents of the stringsourcecode with the comments removed. The (?: notation must be used fornon-capturing parenthesis. Each \ must be escaped in a Java String.
Caveats Comments Inside Other Elements
Although our regular expression describes c-style comments very well,there are still problems when something
appears to be a comment but is actually part of a larger element.
someString = "An example comment: /* example */";
// The comment around this code has been commented out.
// /*
some_code();
// */
The solution to this is to write regular expressions that describe each ofthe possible larger elements, find these as well, decide what type of elementeach is, and discard the ones that are not comments. There are tools called lexersor tokenizers that can help with this task. A lexer accepts regular expressionsas input, scans a stream, picks out tokens that match the regular expressions,and classifies the token based on which expression it matched. The greedyproperty of regular expressions is used to ensure the longest match. Althoughwriting a full lexer for C is beyond the scope of this document, thoseinterested should look at lexer generators such as Flex and JFlex.