TensorFlow上实践基于自编码的One Class Learning
异常检测算法--Isolation Forest
http://euler.stat.yale.edu/~tba3/stat665/lectures/lec17/notebook17.html
https://blog.keras.io/building-autoencoders-in-keras.html
caglar/autoencoders
FraudDetection
FraudDetection
fraud_detection
fraud_detection
Credit card fraud detection 2 – using Restricted Boltzmann Machine in TensorFlow
Credit card fraud detection 1 – using auto-encoder in TensorFlow
待验证
https://github.com/search?l=Jupyter+Notebook&p=3&q=fraud+detection&type=Repositories&utf8=%E2%9C%93
【机器学习实战】:Python信用卡欺诈检测
--------------------------
Credit-Card-Fraud-Detection-using-Autoencoders-in-Keras
Credit Card Fraud Detection using Autoencoders in Keras — TensorFlow for Hackers (Part VII)
待整理-朱茂华:深度自编码器解析及MLP应用实例
Building Autoencoders in Keras
Gradient Trader Part 1: The Surprising Usefulness of Autoencoders
Introduction to Autoencoders
Convolutional Autoencoders
Convolutional Autoencoders in Tensorflow
Deep Autoencoders
Sparse Autoencoder for Unsupervised Nucleus Detection and Representation in Histopathology Images
Keras Tutorial: Content Based Image Retrieval Using a Convolutional Denoising Autoencoder
Scaling of Texture in Training Autoencoders for Classification of Histological Images of Colorectal Cancer
Medical image denoising using convolutional denoising autoencoders
An Autoencoder-Based Image Descriptor for Image
Matching and Retrieval
深度纹理编码网络 (Deep TEN: Texture Encoding Network)
Deep Encoding
经典文章:
Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." Science 313.5786 (2006): 504-507
Introduction to Autoencoders
Convolutional Autoencoders in Tensorflow
Convolutional Autoencoders
Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction
Autoencoders.ipynb
Applied Deep Learning - Part 3: Autoencoders
Building High-level Features Using Large Scale Unsupervised Learning
深度纹理编码网络 (Deep TEN: Texture Encoding Network)
Deep Encoding
Code
All the code you can check Autoencoder
Keras version Autoencoder
深度学习与Keras-花式自动编码器
Credit-Card-Fraud-Detection-using-Autoencoders-in-Keras
Building Autoencoders in Keras
TensorFlow上实践基于自编码的One Class Learning
what-is-variational-autoencoder-vae-tutorial
PyTorch version Autoencoder
simple_autoencoder
conv_autoencoder
Variational_autoencoder
花式解释AutoEncoder与VAE
SherlockLiao-pytorch-beginner-08-AutoEncoder
Variational Autoencoders Explained
generate MNIST using a Variational Autoencoder
Generating Large Images from Latent Vectors
Tensorflow version Autoencoder
Variational Autoencoder in TensorFlow
Diving Into TensorFlow With Stacked Autoencoders
Deep Autoencoder with TensorFlow
什么是自动编码器
自编码器并不是一个真正的无监督学习的算法,而是一个自监督的算法。自监督学习是监督学习的一个实例,其标签产生自输入数据。
自动编码器(AutoEncoder)最开始作为一种数据的压缩方法,其特点有:
1)跟数据相关程度很高,这意味着自动编码器只能压缩与训练数据相似的数据,这个其实比较显然,因为使用神经网络提取的特征一般是高度相关于原始的训练集,使用人脸训练出来的自动编码器在压缩自然界动物的图片是表现就会比较差,因为它只学习到了人脸的特征,而没有能够学习到自然界图片的特征;
2)压缩后数据是有损的,这是因为在降维的过程中不可避免的要丢失掉信息;
到了2012年,人们发现在卷积网络中使用自动编码器做逐层预训练可以训练更加深层的网络,但是很快人们发现良好的初始化策略要比费劲的逐层预训练有效地多,2014年出现的Batch Normalization技术也是的更深的网络能够被被有效训练,到了15年底,通过残差(ResNet)我们基本可以训练任意深度的神经网络。
所以现在自动编码器主要应用有两个方面,
第一是数据去噪,
第二是进行可视化降维,
自动编码器还有着一个功能就是生成数据。
我们之前讲过GAN,它与GAN相比有着一些好处,同时也有着一些缺点。我们先来讲讲其跟GAN相比有着哪些优点。
第一点,我们使用GAN来生成图片有个很不好的缺点就是我们生成图片使用的随机高斯噪声,这意味着我们并不能生成任意我们指定类型的图片,也就是说我们没办法决定使用哪种随机噪声能够产生我们想要的图片,除非我们能够把初始分布全部试一遍。但是使用自动编码器我们就能够通过输出图片的编码过程得到这种类型图片的编码之后的分布,相当于我们是知道每种图片对应的噪声分布,我们就能够通过选择特定的噪声来生成我们想要生成的图片。
第二点,这既是生成网络的优点同时又有着一定的局限性,这就是生成网络通过对抗过程来区分“真”的图片和“假”的图片,然而这样得到的图片只是尽可能像真的,但是这并不能保证图片的内容是我们想要的,换句话说,有可能生成网络尽可能的去生成一些背景图案使得其尽可能真,但是里面没有实际的物体。
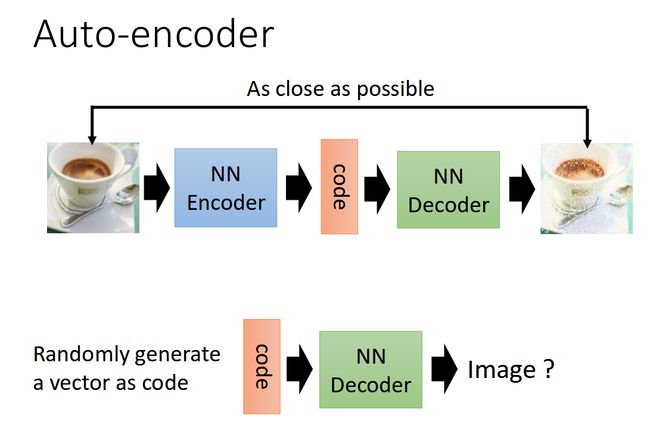
自动编码器的结构
首先我们给出自动编码器的一般结构

从上面的图中,我们能够看到两个部分,第一个部分是编码器(Encoder),第二个部分是解码器(Decoder),编码器和解码器都可以是任意的模型,通常我们使用神经网络模型作为编码器和解码器。输入的数据经过神经网络降维到一个编码(code),接着又通过另外一个神经网络去解码得到一个与输入原数据几乎一模一样的生成数据,是输入数据的几种不同表示(每一层代表一种表示),这些表示就是特征。然后通过去比较这两个数据,最小化他们之间的差异来训练这个网络中编码器和解码器的参数。当这个过程训练完之后,我们可以拿出这个解码器,随机传入一个编码(code),希望通过解码器能够生成一个和原数据差不多的数据,自动编码器就是一种尽可能复现输入信号的神经网络。上面这种图这个例子就是希望能够生成一张差不多的图片。
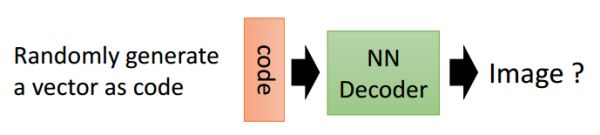
自编码的变种形式

变分自动编码器(Variational Autoencoder)
Using Variational AutoEncoders to Analyze Medical Images
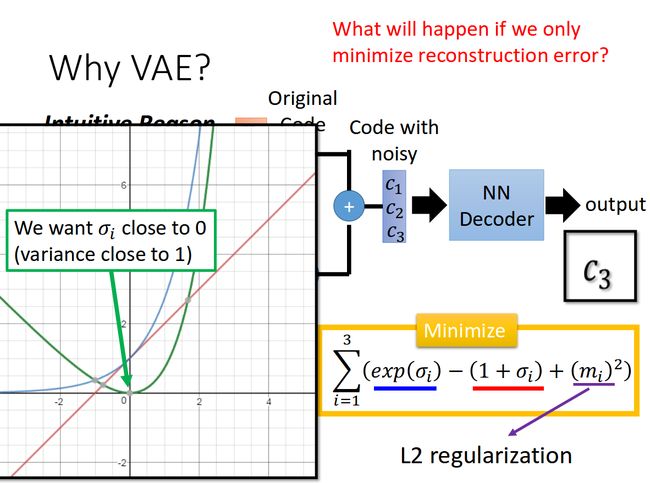

理论推导见
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2017/Lecture/GAN%20(v3).pdf
https://www.bilibili.com/video/av9770190/?from=search&seid=5864777011571835678#page=18
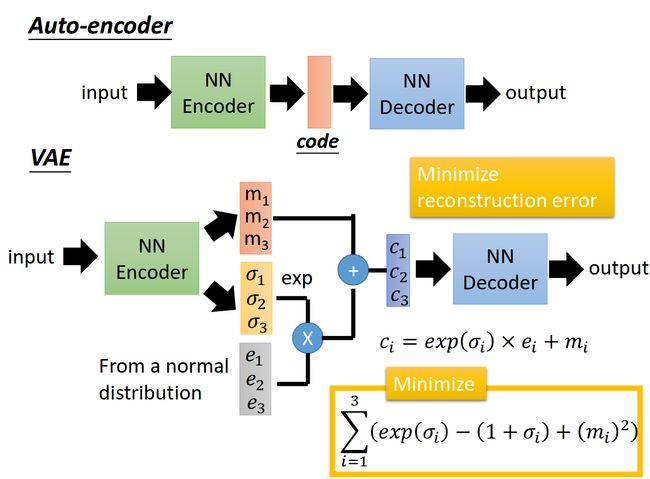
变分编码器是自动编码器的升级版本,其结构跟自动编码器是类似的,也由编码器和解码器构成。
回忆一下我们在自动编码器中所做的事,我们需要输入一张图片,然后将一张图片编码之后得到一个隐含向量,这比我们随机取一个随机噪声更好,因为这包含着原图片的信息,然后我们隐含向量解码得到与原图片对应的照片。
但是这样我们其实并不能任意生成图片,因为我们没有办法自己去构造隐藏向量,我们需要通过一张图片输入编码我们才知道得到的隐含向量是什么,这时我们就可以通过变分自动编码器来解决这个问题。
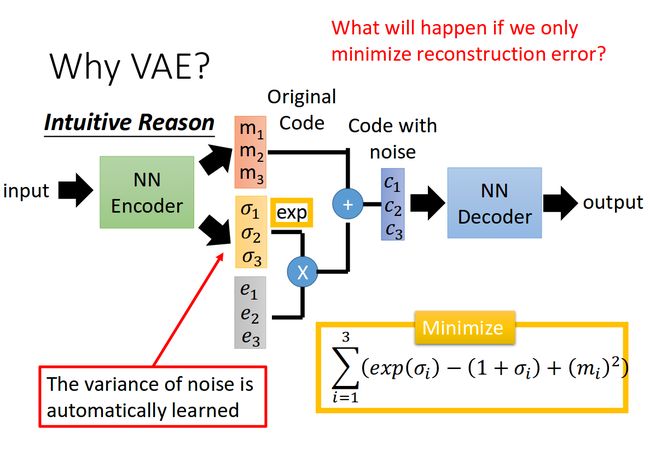
其实原理特别简单,只需要在编码过程给它增加一些限制,迫使其生成的隐含向量能够粗略的遵循一个标准正态分布,这就是其与一般的自动编码器最大的不同。
这样我们生成一张新图片就很简单了,我们只需要给它一个标准正态分布的随机隐含向量,这样通过解码器就能够生成我们想要的图片,而不需要给它一张原始图片先编码。
在实际情况中,我们需要在模型的准确率上与隐含向量服从标准正态分布之间做一个权衡,所谓模型的准确率就是指解码器生成的图片与原图片的相似程度。我们可以让网络自己来做这个决定,非常简单,我们只需要将这两者都做一个loss,然后在将他们求和作为总的loss,这样网络就能够自己选择如何才能够使得这个总的loss下降。另外我们要衡量两种分布的相似程度,如何看过之前一片GAN的数学推导,你就知道会有一个东西叫KL divergence来衡量两种分布的相似程度,这里我们就是用KL divergence来表示隐含向量与标准正态分布之间差异的loss,另外一个loss仍然使用生成图片与原图片的均方误差来表示。
我们可以给出KL divergence 的公式
[图片上传失败...(image-6b565f-1510543203807)]这里变分编码器使用了一个技巧“重新参数化”来解决KL divergence的计算问题。

VAE的缺点也很明显,他是直接计算生成图片和原始图片的均方误差而不是像GAN那样去对抗来学习,这就使得生成的图片会有点模糊。现在已经有一些工作是将VAE和GAN结合起来,使用VAE的结构,但是使用对抗网络来进行训练,具体可以参考一下这篇论文。
Sparse AutoEncoder稀疏自动编码器:
当然,我们还可以继续加上一些约束条件得到新的Deep Learning方法,如:如果在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。

如上图,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分的神经元是受到抑制的)。
Denoising AutoEncoders降噪自动编码器:
降噪自动编码器DA是在自动编码器的基础上,训练数据加入噪声,所以自动编码器必须学习去去除这种噪声而获得真正的没有被噪声污染过的输入。因此,这就迫使编码器去学习输入信号的更加鲁棒的表达,这也是它的泛化能力比一般编码器强的原因。DA可以通过梯度下降算法去训练。

降噪自编码(DAE文献:《Extracting and Composing Robust Features with Denoising Autoencoders》)
降噪自编码与自编码的区别:在原始数据X上加入了噪声X',然后再作为网络的输入数据,来重构输出原始还未加入噪声的数据。
文献的具体做法是,通过对原始数据输入神经元,进行人为随机损坏加噪声,得到损坏数据X'。
方法1:可以采用高斯噪声
方法2:采用binary mask 噪声,也就是把输入神经元值随机置0(跟drop out 一样,把某些神经元的激活值置0),然后再作为神经网络的输入。
Sparse Coding稀疏编码
如果我们把输出必须和输入相等的限制放松,同时利用线性代数中基的概念,即O = a1Φ1+ a2Φ2+….+ an*Φn, Φi是基,ai是系数,我们可以得到这样一个优化问题:
Min |I – O|,其中I表示输入,O表示输出。
通过求解这个最优化式子,我们可以求得系数ai和基Φi,这些系数和基就是输入的另外一种近似表达。

因此,它们可以用来表达输入I,这个过程也是自动学习得到的。如果我们在上述式子上加上L1的Regularity限制,得到:
Min |I – O| + u*(|a1| + |a2| + … + |an|)
这种方法被称为Sparse Coding。通俗的说,就是将一个信号表示为一组基的线性组合,而且要求只需要较少的几个基就可以将信号表示出来。“稀疏性”定义为:只有很少的几个非零元素或只有很少的几个远大于零的元素。要求系数 ai
是稀疏的意思就是说:对于一组输入向量,我们只想有尽可能少的几个系数远大于零。选择使用具有稀疏性的分量来表示我们的输入数据是有原因的,因为绝大多数的感官数据,比如自然图像,可以被表示成少量基本元素的叠加,在图像中这些基本元素可以是面或者线。同时,比如与初级视觉皮层的类比过程也因此得到了提升(人脑有大量的神经元,但对于某些图像或者边缘只有很少的神经元兴奋,其他都处于抑制状态)。
稀疏编码算法是一种无监督学习方法,它用来寻找一组“超完备”基向量来更高效地表示样本数据。虽然形如主成分分析技术(PCA)能使我们方便地找到一组“完备”基向量,但是这里我们想要做的是找到一组“超完备”基向量来表示输入向量(也就是说,基向量的个数比输入向量的维数要大)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数ai
不再由输入向量唯一确定。因此,在稀疏编码算法中,我们另加了一个评判标准“稀疏性”来解决因超完备而导致的退化(degeneracy)问题。(详细过程请参考:UFLDL Tutorial稀疏编码)

比如在图像的Feature Extraction的最底层要做Edge Detector的生成,那么这里的工作就是从Natural Images中randomly选取一些小patch,通过这些patch生成能够描述他们的“基”,也就是右边的8*8=64个basis组成的basis,然后给定一个test patch, 我们可以按照上面的式子通过basis的线性组合得到,而sparse matrix就是a,下图中的a中有64个维度,其中非零项只有3个,故称“sparse”。
这里可能大家会有疑问,为什么把底层作为Edge Detector呢?上层又是什么呢?这里做个简单解释大家就会明白,之所以是Edge Detector是因为不同方向的Edge就能够描述出整幅图像,所以不同方向的Edge自然就是图像的basis了……而上一层的basis组合的结果,上上层又是上一层的组合basis……(就是上面第四部分的时候咱们说的那样)
Sparse coding分为两个部分:
1)Training阶段:给定一系列的样本图片[x1, x 2, …],我们需要学习得到一组基[Φ1, Φ2, …],也就是字典。
稀疏编码是k-means算法的变体,其训练过程也差不多(EM算法的思想:如果要优化的目标函数包含两个变量,如L(W, B),那么我们可以先固定W,调整B使得L最小,然后再固定B,调整W使L最小,这样迭代交替,不断将L推向最小值。EM算法可以见我的博客:“从最大似然到EM算法浅解”)。
训练过程就是一个重复迭代的过程,按上面所说,我们交替的更改a和Φ使得下面这个目标函数最小。
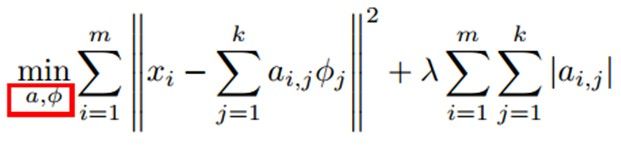
每次迭代分两步:
a)固定字典Φ[k],然后调整a[k],使得上式,即目标函数最小(即解LASSO问题)。
b)然后固定住a [k],调整Φ [k],使得上式,即目标函数最小(即解凸QP问题)。
不断迭代,直至收敛。这样就可以得到一组可以良好表示这一系列x的基,也就是字典。
2)Coding阶段:给定一个新的图片x,由上面得到的字典,通过解一个LASSO问题得到稀疏向量a。这个稀疏向量就是这个输入向量x的一个稀疏表达了。

例如:

收缩自编码(CAE文献:《Contractive auto-encoders: Explicit invariance during feature extraction》)
收缩自编码也很简单,只不过是在损失函数中,加入了一项惩罚项。
以前加入正则项的自编码损失函数一般是这样的:
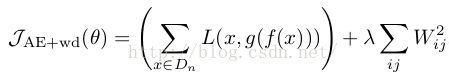
现在采用CAE的损失函数是这样的:

如果网络采用的Sigmod函数,那么Jf(x)的计算公式就是:
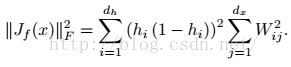
h表示隐层神经元。
栈式自编码
开始讲什么是栈式自编码前,让我们先来了解一些深度学习中的无监督预训练。我们知道,在深度学习中,一般网络都有很多层,因为网络层数一多,训练网络采用的梯度下降,在低层网络会出现梯度弥散的现象,导致了深度网络一直不招人待见。直到2006年的3篇论文改变了这种状况,由Hinton提出了一种深层网络的训练方法,改变了人们对深度学习的态度。Hinton所提出的训练思想,整体过程如下;
A、网络各层参数预训练。我们在以前的神经网络中,参数的初始化都是用随机初始化方法,然而这种方法,对于深层网络,在低层中,参数很难被训练,于是Hinton提出了参数预训练,这个主要就是采用RBM、以及我们本篇博文要讲的自编码,对网络的每一层进行参数初始化。也就是我们这边要学的稀疏自编码就是为了对网络的每一层进行参数初始化,仅仅是为了获得初始的参数值而已(这就是所谓的无监督参数初始化,或者称之为“无监督 pre-training”)。
B、比如采用自编码,我们可以把网络从第一层开始自编码训练,在每一层学习到的隐藏特征表示后作为下一层的输入,然后下一层再进行自编码训练,对每层网络的进行逐层无监督训练。
C、当我们无监督训练完毕后,我们要用于某些指定的任务,比如分类,这个时候我们可以用有标签的数据对整个网络的参数继续进行梯度下降调整。
这就是深层网络的训练思想,总体归结为:无监督预训练、有监督微调。
OK,我们回到本篇文章的主题,从上面的解释中,我们知道稀疏自编码仅仅只是为了获得参数的初始值而已。栈式自编码神经网络是一个由多层稀疏自编码器组成的神经网络,其前一层自编码器的输出作为其后一层自编码器的输入。栈式自编码就是利用上面所说的:无监督pre-training、有监督微调进行训练训练的深度网络模型。接着就让我们来学一学具体的栈式自编码网络训练。下面是来自斯坦福的深度学习教程的一个例子:栈式自编码算法
问题描述:假设我们要训练一个4层的神经网络模型用于分类任务,网络结构如下:
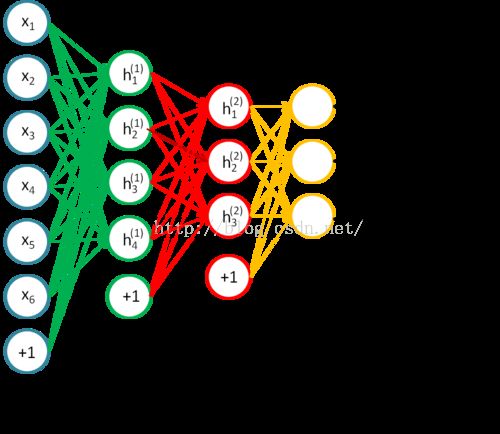
接着我们就讲讲,栈式自编码的训练上面这个网络的方法:
1、无监督pre-training阶段;
A、首先采用稀疏自编码网络,先训练从输入层到H1层的参数:

训练完毕后,我们去除解码层,只留下从输入层到隐藏层的编码阶段。
B、接着我们训练从H1到H2的参数
我们把无标签数据的H1层神经元的激活值,作为H2层的输入层,然后在进行自编码训练:
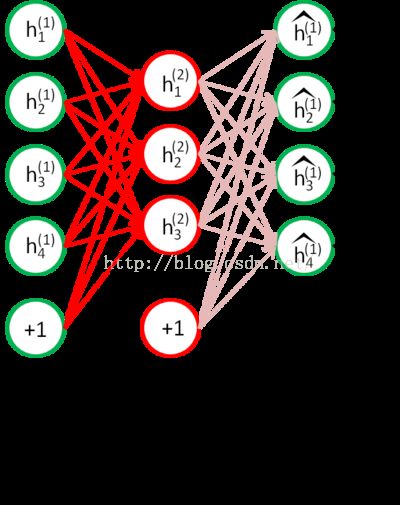
最后训练完毕后,再去除H2层的解码层。如此重复,可以训练更高层的网络,这就是逐层贪婪训练的思想。
C、训练完H2后,我们就可以接分类层softmax,用于多分类任务
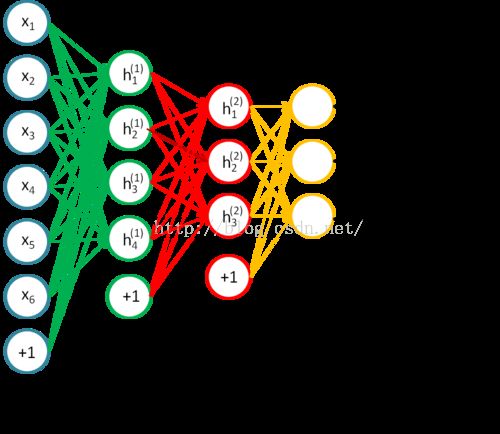
至此参数的初始化阶段就算是结束了,这个过程就是所谓的无监督预训练。
2、有监督微调阶段
后面接着就是,利用上面的参数作为网络的初始值,继续进行神经网络的训练了。
实际上我们是先训练网络n→m→n,得到n→m的变换,然后再训练m→k→m,得到m→k的变换。最终堆叠成SAE,即为n→m→k的结果,整个过程就像一层层往上盖房子,这便是大名鼎鼎的layer-wise unsuperwised pre-training(逐层非监督预训练),正是导致深度学习(神经网络)在2006年第3次兴起的核心技术。
深度自编码器像其他深度神经网络一样能够指数级减少训练数据和计算资源需求。在实践中,深度自编码器比浅层自编码器有更好的压缩性能。
我们之所以很少看到深度自编码器,是因为一般训练深度自编码器的方法是采取贪心策略,逐层训练浅层自编码器。
Deep autoencoder
#Deep autoencoder
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print x_train.shape
print x_test.shape
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(32, activation='relu')(encoded)
decoded = Dense(64, activation='relu')(encoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='sigmoid')(decoded)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy',metrics=['accuracy'])
from keras.callbacks import TensorBoard
autoencoder.fit(x_train, x_train,
epochs=100,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='/tmp/deepautoencoder')])
# encode and decode some digits
# note that we take them from the *test* set
decoded_imgs = autoencoder.predict(x_test)
# use Matplotlib (don't ask)
import matplotlib.pyplot as plt
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
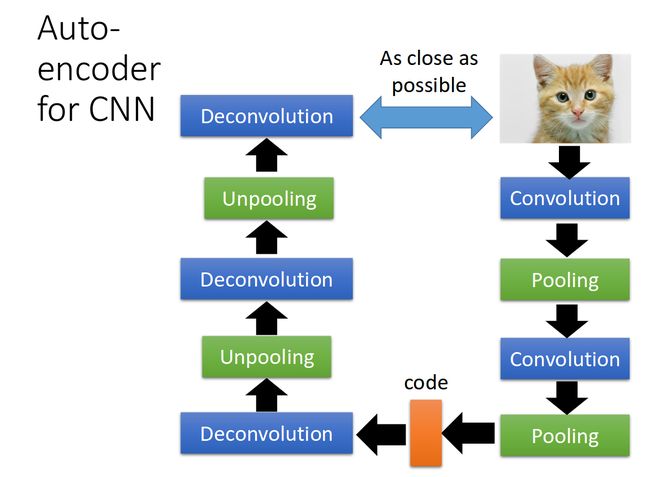

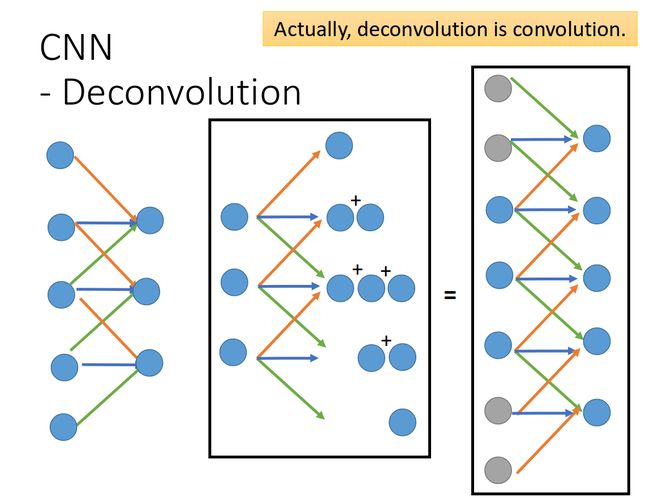
Deconvolution is convolution.
Convolutional autoencoder
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras import backend as K
import matplotlib.pyplot as plt
input_img = Input(shape=(28, 28, 1)) # adapt this if using `channels_first` image data format
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
# at this point the representation is (4, 4, 8) i.e. 128-dimensional
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
from keras.datasets import mnist
import numpy as np
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1)) # adapt this if using `channels_first` image data format
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1)) # adapt this if using `channels_first` image data format
from keras.callbacks import TensorBoard
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='/tmp/Convolutionalautoencoder')])
decoded_imgs = autoencoder.predict(x_test)
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
教程 | 如何使用TensorFlow和自编码器模型生成手写数字
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data')
# 定义输入数据和输出数据
tf.reset_default_graph()
batch_size = 64
X_in = tf.placeholder(dtype=tf.float32, shape=[None, 28, 28], name='X')
Y = tf.placeholder(dtype=tf.float32, shape=[None, 28, 28], name='Y')
Y_flat = tf.reshape(Y, shape=[-1, 28 * 28])
keep_prob = tf.placeholder(dtype=tf.float32, shape=(), name='keep_prob')
dec_in_channels = 1
n_latent = 8
reshaped_dim = [-1, 7, 7, dec_in_channels]
inputs_decoder = 49 * dec_in_channels / 2
def lrelu(x, alpha=0.3):
return tf.maximum(x, tf.multiply(x, alpha))
#定义编码器
def encoder(X_in, keep_prob):
activation = lrelu
with tf.variable_scope("encoder", reuse=None):
X = tf.reshape(X_in, shape=[-1, 28, 28, 1])
x = tf.layers.conv2d(X, filters=64, kernel_size=4, strides=2, padding='same', activation=activation)
x = tf.nn.dropout(x, keep_prob)
x = tf.layers.conv2d(x, filters=64, kernel_size=4, strides=2, padding='same', activation=activation)
x = tf.nn.dropout(x, keep_prob)
x = tf.layers.conv2d(x, filters=64, kernel_size=4, strides=1, padding='same', activation=activation)
x = tf.nn.dropout(x, keep_prob)
x = tf.contrib.layers.flatten(x)
mn = tf.layers.dense(x, units=n_latent)
sd = 0.5 * tf.layers.dense(x, units=n_latent)
epsilon = tf.random_normal(tf.stack([tf.shape(x)[0], n_latent]))
z = mn + tf.multiply(epsilon, tf.exp(sd))
return z, mn, sd
#定义解码器
def decoder(sampled_z, keep_prob):
with tf.variable_scope("decoder", reuse=None):
x = tf.layers.dense(sampled_z, units=inputs_decoder, activation=lrelu)
x = tf.layers.dense(x, units=inputs_decoder * 2 + 1, activation=lrelu)
x = tf.reshape(x, reshaped_dim)
x = tf.layers.conv2d_transpose(x, filters=64, kernel_size=4, strides=2, padding='same', activation=tf.nn.relu)
x = tf.nn.dropout(x, keep_prob)
x = tf.layers.conv2d_transpose(x, filters=64, kernel_size=4, strides=1, padding='same', activation=tf.nn.relu)
x = tf.nn.dropout(x, keep_prob)
x = tf.layers.conv2d_transpose(x, filters=64, kernel_size=4, strides=1, padding='same', activation=tf.nn.relu)
x = tf.contrib.layers.flatten(x)
x = tf.layers.dense(x, units=28*28, activation=tf.nn.sigmoid)
img = tf.reshape(x, shape=[-1, 28, 28])
return img
#将两部分连在一起
sampled, mn, sd = encoder(X_in, keep_prob)
dec = decoder(sampled, keep_prob)
#计算损失函数,并实施一个高斯隐藏分布
unreshaped = tf.reshape(dec, [-1, 28*28])
img_loss = tf.reduce_sum(tf.squared_difference(unreshaped, Y_flat), 1)
latent_loss = -0.5 * tf.reduce_sum(1.0 + 2.0 * sd - tf.square(mn) - tf.exp(2.0 * sd), 1)
loss = tf.reduce_mean(img_loss + latent_loss)
optimizer = tf.train.AdamOptimizer(0.0005).minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#训练网络
for i in range(30000):
batch = [np.reshape(b, [28, 28]) for b in mnist.train.next_batch(batch_size=batch_size)[0]]
sess.run(optimizer, feed_dict = {X_in: batch, Y: batch, keep_prob: 0.8})
if not i % 200:
ls, d, i_ls, mu, sigm = sess.run([loss, dec, img_loss, mn, sd], feed_dict = {X_in: batch, Y: batch, keep_prob: 1.0})
plt.imshow(np.reshape(batch[0], [28, 28]), cmap='gray')
plt.show()
plt.imshow(d[0], cmap='gray')
plt.show()
print(i, ls, np.mean(i_ls))
#生成新数据
randoms = [np.random.normal(0, 1, n_latent) for _ in range(10)]
imgs = sess.run(dec, feed_dict = {sampled: randoms, keep_prob: 1.0})
imgs = [np.reshape(imgs[i], [28, 28]) for i in range(len(imgs))]
for img in imgs:
plt.figure(figsize=(1,1))
plt.axis('off')
plt.imshow(img, cmap='gray')
Deep-learning-with-Python-VAE.ipynb
参考文献
Unsupervised Learning:Deep Auto-encoder
Unsupervised Learning: Deep Auto-encoder
Deep Learning(深度学习)学习笔记整理系列之(四)
Deep Learning(深度学习)学习笔记整理系列之(五)
稀疏编码
栈式自编码算法
深度学习(十二)从自编码到栈式自编码
Deep Learning Tutorials其中有关于AE、DAE、SDAE基于Theano的实现
DeepLearnToolbox 该Toolbox基于Matlab实现,其中有SAE、CAE的实现
为什么稀疏自编码器很少见到多层的?
Stacked Denoising Autoencoders (SdA)
UFLDL教程: Exercise: Sparse Autoencoder