测试环境
DPVS: Inspur NF5270M3, E5-2630 2.60GHz 24 cores, memory 96G
Real Server: 6 台核数不同的机器,148 个 redis-server
Bench Client: 8 台核数不同的机器,24000 个连接 ping
官方推荐用 f-stack nginx 压测,还要让 real server 跑 dpdk 太麻烦。使用 redis ping 模拟小包,平均 74 bytes, 使用 set 指定 1000 bytes value 来模拟大包。
测试配置及脚本
启动 redis-server 实例,一定要 taskset 绑核
taskset -c 8 ./redis-server ./redis6380.conf
taskset -c 9 ./redis-server ./redis6381.conf
taskset -c 10 ./redis-server ./redis6382.conf
......
测试机启动 redis-benchmark pipeline 压测 ping
#!/bin/sh
cpus=`lscpu | grep '^CPU(s)' | awk '{print $2}'`
for i in `seq 8 $cpus`
do
nohup taskset -c $i ./redis-benchmark -h 10.20.23.241 -p 6379 -c 100 -n 100000000 -t ping -P 10 -l&
done
统计InPkts OutPkts
ipvsadm -ln --stats
ipvsadm --zero
dpip link show dpdk0 -s
dpvs配置: two-arm, full-nat, 8 lcores,nic intel 82599ES
性能问题排查
模拟大包时,two-arm 双 10G 网卡很快打满,符合预期。关键转发能力要看小包,也就是 pps (packets per second),发现只有 250w/pps, 远低于官方数据最理想的 1500w
打开 dpvs debug 模式,可以看到增加了 -g ,并且优化级别是 0
# cat src/Makefile | grep -i debug
DEBUG := 1 # enable for debug
ifeq ($(DEBUG),)
CFLAGS += -g -O0 -D DEBUG
重新压测,并使用 perf 抓取性能数据
perf record -g -p `pidof dpvs` #约 30 秒后 ctrl+c
perf report -i ./perf.data
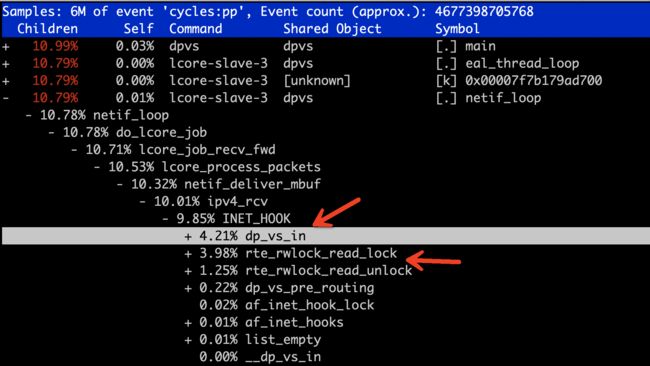
由于 dpvs 是多核程序,所以看 lcore-slave-3 即可,一步步观察,
INET_HOOK占了 9.85% cpu, 里面的
dp_vs_in 占了 4.21%,
rte_rwlock_read_lock/unlock 相关的占了合计 5.1%. 再深入
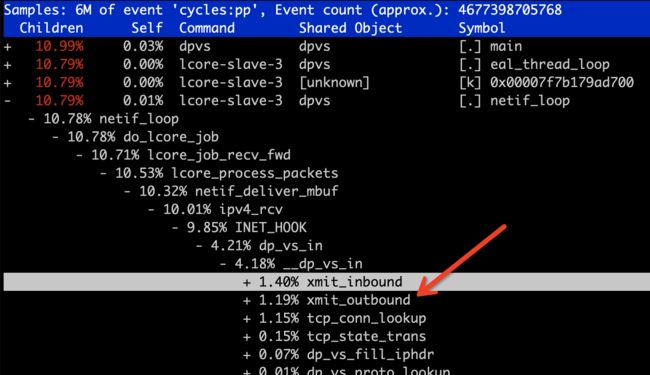
dp_vs_in 函数,发现
xmit_inbound
xmit_outbound
tcp_conn_lookup 占用较高,具体到底层函数都是 tcp header checksum 计算相关函数,比较符合预期。那值得怀疑的就是
rte_rwlock_read_lock/unlock,贴上源码:
int INET_HOOK(int af, unsigned int hook, struct rte_mbuf *mbuf,
struct netif_port *in, struct netif_port *out,
int (*okfn)(struct rte_mbuf *mbuf))
{
struct list_head *hook_list;
struct inet_hook_ops *ops;
struct inet_hook_state state;
int verdict = INET_ACCEPT;
state.hook = hook;
hook_list = af_inet_hooks(af, hook);
rte_rwlock_read_lock(af_inet_hook_lock(af));
ops = list_entry(hook_list, struct inet_hook_ops, list);
if (!list_empty(hook_list)) {
verdict = INET_ACCEPT;
list_for_each_entry_continue(ops, hook_list, list) {
repeat:
verdict = ops->hook(ops->priv, mbuf, &state);
if (verdict != INET_ACCEPT) {
if (verdict == INET_REPEAT)
goto repeat;
break;
}
}
}
rte_rwlock_read_unlock(af_inet_hook_lock(af));
if (verdict == INET_ACCEPT || verdict == INET_STOP) {
return okfn(mbuf);
} else if (verdict == INET_DROP) {
rte_pktmbuf_free(mbuf);
return EDPVS_DROP;
} else { /* INET_STOLEN */
return EDPVS_OK;
}
}
static inline rte_rwlock_t *af_inet_hook_lock(int af)
{
assert(af == AF_INET || af == AF_INET6);
if (af == AF_INET)
return &inet_hook_lock;
else
return &inet6_hook_lock;
}
锁的内容是 af_inet_hook_lock(af), 再看实现,居然锁的是一个全局 lock !!! dpdk 程序最忌多个核之间共享数据,特别是锁竞争。查看 git 提交纪录,由 cc5369c1a3bd4fa7bd838c62fc1cb8797db61b4e ipv6/ipvs: ipvs core support ipv6 引入的问题。仔细阅读代码,这个锁只在初始化期有用,运行期完全可以忽略,何况还是个读锁,也就是 INET_HOOK 根本用不到,果断注释掉重新压测。
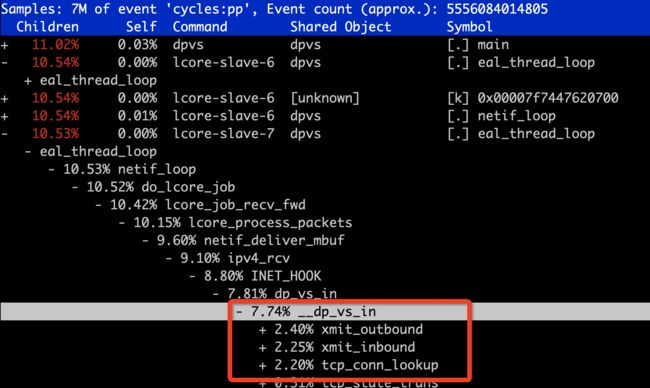
关掉后再次压测,上面的 perf 图里,没有了锁争用问题,占 cpu 比例最高的是
dp_vs_in,集中在 tcp header checksum,这部分没有办法,本身就是 cpu 消耗型的。符合预期。
NETIF: Fail to send 1 packets on dpdk1 tx3
NETIF: Fail to send 7 packets on dpdk1 tx2
NETIF: Fail to send 4 packets on dpdk1 tx2
NETIF: Fail to send 2 packets on dpdk1 tx1
NETIF: Fail to send 1 packets on dpdk1 tx1
如果遇到丢包,也就是 imiss 问题,需要调大 dpvs.conf 队列的 descriptor_number 值,默认的可能有点小,大并发时丢包。
最终压测数据
关掉 DEBUG 模式,77 bytes 小包打到 700w pps, 两个万兆网卡打到 8.5G,网卡先于 dpvs 达到瓶颈,性能比较平稳没有抖动。以后有机会测网卡 bonding 的数据。

锁的问题和 iqiyi 研发沟通了一下,他们之前的压测数据是引入 ipv6 之前的,后续会再内部进行压测优化性能。多核编程锁还是永恒的话题,一个读锁也会有这么大影响,看来有机会得研究下底层锁的实现。