有点惭愧,读这里的代码的初衷是因为同学说,连Retinanet都不知道你还在搞深度学习。希望ta没看见这篇博客吧。。。。
论文地址
tensorflow代码(我解读的)
tf-RetinaNet这个项目已经完成了,作者还提供了中文操作文档,希望没把你们带到坑里去。
Retinanet这篇论文的最大特点就是提出了一个无人能敌的loss优化函数。
所以论文题目就叫Focal Loss for Dense Object Detection,就是专门为了在目标检测领域削减类别不平问题,从而设计了Focal Loss。
网络简介
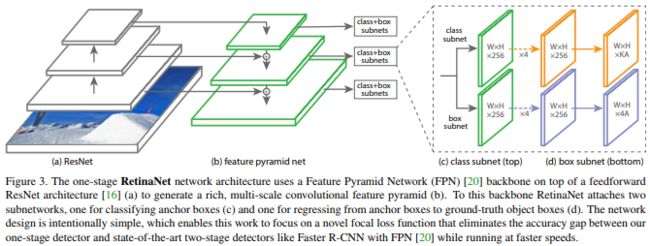
这里的主干网络类似FPN的特征金字塔结构。毕竟论文的重点不在这里啊,主要是loss。
-
实验网络
loss
现在的目标检测分为两个派别:two-stage detector和one-stage detector。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。作者提出focal loss的出发点是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。ok 就是说这里的 Focal Loss专门对one-stage detector设计的,没two-stage detector什么事。
来看看损失函数:
-
二分类CE损失

针对二分类,y的值是正1或负1,p的范围为0到1。当真实label是1,也就是y=1时,假如某个样本x预测为1这个类的概率p=0.6,那么损失就是-log(0.6),注意这个损失是大于等于0的。如果p=0.9,那么损失就是-log(0.9),所以p=0.6的损失要大于p=0.9的损失。
-
加权CE损失:
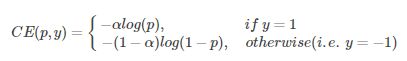
增加了一个系数a,跟p的定义类似,当label=1的时候,系数是a;当label=-1的时候,系数是1-a,a的范围是0到1。因此可以通过设定a的值(一般而言假如1这个类的样本数比-1这个类的样本数多很多,那么a会取0到0.5来增加-1这个类的样本的权重)来控制正负样本对总的loss的共享权重。这里的加权可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重。
-
Focal Loss

这里的称作focusing parameter,>=0。
- 1.当一个样本被分错的时候,是很小的(比如当y=1时,p要小于0.5才是错分类,此时就比较小,反之亦然),因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当p趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。
- 2.当=0的时候,focal loss就是二分类的交叉熵损失,当增加的时候,调制系数也会增加。
-
- focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
作者在实验中采用的是的focal loss,这样既能调整正负样本的权重,又能控制难易分类样本的权重。
增加的时候,a需要减小一点(实验中=2,a=0.25的效果最好),a=0.5就表示传统的交叉熵
这里还需要好好研究。。。。
开始代码:
作者的这个项目好像还没完成,我只能从主要流程上分析这里的代码,毕竟这是github上tf版星星最多的一个项目,这里的项目和Google Object Detection API 有点类似,这里生成tfrecord好像也是用到是哪里面的代码。我并没有调试这里的代码。。。。。。。。。。。。。。。。。

- data: 存放数据的目录
- object_detecion :主要的组建
- maodel_main.py: 函数的入口
model_main.py
def main(unused_argv):
flags.mark_flag_as_required('model_dir')
flags.mark_flag_as_required('label_map_path')
flags.mark_flag_as_required('train_file_pattern')
flags.mark_flag_as_required('eval_file_pattern')
config = tf.estimator.RunConfig(model_dir=FLAGS.model_dir)
run_config = {"label_map_path": FLAGS.label_map_path,
"num_classes": FLAGS.num_classes}
if FLAGS.finetune_ckpt:
run_config["finetune_ckpt"] = FLAGS.finetune_ckpt
# 创建检测模型
model_fn = create_model_fn(run_config)
# 使用评估器对模型进行操作
estimator = tf.estimator.Estimator(model_fn=model_fn, config=config)
# 创建训练输入函数,对数据进行处理
train_input_fn = create_input_fn(FLAGS.train_file_pattern, True, FLAGS.image_size, FLAGS.batch_size)
eval_input_fn = create_input_fn(FLAGS.eval_file_pattern, False, FLAGS.image_size)
# 创建预测输入函数,
prediction_fn = create_prediction_input_fn()
# 创建训练,验证评估器
train_spec, eval_spec = create_train_and_eval_specs(train_input_fn, eval_input_fn, prediction_fn, FLAGS.num_train_steps)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
主要流程如上所示:
- 1.创建检测模型
- 2.读取数据
- 3.托管训练和评估
在这里面出现了两个比较重要的函数,
- create_model_fn
- create_train_and_eval_specs
这两个函数都是从model导入的。
model.py
开始第一个函数create_model_fn这是创建检测模型的函数。只是贴了主要的流程。
def create_model_fn(run_config, default_params=DEFAULT_PARAMS):
def model_fn(features, labels, mode, params):
# 创建RetinaNetModel模型
model = RetinaNetModel(is_training=is_training, num_classes=num_classes)
if mode == tf.estimator.ModeKeys.TRAIN:
# load pretrained model for checkpoint
ckpt_file = run_config.get("finetune_ckpt")
if ckpt_file:
# 获取预训练的初值
asg_map = model.restore_map()
available_var_map = (_get_variables_available_in_ckpt(asg_map, ckpt_file))
tf.train.init_from_checkpoint(ckpt_file, available_var_map)
# predict
images = features["image"]
keys = features["key"]
# 使用进行检测
predictions_dict = model.predict(images)
# postprocess
if mode in (tf.estimator.ModeKeys.EVAL, tf.estimator.ModeKeys.PREDICT):
# 模型的后处理,进行softmax操作
detections = model.postprocess(predictions_dict, score_thres=default_params.get("score_thres"))
# unstack gt info
if mode in (tf.estimator.ModeKeys.TRAIN, tf.estimator.ModeKeys.EVAL):
# 如果是在进行训练,需要获取标记
unstacked_labels = unstack_batch(labels)
gt_boxes_list = unstacked_labels["gt_boxes"]
gt_labels_list = unstacked_labels["gt_labels"]
# -1 due to label offset
# 进行one_hot操作
gt_labels_onehot_list = [tf.one_hot(tf.squeeze(tf.cast(gt_labels-label_offset, tf.int32), 1), num_classes)
for gt_labels in gt_labels_list]
# 计算loss
reg_loss, cls_loss, box_weights, cls_weights = model.loss(predictions_dict, gt_boxes_list, gt_labels_onehot_list)
# 对location loss添加box_loss_weight
losses = [reg_loss * default_params.get("box_loss_weight"), cls_loss]
total_loss_dict = {"Loss/classification_loss": cls_loss, "Loss/localization_loss": reg_loss}
# add regularization loss
# 添加正则损失
regularization_loss = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
if regularization_loss:
regularization_loss = tf.add_n(regularization_loss, name='regularization_loss')
losses.append(regularization_loss)
total_loss_dict["Loss/regularization_loss"] = regularization_loss
total_loss = tf.add_n(losses, name='total_loss')
total_loss_dict["Loss/total_loss"] = total_loss
# optimizer
# 构建优化器
if mode == tf.estimator.ModeKeys.TRAIN:
lr = learning_rate_schedule(default_params.get("total_train_steps"))
optimizer = tf.train.MomentumOptimizer(lr, momentum=default_params.get("momentum"))
# batch norm need update_ops
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(total_loss, tf.train.get_global_step())
else:
train_op = None
# predict mode
# 保存预测模型
if mode == tf.estimator.ModeKeys.PREDICT:
export_outputs = {tf.saved_model.signature_constants.PREDICT_METHOD_NAME: detections}
eval_metric_ops = {}
# just for debugging
# 打印信息
logging_hook = [tf.train.LoggingTensorHook({"gt_labels": gt_labels_list[0], "gt_boxes": gt_boxes_list[0],
'norm_box_loss': reg_loss, 'norm_cls_loss': cls_loss,
"pred_box": predictions_dict["box_pred"],
"pred_cls": predictions_dict["cls_pred"]},
every_n_iter=50)]
if mode == tf.estimator.ModeKeys.EVAL:
logging_hook = [tf.train.LoggingTensorHook({"gt_labels": gt_labels_list[0], "gt_boxes": gt_boxes_list[0],
"detection_boxes": detections["detection_boxes"],
"detection_classes": detections["detection_classes"],
"scores": detections["detection_scores"],
"num_detections": detections["num_detections"]},
every_n_iter=50)]
eval_dict = _result_dict_for_single_example(images[0:1], keys[0], detections,
gt_boxes_list[0], tf.reshape(gt_labels_list[0], [-1]))
if run_config["label_map_path"] is None:
raise RuntimeError("label map file must be defined first!")
else:
category_index = create_categories_from_labelmap(run_config["label_map_path"])
coco_evaluator = CocoDetectionEvaluator(categories=category_index)
eval_metric_ops = coco_evaluator.get_estimator_eval_metric_ops(eval_dict)
eval_metric_ops["classification_loss"] = tf.metrics.mean(cls_loss)
eval_metric_ops["localization_loss"] = tf.metrics.mean(reg_loss)
# 托管训练
return tf.estimator.EstimatorSpec(mode=mode,
predictions=detections,
loss=total_loss,
train_op=train_op,
eval_metric_ops=eval_metric_ops,
training_hooks=logging_hook,
export_outputs=export_outputs,
evaluation_hooks=logging_hook)
return model_fn
这个函数就是进行训练的主要函数。流程如下
- 1.创建RetinaNetModel模型
-
- 获取预训练的初值
- 3.使用模型进行检测
- 4.预测值的的后处理,进行softmax操作
- 5.如果是在进行训练,需要获取图片标记
- 6.计算loss
- 7.构建优化器
这里创建模型的函数就是RetinaNetModel,这是下来的重点。
create_train_and_eval_specs
def create_train_and_eval_specs(train_input_fn,
eval_input_fn,
predict_fn,
train_steps):
"""
Create a TrainSpec and EvalSpec
"""
# 训练
train_spec = tf.estimator.TrainSpec(input_fn=train_input_fn,
max_steps=train_steps)
eval_spec_name = "0"
exported_name = "{}_{}".format('Servo', eval_spec_name)
# 验证
exporter = tf.estimator.FinalExporter(name=exported_name, serving_input_receiver_fn=predict_fn)
eval_spec = tf.estimator.EvalSpec(name=eval_spec_name, input_fn=eval_input_fn, steps=None, exporters=exporter)
return train_spec, eval_spec
接下就是RetinaNetModel。
在create_model_fn中model出现的顺序是
- 1.model = RetinaNetModel(is_training=is_training, num_classes=num_classes)
- 2.model.restore_map()
- 3.model.predict(images)
- 4.model.postprocess(predictions_dict, score_thres=default_params.get("score_thres"))
- 5.model.loss(predictions_dict, gt_boxes_list, gt_labels_onehot_list)
下面就是RetinaNetModel的初始化函数
class RetinaNetModel():
"""RetinaNet mode constructor"""
def __init__(self, is_training, num_classes, params=DEFAULT_PARAMS):
"""
Args:
is_training: indicate training or not
num_classes: number of classes for prediction
params: parameters for model definition
resnet_arch: name of which resnet architecture used
"""
self._is_training = is_training
self._num_classes = num_classes
self._nms_fn = post_processing.batch_multiclass_non_max_suppression
self._score_convert_fn = tf.sigmoid
self._params = params
# self._unmatched_class_label = tf.constant([1] + (self._num_classes) * [0], tf.float32)
self._unmatched_class_label = tf.constant((self._num_classes + 1) * [0], tf.float32)
# 创建box匹配器
self._target_assigner = create_target_assigner(unmatched_cls_target=self._unmatched_class_label)
self._anchors = None
self._anchor_generator = None
# FasterRcnn的坐标编码
self._box_coder = faster_rcnn_box_coder.FasterRcnnBoxCoder()
初始化函数没有做太多事情,只是拿到了主要的参数和两个功能函数。
按照顺序
接下来是model.restore_map()
def restore_map(self):
variables_to_restore = {}
# 获取全局训练的参数
for variable in tf.global_variables():
var_name = variable.op.name
if var_name.startswith("retinanet"):
variables_to_restore[var_name] = variable
# 返回参数字典
return variables_to_restore
其实这里的逻辑把我弄糊涂了,因为到这里其实还没有进行模型的构建,基础CNN模型还没构建呢,这里会由参数名称吗???。。。希望有人指点哈
model.predict(images)
def predict(self, inputs):
"""
Perform predict from batched input tensor.
During this time, anchors must be constructed before post-process or loss function called
Args:
inputs: a [batch_size, height, width, channels] image tensor
Returns:
prediction_dict: dict with items:
inputs: [batch_size, height, width, channels] image tensor
box_pred: [batch_size, num_anchors, 4] tensor containing predicted boxes
cls_pred: [batch_size, num_anchors, num_classes+1] tensor containing class predictions
feature_maps: a list of feature map tensor
anchors: [num_anchors, 4] tensor containing anchors in normalized coordinates
"""
# 获取num_scales和box数目
num_anchors_per_loc = self._params.get("num_scales") * len(self._params.get("aspect_ratios"))
# 构建基础的retinanet模型,返回一个字典
#dict(box_pred=tf.concat(box_pred, axis=1),
# cls_pred=tf.concat(class_pred, axis=1),
# feature_map_list=feature_map_list)
prediction_dict = retinanet(inputs, self._num_classes, num_anchors_per_loc, is_training=self._is_training)
# generate anchors
# 从feature_map_list中得到每张feature map的shape,这里没有训练的参数
feature_map_shape_list = self._get_feature_map_shape(prediction_dict["feature_map_list"])
#
image_shape = shape_utils.combined_static_and_dynamic_shape(inputs)
# initialize anchor generator
if self._anchor_generator is None:
# 在每个feature map对应shape 上生成固定的box
self._anchor_generator = Anchor(feature_map_shape_list=feature_map_shape_list,
img_size=(image_shape[1], image_shape[2]),
anchor_scale=self._params.get("anchor_scale"),
aspect_ratios=self._params.get("aspect_ratios"),
scales_per_octave=self._params.get("num_scales"))
self._anchors = self._anchor_generator.boxes
prediction_dict["inputs"] = inputs
prediction_dict["anchors"] = self._anchors
return prediction_dict
这里使用FPN的网络进行预测:
- 1.构建网络,这是全卷积的网络由retinanet完成,得到box和classes分类(21)。这里retinanet类似FPN
- 2.在每个feature 上生成固定的box
- 3.输出
接下来就是进行后处理了:
model.postprocess(predictions_dict, score_thres=default_params.get("score_thres"))
def postprocess(self, prediction_dict, score_thres=1e-8):
"""
Convert prediction tensors to final detection by slicing the bg class, decoding box predictions,
applying nms and clipping to image window
Args:
prediction_dict: dict returned by self.predict function
score_thres: threshold for score to remove low confident boxes
Returns:
detections: a dict with these items:
detection_boxes: [batch_size, max_detection, 4]
detection_scores: [batch_size, max_detections]
detection_classes: [batch_size, max_detections]
"""
with tf.name_scope('Postprocessor'):
box_pred = prediction_dict["box_pred"]
cls_pred = prediction_dict["cls_pred"]
# decode box
# 对预测的坐标进行解码
detection_boxes = self._batch_decode(box_pred)
detection_boxes = tf.expand_dims(detection_boxes, axis=2)
# sigmoid function to calculate score from feature
# 对classes进行概率化
detection_scores_with_bg = tf.sigmoid(cls_pred, name="converted_scores")
# slice detection scores without score
detection_scores = tf.slice(detection_scores_with_bg, [0, 0, 1], [-1, -1, -1])
clip_window = tf.constant([0, 0, 1, 1], dtype=tf.float32)
(nms_boxes, nms_scores, nms_classes,
# 进行极大值抑制
num_detections) = post_processing.batch_multiclass_non_max_suppression(detection_boxes,
detection_scores,
score_thresh=score_thres,
iou_thresh=self._params.get("iou_thres"),
max_size_per_class=self._params.get("max_detections_per_class"),
max_total_size=self._params.get("max_detections_total"),
clip_window=clip_window)
return dict(detection_boxes=nms_boxes,
detection_scores=nms_scores,
detection_classes=nms_classes,
num_detections=num_detections)
这个函数比较简单:
- 1.对所有的box进行解码
- 2.把预测值进行softmax
- 3.使用极大值抑制
进行loss计算,也是本文的创新点。之后慢慢
model.loss(predictions_dict, gt_boxes_list, gt_labels_onehot_list)
def loss(self, prediction_dict, gt_boxes_list, gt_labels_list):
"""
Compute loss between prediction tensor and gt
Args:
prediction_dict: dict of following items
box_encodings: a [batch_size, num_anchors, 4] containing predicted boxes
cls_pred_with_bg: a [batch_size, num_anchors, num_classes+1] containing predicted classes
gt_boxes_list: a list of 2D gt box tensor with shape [num_boxes, 4]
gt_labels_list: a list of 2-D gt one-hot class tensor with shape [num_boxes, num_classes]
Returns:
a dictionary with localization_loss and classification_loss
"""
with tf.name_scope(None, 'Loss', prediction_dict.values()):
# 获取目标值的标记
(batch_cls_targets, batch_cls_weights, batch_reg_targets, batch_reg_weights,
match_list) = self._assign_targets(gt_boxes_list, gt_labels_list)
# num_positives = [tf.reduce_sum(tf.cast(tf.not_equal(matches.match_results, -1), tf.float32))
# for matches in match_list]
# 对gt_boxes_list, match_list进行统计,算入tensorboard
self._summarize_target_assignment(gt_boxes_list, match_list)
# 计算location loss
reg_loss = regression_loss(prediction_dict["box_pred"], batch_reg_targets, batch_reg_weights)
# 计算作者发明的focal_loss
cls_loss = focal_loss(prediction_dict["cls_pred"], batch_cls_targets, batch_cls_weights)
# normalize loss by num of matches
# num_pos_anchors = [tf.reduce_sum(tf.cast(tf.not_equal(match.match_results, -1), tf.float32))
# for match in match_list]
normalizer = tf.maximum(tf.to_float(tf.reduce_sum(batch_reg_weights)), 1.0)
# normalize reg loss by box codesize (here is 4)
# 对loss进行正则化
reg_normalizer = normalizer * 4
normalized_reg_loss = tf.multiply(reg_loss, 1.0/reg_normalizer, name="regression_loss")
normalized_cls_loss = tf.multiply(cls_loss, 1.0/normalizer, name="classification_loss")
return normalized_reg_loss, normalized_cls_loss, batch_reg_weights, batch_cls_weights
这里的loss计算比较简单:
- 1.拿到真实的标记
- 2.进行两个loss计算
- 3.对loss加上正则化
上面介绍的是RetinaNetModel是使用的主要流程。在RetinaNetModel里面有几比较重要的部分,在其他文件。
- retinanet
- focal_loss
- regression_loss
- faster_rcnn_box_coder
- Anchor
虽然不会一一讲解,但这些确实比较重要,也是要TODO
retinanet.py
这里面只用的retinanet这个函数
这里的retinanet函数,其实比较简单。
def retinanet(images, num_classes, num_anchors_per_loc, resnet_arch='resnet50', is_training=True):
"""
Get box prediction features and class prediction features from given images
Args:
images: input batch of images with shape (batch_size, h, w, 3)
num_classes: number of classes for prediction
num_anchors_per_loc: number of anchors at each feature map spatial location
resnet_arch: name of which resnet architecture used
is_training: indicate training or not
return:
prediciton dict: holding following items:
box_predictions tensor from each feature map with shape (batch_size, num_anchors, 4)
class_predictions_with_bg tensor from each feature map with shape (batch_size, num_anchors, num_class+1)
feature_maps: list of tensor of feature map
"""
assert resnet_arch in list(RESNET_ARCH_BLOCK.keys()), "resnet architecture not defined"
with tf.variable_scope('retinanet'):
batch_size = combined_static_and_dynamic_shape(images)[0]
#features = {3: p3,
# 4: p4,
# 5: l5,
# 6: p6,
# 7: p7}
features = retinanet_fpn(images, block_layers=RESNET_ARCH_BLOCK[resnet_arch], is_training=is_training)
class_pred = []
box_pred = []
feature_map_list = []
num_slots = num_classes + 1
# 对所有的features层特征进行classes分类
with tf.variable_scope('class_net', reuse=tf.AUTO_REUSE):
for level in features.keys():
class_outputs = share_weight_class_net(features[level], level,
num_slots,
num_anchors_per_loc,
is_training=is_training)
#class_output.shape=[batch_size,num_classes*num_anchors_per_loc ]
class_outputs = tf.reshape(class_outputs, shape=[batch_size, -1, num_slots])
class_pred.append(class_outputs)
feature_map_list.append(features[level])
# 对所有的features层特征进行box坐标
with tf.variable_scope('box_net', reuse=tf.AUTO_REUSE):
for level in features.keys():
box_outputs = share_weight_box_net(features[level], level, num_anchors_per_loc, is_training=is_training)
# box_outputs.shape=[batch_size,4*num_anchors_per_loc]
box_outputs = tf.reshape(box_outputs, shape=[batch_size, -1, 4])
box_pred.append(box_outputs)
return dict(box_pred=tf.concat(box_pred, axis=1),
cls_pred=tf.concat(class_pred, axis=1),
feature_map_list=feature_map_list)
基本上沿用了FPN的流程:
- 1.构建基础的FPN流程,拿到五个经过特征融合的feature map
- 2.对拿到的特征图进行box坐标预测
- 3.对拿到的特征图进行目标表分类
这里使用的几个函数都比较简单。
- retinanet_fpn
- share_weight_class_net
- share_weight_box_net
retinanet_fpn函数:
def retinanet_fpn(inputs,
block_layers,
depth=256,
is_training=True,
scope=None):
"""
Generator for RetinaNet FPN models. A small modification of initial FPN model for returning layers
{P3, P4, P5, P6, P7}. See paper Focal Loss for Dense Object Detection. arxiv: 1708.02002
P2 is discarded and P6 is obtained via 3x3 stride-2 conv on c5; P7 is computed by applying ReLU followed by
3x3 stride-2 conv on P6. P7 is to improve large object detection
Returns:
5 feature map tensors: {P3, P4, P5, P6, P7}
"""
with tf.variable_scope(scope, 'retinanet_fpn', [inputs]) as sc:
net = conv2d_same(inputs, 64, kernel_size=7, strides=2, scope='conv1')
net = _bn(net, is_training)
net = tf.nn.relu6(net)
net = tf.layers.max_pooling2d(net, pool_size=3, strides=2, padding='SAME', name='pool1')
# Bottom up
# block 1, down-sampling is done in conv3_1, conv4_1, conv5_1
p2 = stack_bottleneck(net, layers=block_layers[0], depth=64, strides=1, is_training=is_training)
# block 2
p3 = stack_bottleneck(p2, layers=block_layers[1], depth=128, strides=2, is_training=is_training)
# block 3
p4 = stack_bottleneck(p3, layers=block_layers[2], depth=256, strides=2, is_training=is_training)
# block 4
p5 = stack_bottleneck(p4, layers=block_layers[3], depth=512, strides=2, is_training=is_training)
p5 = tf.identity(p5, name="p5")
# coarser FPN feature
# p6
p6 = tf.layers.conv2d(p5, filters=depth, kernel_size=3, strides=2, name='conv6', padding='SAME')
p6 = _bn(p6, is_training)
p6 = tf.nn.relu6(p6)
p6 = tf.identity(p6, name="p6")
# P7
p7 = tf.layers.conv2d(p6, filters=depth, kernel_size=3, strides=2, name='conv7', padding='SAME')
p7 = _bn(p7, is_training)
p7 = tf.identity(p7, name="p7")
# lateral layer
l3 = tf.layers.conv2d(p3, filters=depth, kernel_size=1, strides=1, name='l3', padding='SAME')
l4 = tf.layers.conv2d(p4, filters=depth, kernel_size=1, strides=1, name='l4', padding='SAME')
l5 = tf.layers.conv2d(p5, filters=depth, kernel_size=1, strides=1, name='l5', padding='SAME')
# Top dow
# 上采样函数,这里是融合l5和l4
t4 = nearest_neighbor_upsampling(l5, 2) + l4
p4 = tf.layers.conv2d(t4, filters=depth, kernel_size=3, strides=1, name='t4', padding='SAME')
p4 = _bn(p4, is_training)
p4 = tf.identity(p4, name="p4")
# 上采样函数,这里是融合l4和l3
t3 = nearest_neighbor_upsampling(t4, 2) + l3
p3 = tf.layers.conv2d(t3, filters=depth, kernel_size=3, strides=1, name='t3', padding='SAME')
p3 = _bn(p3, is_training)
p3 = tf.identity(p3, name="p3")
features = {3: p3,
4: p4,
5: l5,
6: p6,
7: p7}
return features
这个函数就是构建基础的FPN网络的函数。这里只用P3和P4进行了特征金字塔融合,详细的去看论文吧。
share_weight_box_net函数:
def share_weight_box_net(inputs, level, num_anchors_per_loc, num_layers_before_predictor=4, is_training=True):
"""
Similar to class_net with output feature shape (batch_size, h, w, num_anchors*4)
"""
for i in range(num_layers_before_predictor):
inputs = tf.layers.conv2d(inputs, filters=256, kernel_size=3, strides=1,
kernel_initializer=tf.random_normal_initializer(stddev=0.01),
padding="SAME",
name='box_{}'.format(i))
inputs = _bn(inputs, is_training, name="box_{}_bn_level_{}".format(i, level))
inputs = tf.nn.relu6(inputs)
# 对每个feature map上的点生成4*num_anchors_per_loc个值
outputs = tf.layers.conv2d(inputs,
filters=4*num_anchors_per_loc,
kernel_size=3,
kernel_initializer=tf.random_normal_initializer(stddev=0.01),
padding="SAME",
name="box_pred")
return outputs
这个函数是进行box预测的函数。
share_weight_class_net函数:
def share_weight_class_net(inputs, level, num_classes, num_anchors_per_loc, num_layers_before_predictor=4, is_training=True):
"""
net for predicting class labels
NOTE: Share same weights when called more then once on different feature maps
Args:
inputs: feature map with shape (batch_size, h, w, channel)
level: which feature map
num_classes: number of predicted classes
num_anchors_per_loc: number of anchors at each spatial location in feature map
num_layers_before_predictor: number of the additional conv layers before the predictor.
is_training: is in training or not
returns:
feature with shape (batch_size, h, w, num_classes*num_anchors)
"""
for i in range(num_layers_before_predictor):
inputs = tf.layers.conv2d(inputs, filters=256, kernel_size=3, strides=1,
kernel_initializer=tf.random_normal_initializer(stddev=0.01),
padding="SAME",
name='class_{}'.format(i))
inputs = _bn(inputs, is_training, name="class_{}_bn_level_{}".format(i, level))
inputs = tf.nn.relu(inputs)
# 对每个个点生成num_classes*num_anchors_per_loc个值
outputs = tf.layers.conv2d(inputs,
filters=num_classes*num_anchors_per_loc,
kernel_size=3,
kernel_initializer=tf.random_normal_initializer(stddev=0.01),
padding="SAME",
name="class_pred")
return outputs
这个函数是进行classes分类的函数
这就是这个retinanet.py的主要类容了
下面看看loss.py
这个文件就只有两个loss函数。
focal_loss:
def focal_loss(logits, onehot_labels, weights, alpha=0.25, gamma=2.0):
"""
Compute sigmoid focal loss between logits and onehot labels: focal loss = -(1-pt)^gamma*log(pt)
Args:
onehot_labels: onehot labels with shape (batch_size, num_anchors, num_classes)
logits: last layer feature output with shape (batch_size, num_anchors, num_classes)
weights: weight tensor returned from target assigner with shape [batch_size, num_anchors]
alpha: The hyperparameter for adjusting biased samples, default is 0.25
gamma: The hyperparameter for penalizing the easy labeled samples, default is 2.0
Returns:
a scalar of focal loss of total classification
"""
with tf.name_scope("focal_loss"):
logits = tf.cast(logits, tf.float32)
onehot_labels = tf.cast(onehot_labels, tf.float32)
ce = tf.nn.sigmoid_cross_entropy_with_logits(labels=onehot_labels, logits=logits)
predictions = tf.sigmoid(logits)
predictions_pt = tf.where(tf.equal(onehot_labels, 1), predictions, 1.-predictions)
# add small value to avoid 0
alpha_t = tf.scalar_mul(alpha, tf.ones_like(onehot_labels, dtype=tf.float32))
alpha_t = tf.where(tf.equal(onehot_labels, 1.0), alpha_t, 1-alpha_t)
weighted_loss = ce * tf.pow(1-predictions_pt, gamma) * alpha_t * tf.expand_dims(weights, axis=2)
return tf.reduce_sum(weighted_loss)
结合上面提到的公式一起看吧,和公式是匹配的=2,a=0.25的效果是默认参数。
这是坐标回归loss
def regression_loss(pred_boxes, gt_boxes, weights, delta=1.0):
"""
Regression loss (Smooth L1 loss: also known as huber loss)
Args:
pred_boxes: [batch_size, num_anchors, 4]
gt_boxes: [batch_size, num_anchors, 4]
weights: Tensor of weights multiplied by loss with shape [batch_size, num_anchors]
delta: delta for smooth L1 loss
Returns:
a box regression loss scalar
"""
loss = tf.reduce_sum(tf.losses.huber_loss(predictions=pred_boxes,
labels=gt_boxes,
delta=delta,
weights=tf.expand_dims(weights, axis=2),
scope='box_loss',
reduction=tf.losses.Reduction.NONE))
return loss
借用这里huber_loss推到图
其他两个文件faster_rcnn_box_coder和Anchor都是沿用faster_rcnn的流程,没多大变化。。。
参考:
RetinaNet的理解
Focal Loss-RetinaNet算法解析
Retinanet训练Pascal VOC 2007
Note on RetinaNet(中文)