一、背景以及意义
在2012年举办的ImageNet大赛上,由Hinton的学生Alex Krizhevsky训练的AlexNet一举夺得冠军,击败了传统的机器学习方法,达到了37.5%的top-1错误率以及17%的top-5错误率(top-5错误率是指测试图像的正确标签不在模型认为最可能的五个标签之中),取得了历史性的突破。
从此,在计算机视觉领域,深度学习开始崭露头角,Alex随后发表的文章ImageNet Classification with Deep Neural Networks也成为了该领域的一篇开山之作。
那么,AlexNet相较传统方法而言都有哪些显著的突破创新呢?
首先,自然是大量的训练数据。在深度学习发展之前,一直都是一些机器学习的方法(比如SVM)在发挥着重要的作用,这当中主要有两个原因,一个在于神经网络过多的参数比较耗费计算资源,另一个在于原始的数据量通常比较小,因此使用深度神经网络通常容易造成过拟合。而大量的训练数据,就很好地避免了深度神经网络的过拟合问题。
其次,就是采用GPU进行训练。因为卷积神经网络的训练过程中涉及到了很多卷积运算和矩阵运算,采用GPU这种高度并行化的专用计算资源,可以很大地加速整个训练过程。这就解决了深度神经网络在训练的时候时间开销大的问题。没有GPU这样强大的计算资源,Alex也很难搞出像AlexNet这样复杂的模型。
最后,就是在方法上的一些改进了。比如采用ReLU激活函数、随机失活、数据增强等方法。
二、AlexNet的结构
AlexNet包含有5个卷积层,3个全连接层。其中,前两个以及最后一个卷积层后面连接着一个池化层。除此之外,在进行了卷积操作之后,AlexNet还进行了局部响应归一化。
整体的结构如下图所示:
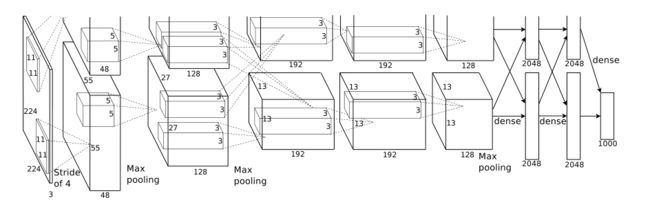
上图中的输入尺寸是224x224,但是在Caffe上随机裁剪了227*227的图像,Tensorflow则加入了padding。若图像的尺寸为227x227,第一层卷积核大小为11x11x3,共有96个卷积核,步长为4,根据公式(227-11)/4 + 1 = 55,卷积后的尺寸为55*55*96,其中两个GPU各用了48个卷积核。
之后进行池化操作,大小为3x3,步长为2,在AlexNet中所有的池化层都是这个参数。
总结之后我们将会得到下图:

注:上图中如果对于步长(stride)没有进行说明,表示步长为1
有了这些信息,我们可以计算出来整个卷积神经网络所需要的参数(不考虑偏置值bias):
96x11x11x3+256x5x5x48+384x3x3x256+384x3x3x192+4096x6x6x256+4096x4096+4096x1000=60,954,656,大约为60M的参数量。
当然,因为当时的GPU(GTX 580)无法承载这么大的参数计算量,所以AlexNet当时是在两个GPU上完成了整个训练过程。因此在结构图中我们可以看到有一些层是分成上下两个部分进行绘制的,对应的层里卷积后结果的通道数也减少了一半。
三、训练方法的改进
介绍完了AlexNet的结构,我们接下来就要谈一下作者在训练过程中一些方法上的改进了。
1.ReLU激活函数
AlexNet并没有采取当时神经网络传统的激活函数sigmoid或者tanh,而是采用了ReLU(Rectified Linear Units)激活函数,也就是线性整流单元。ReLU函数的表达式为f(x) = max(0,x)
那么为什么使用ReLU函数来代替之前的sigmoid等函数呢?
首先就在于ReLU是非饱和的函数,而sigmoid、tanh函数则都是饱和的。那么什么是饱和的函数呢?饱和的函数又存在什么缺点呢?
所谓函数饱和,就是指它的值域是存在于一个固定区间的,有最大值有最小值。根据sigmoid的函数图像我们可以知道sigmoid的取值范围在0与1之间,显然这个函数是饱和的。而根据定义可以看出饱和函数存在挤压函数的输入的缺点。
采用ReLU的原因是使用ReLU作为激活函数收敛的速度非常快,大约是在同等条件下sigmoid函数的五到六倍左右,作者在文章也给出了相对应的证据,如下图所示:
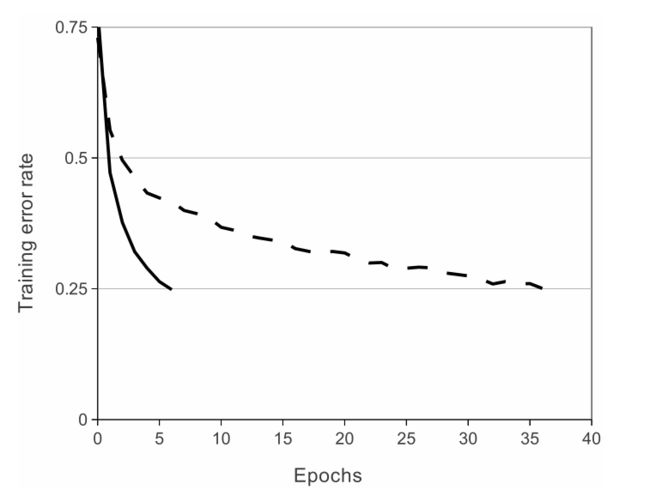
而通过函数表达式我们也可以理解ReLU会这么快的原因,max(0,x)表明当函数值为正时,梯度为1。反之,sigmoid函数在非激活区,梯度几乎趋近于0。而sigmoid的激活区集中在自变量等于0附近,非常小。
可以说,采取ReLU激活函数也是AlexNet中非常成功的一个点,因为其很好地处理了在当时的情况下深度学习方法训练时间过长的问题。
2.数据增强(data augmentation)
在深度学习中,为了防止出现过拟合现象,通常我们需要充足的数据量。通过对有限的训练数据进行某种变换,产生新的数据的过程,就被我们称为数据增强。
而对于图像,我们常用的数据增强手段包括以下两类:首先,就是对于颜色数据的增强,这个包括色彩的饱和度、亮度、对比度等。其次,是对于图像进行平移、旋转、缩放和裁剪的方法。
在训练AlexNet的过程中,一共是采用了两种数据增强的方法:其一是变换和水平翻转,而作者通过随机裁剪实现这种方法。在原始的256x256的图像中随机裁剪出来大小为224x224的图像块,这种做法使得原始的数据集扩大了2048倍。
其二则是改变图像RGB通道的数值。具体来说,就是对于RGB数值进行主成分分析,这就样可以得到图像上的一些重要特征。
在AlexNet中,为了提升效率,作者并没有把变换后的图像保存在硬盘上,而是当GPU上训练前一个批次的图像的时候,使用CPU对于图像做了一些变换,然后丢给GPU进行训练。
3.随机失活(dropout)
随机失活的意思就是在进行网络的前向传播过程中,随机地把一些元素置零。如下图所示:
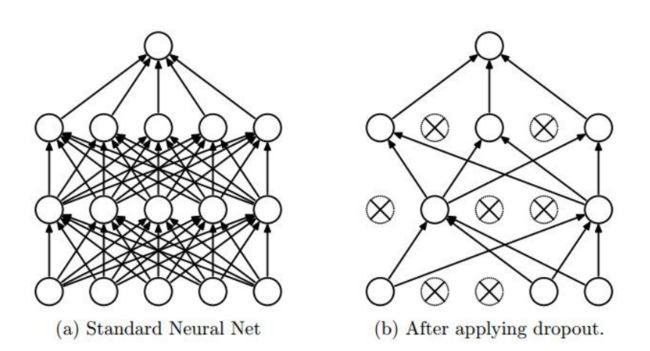
从上图可以看出,一旦一个神经元失活,那么其将断开全部与其它神经元的连接,这样,我们所训练的神经网络就会比原本的网络稀疏很多,因此,随机失活可以有效防止神经网络的过拟合。
另外,值得一说的是,尽管文章中说要使得一个神经元以0.5的概率失活,但是实际中可以使得神经元以任意大小的概率失活,只不过0.5是一个通常情况下的取值而已。
那么为什么随机失活是一个好的想法呢?我们通常有以下两种解释:
解释1:在这个训练的过程中,你无法控制有哪些神经元失活。所以如果你想让你的分类更加精确,你就必须要让你的输出结果依赖于更多的特征。因为你不能完全地依赖于某一个特征,每一个特征都有可能被失活,这样能减少各个特征之间的互相依赖性,增加模型的鲁棒性。
解释2:训练一个由很多小模型集成的大模型,每一个小网络都是一个原本大网络的一个子网络。在随机失活的这个过程中,你其实只是训练了一个在某一次取样中选择的原网络的一部分。换句话说,每一个随机失活之后的网络都是一个新的模型,所以这就可以类似于一个多模型投票机制。
需要注意的是,模型训练和测试的输出是需要经过变换处理的。若训练时不变换,那么在测试时模型的输出值为output的前提下,实际输出值应该变换为output * (1-p),其中p为神经元随机失活的概率。
4.局部响应归一化(Local Response Normalization,LRN)
在AlexNet的模型中,经过第一与第二个卷积层之后,池化操作之前,作者对于数据还进行了归一化。归一化的好处在于提高神经网络的泛化能力,同时也能大幅度提升神经网络的训练速度。
LRN实际上是模拟生物的神经系统抑制机制,这种归一化方式使得响应比较大的数值相对能够更大。其公式为:

其中,a^i_{x,y}表示第i个卷积核在(x,y)坐标处的feature map,而k,n,α,β则是我们需要调整的超参。在文章中作者给出了具体的超参数值:k=2,n=5,α=10^(-4),β = 0.75
但是实际中LRN对于训练的帮助意义不是很大,有时候还会起到反效果,之后人们也意识到了LRN对于卷积神经网络而言并不是必须的,因此从VGGNet之后就将LRN去掉了。
5.重叠池化(Overlapping Pooling)
重叠池化的意思就是在池化过程中,步长是小于核的大小的。这样池化之后的feature map的感受野会存在部分重叠。这也算是一个创新点吧,因为之前传统的卷积神经网络的池化过程都是不重叠的。
四、训练细节
作者采用了SGD + momentum + weight decay的训练方式。在初始化的时候,将权值设置为均值为0,标准差为0.01的高斯分布的随机数值。并且在第2,4,5这几个卷积层以及全连接层都设置了数值为1的偏置值,使得ReLU尽量处于激活区(即输出大于0)
五、结果
作者在文章中给出了AlexNet与其它方法的结果对比,如下图所示:

第一行是2010年的最佳结果,当时使用的方法是对稀疏编码模型生成的预测求平均,第二行是从2010年之后AlexNet夺冠之前的最好结果,使用的方法是对在Fisher向量上训练的两个分类器的结果求平均。
可以看到,使用卷积神经网络的方法几乎是“吊打”之前的模型给出的最好结果。这也是AlexNet出现的最重要的意义:开启了深度学习方法应用在图像识别领域上的一个新时代。