概述
该系列是关于《利用Python进行数据分析》的学习笔记,对应 引言 > 来自bit.ly的1.usa.gov数据 部分。
来自bit.ly的1.usa.gov数据
注意:该部分使用了《利用Python进行数据分析》的数据,可以去pydata-book - github下载数据。另外,使用Spyder进行该次实验,记得将文件目录设置为对应的pydata-book。
下列代码用来载入数据,了解数据格式:
# 数据集对应路径
path = 'ch02/usagov_bitly_data2012-03-16-1331923249.txt'
# 显示数据集的第一行
open(path).readline()
# 此处应该可以看到一长串字符串,为JSON格式
下列代码使用Python中内置的JSON库,将上述JSON格式的字符串转化为Python的字典对象:
import json
path = 'ch02/usagov_bitly_data2012-03-16-1331923249.txt'
records = [json.loads(line) for line in open(path)] # 转化为Python的字典对象
records[0] # 检查第一条记录
对时区进行计数(纯Python代码)
该部分用来对上述数据集中的时区字段(tz字段)进行计数。
# 导入数据,并转化为Python字典对象
# 下列代码会报错,因为并不是所有记录都有'tz'这个字段
# time_zones = [rec['tz'] for rec in records]
time_zones = [rec['tz'] for rec in records if 'tz' in rec]
# 检查数据集中时区字段的前十个
time_zones[:10]
之后再使用纯Python代码对time_zones进行计数,思路是遍历字典慢慢数:
def get_counts(sequence):
counts = {}
for x in sequence:
if x in counts:
counts[x] += 1
else:
counts[x] = 1
return counts
或者,使用Python的标准库defaultdict :
from collections import defaultdict
def get_counts(sequence):
counts = defaultdict(int) # 所有的值均会被初始化为0
for x in sequence:
counts[x] += 1
return counts
注意,defaultdict的特性可以参见The Python Standard Library。简单来说,就是会用特定类型的默认值初始化第一次出现的键。
之后,进行测试:
counts = get_counts(time_zones)
counts['America/New_York'] # 检查New York这个时区的计数情况
如果想得到时区计数的前十名及对应的时区,可以使用如下代码:
def top_counts(count_dict, n=10):
value_key_pairs = [(count, tz) for tz, count in count_dict.items()]
value_key_pairs.sort()
return value_key_pairs[-n:]
top_counts(counts)
当然,你也可以使用Python标准库collections.Counter来完成上述任务:
from collections import Counter
counts = Counter(time_zones) # 计数
counts.most_common(10) # 计数前十
注意,可以参见The Python Standard Library了解更多关于Counter的细节。
使用pandas对时区进行计数
实现对时区的计数,只需要如下代码:
from pandas import DataFrame, Series
import pandas as ps
import numpy as np
frame = DataFrame(records)
print frame # 检视frame,一长串。这被称为frame的摘要视图(summary view)
# frame['tz']返回的为Series对象
# Series对象的value_counts方法会对其进行计数
tz_counts = frame['tz'].value_counts()
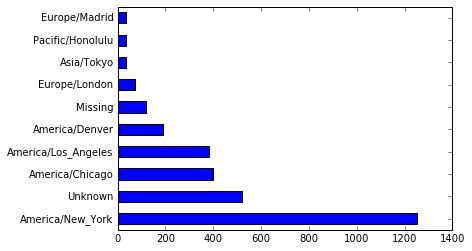
下面我们用这段数据生成一张图片:
clean_tz = frame['tz'].fillna('Missing') # 用`Missing`替换缺失值
clean_tz[clean_tz == ''] = 'Unknown' # 用`Unknown`替换空白值
tz_counts = clean_tz.value_counts()
print tz_counts[:10] # 检视计数的前十项
tz_counts[:10].plot(kind='barh', rot=0) # 绘图,可视化的方式展示前十项
注意,Spyder中更改下设置,可以避免每次都要手动引入NumPy及Matploylib。具体来说,将Spyder > Tools > Preferences > IPython console > Graphics中Support for graphics的Automatically load Pylab and NumPy modules勾选上。
为熟悉pandas,我们再来看看字段a,该字段含有执行URL短缩操作的浏览器、设备、应用程序的相关信息:
frame['a'][1]
# u'GoogleMaps/RochesterNY'
frame['a'][59]
# u'Mozilla/5.0 (iPhone; CPU iPhone OS 5_1 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Mobile/9B176'
我们现在来统计按Windows和非Windows用户对时区统计信息进行分解,为简单起见,我们假定字段a中含有"Windows"就认为该用户为Windows用户,反之就认为为非Windows用户。
cframe = frame[frame.a.notnull()] # 剔除字段`a`为空的数据
# 根据字段`a`分为Windows用户和非Windows用户
operating_system = np.where(cframe['a'].str.contains('Windows'),
'Windows', 'Not Windows')
# 根据时区和操作系统信息进行分组
by_tz_os = cframe.groupby(['tz', operating_system])
# size对分组结果进行计数
# unstack对计数结果进行重塑
agg_counts = by_sz_os.size().unstack().fillna(0)
最后,我们来选取最常出现的时区:
# 用于按升序排列
indexer = agg_counts.sum(1).argsort()
count_subset = agg_counts.take(indexer)[-10:]
# 生成一张堆积条形图
count_subset.plot(kind='barh', stacked=True)
# 生成对应的比例图
normed_subset = count_subset.div(count_subset.sum(1), axis=0)
normed_subset.plot(kind='barh', stacked=True)