在进行机器学习的过程中我们经常需要将数据矢量化,即生成某些特定的vector然后再进行训练和计算。scikit-learn提供了很多vectorizor可以用来实现这个功能,尤其是针对TFIDF算法的相关应用,我们可以很方便的使用scikit-learn的TfidfVectorizer来直接生成对应的TFIDF矩阵,可以非常方便的进行下一步数据处理。
TF-IDF
TF-IDF是为了提取一篇文章的关键字而诞生的算法,为了理解TF-IDF算法,先要理解如下的概念:
- corpus:指所有文档的集合,示例:
# 如下,一个corpus就是一个list,list中每一句话都可以认为是一个简单的文档
corpus = ["hi, you", "I'm so kind", "kiss me, baby"]
- TF(term frequency):指某个词在文章中出现的频率
- IDF(inverse document frequency):简单理解IDF就是某个词在corpus中出现的概率越高,那么它的IDF值越低,比如"the", "a", "you", "me" 此类词在所有文档中都会有较高的频率,所以其IDF值就会很低。
TF-IDF的公式如下图,关键字i针对文章j的tf-idf值:
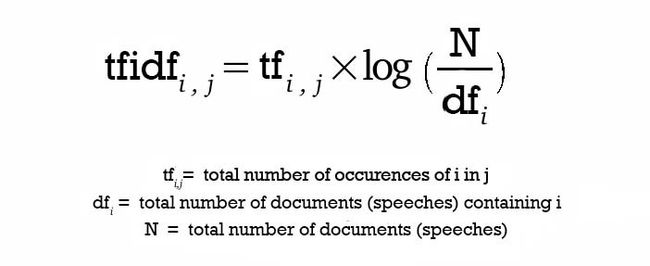
tfidf.jpeg
- 简单理解下TF-IDF公式就是一个词在这篇文章中出现的频率越高,其作为关键字的可能性越大;另一方面,如果一个词在所有文档中都有较高的出现频率,那么这个词成为关键字的可能性就越小(如"the", "a"等)
- tf有时也可以如下计算
1 + log(tf)
TfidfVectorizer
基本用法
在scikit-learn中有专门的vectorizer用于将文本类数据进行矢量化,其中TfidfVectorizer在矢量化的同时还可以计算文档中各个词语的tf-idf值,是非常实用的一个文本数据处理工具。先看代码:
In [105]: from sklearn.feature_extraction.text import TfidfVectorizer
# 每个文档都是list中一个item,我们也可以使用其它iterator,比如通过generator来进行处理
In [106]: corpus = ["this artical is about scikit-learn vectorizor",
...: "do you like it",
...: "if you like it, please click favorite"]
...:
# TfidfVectorizer初始化的时候,可以有非常多的选项,我们后边再详细讲述,目前就用默认参数
In [107]: vec = TfidfVectorizer()
# fit函数一般用于load数据集,此处fit还进行了相关的分词和编码动作
In [108]: vec.fit(corpus)
Out[108]:
TfidfVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), norm='l2', preprocessor=None, smooth_idf=True,
stop_words=None, strip_accents=None, sublinear_tf=False,
token_pattern='(?u)\\b\\w\\w+\\b', tokenizer=None, use_idf=True,
vocabulary=None)
# 通过vocabulary_属性我们可以看到生成的词汇表以及每个单词对应的编码(也可以认为是index)
In [110]: vec.vocabulary_
Out[110]:
{'about': 0,
'artical': 1,
'click': 2,
'do': 3,
'favorite': 4,
'if': 5,
'is': 6,
'it': 7,
'learn': 8,
'like': 9,
'please': 10,
'scikit': 11,
'this': 12,
'vectorizor': 13,
'you': 14}
# 每个单词对应的tf-idf值,比如第0个item1.69314718表示'about'单词对应的tf-idf值
In [111]: vec.idf_
Out[111]:
array([1.69314718, 1.69314718, 1.69314718, 1.69314718, 1.69314718,
1.69314718, 1.69314718, 1.28768207, 1.69314718, 1.28768207,
1.69314718, 1.69314718, 1.69314718, 1.69314718, 1.28768207])
# transform函数用于将corpus转换成matrix,这样的话每个文档就对应一个vector
# 至此,我们就已经把我们的数据corpus转化为了matrix(完成了矢量化)
In [112]: v = vec.transform(corpus)
In [113]: v.shape
Out[113]: (3, 15)
# 从此处可以看出,矢量化之后,其存储的数值还是tf-idf值
In [114]: v.toarray()
Out[114]:
array([[0.37796447, 0.37796447, 0. , 0. , 0. ,
0. , 0.37796447, 0. , 0.37796447, 0. ,
0. , 0.37796447, 0.37796447, 0.37796447, 0. ],
[0. , 0. , 0. , 0.60465213, 0. ,
0. , 0. , 0.45985353, 0. , 0.45985353,
0. , 0. , 0. , 0. , 0.45985353],
[0. , 0. , 0.41756662, 0. , 0.41756662,
0.41756662, 0. , 0.31757018, 0. , 0.31757018,
0.41756662, 0. , 0. , 0. , 0.31757018]])
TfidfVectorizer参数详解
- input : string {‘filename’, ‘file’, ‘content’}
当input='filename'时,fit函数接收的序列包含的是文件名,fit数据时会从文件名对应的文件中读取数据
当input='file'时,序列中就是类文件句柄
否则,序列中就是字符串或者bytes - analyzer : string, {‘word’, ‘char’} or callable
当analyzer='word'时,按照单词进行切词
当analyzer='char'时,按照char进行切分
该参数通常结合ngram_range来一起使用,比如当analyzer='word', ngram_range=(1, 2)时,表示按照最少一个单词,做多两个单词进行切词 - ngram_range : tuple (min_n, max_n),解释如上
- stop_words : string {‘english’}, list, or None (default)
表示可以忽略的词,即会从最终的token列表中删除
当为'english'时,则为sklearn.feature_extraction.stop_words.ENGLISH_STOP_WORDS中定义的词会被忽略
如果为list,list中的单词即为你要忽略的词 - token_pattern : string
这里首先要理解token,token即最终成为我们的属性(feature)的那个词或者字符。token pattern实际是我们可以通过正则表达式来定义我们的token是什么样子的。 - max_df : float in range [0.0, 1.0] or int, default=1.0
max document frequency, 即可以设定当某个词超过一个df(document frequency)的上限时就忽略该词。当为0~1的float时表示df的比例,当为int时表示df数量 - min_df : float in range [0.0, 1.0] or int, default=1
min document frequency, 即可以设定当某个词低于一个df(document frequency)的下限时就忽略该词 - max_features : int or None, default=None
最大feature数量,即最多取多少个关键词,假设max_features=10, 就会根据整个corpus中的tf值,取top10的关键词 - norm : ‘l1’, ‘l2’ or None, optional
是否针对数据做normalization,None表示不做normalization - use_idf : boolean, default=True
是否使用idf,如果为False,则退化为简单的词频统计 - sublinear_tf : boolean, default=False
如果为True,则使用1 + log(tf)来代替tf
常用函数解释
-
fit: 主要作用就是load数据,并进行相应计算,如果是TfidfVectorizor就会去计算tf-idf的值 -
transform: 主要作用是将数据转化为matrix形式 -
fit_transform: 将fit和transform两个步骤放在一起 -
get_feature_names: 获取所有features,即关键字列表
References:
- How to Prepare Text Data for Machine Learning with scikit-learn
- scikit-learn official website
- Understanding Text feature extraction TfidfVectorizer in python scikit-learn