引子:系列的前两期我们分别实现了自动回复和热搜查询功能,由于是分别按照独立的内容来写,没有形成结构化的项目。这一期主要是要优化项目结构,同时为我们的微信助手添加一个短视频下载的功能。本篇文章略长,只关心新功能的同学可以直接拉到新功能介绍。
项目结构整理
微信助手要成为的目标是一套拥有多种功能的系统,而且功能上要具有易扩展的特性。前面的两篇文章都是作为独立的功能模块开发的,项目文件树如下所示:
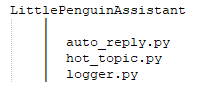
我们看到除了两个功能模块代码和一个日志系统代码,项目再没有其他任何文件,设置两个功能模块目前只能单独运行,还没有组成一个有机的整体,而且这也导致在开发新的功能模块时比较困难。所以为了达到目标,项目在结构上的优化是十分有必要的。
下面我将根据信息的流动方向来一一优化。
命令解析器
当收到微信信息时,程序首先要做的应该是分析这是不是一个指令,如果是指令就要解析这个指令要调用的是哪个功能模块的哪个操作。
自动回复模块和热搜查询模块都有类似的操作,下面是截取的代码片段:
# 自动回复模块
if cmd == '开启自动回复':
...
elif cmd == '关闭自动回复':
...
elif cmd.startswith('设置自动回复,'):
...
# 热搜查询模块
if cmd == '开启热搜':
...
elif cmd == '关闭热搜':
...
elif cmd == '热搜':
...
elif cmd.startswith('热搜,'):
...认真观察会发现,自动回复模块的指令中都包含自动回复这四个字,同样,热搜查询模块的指令中都包含热搜这两个字。所以只要收到的微信信息里包含这些信息,就认为这条信息可能是对应模块的指令,程序会将这条信息送入对应的模块进行下一步的解析。
进一步观察发现,各模块的指令有很大的相似性:每个模块都包含类似开启,关闭,设置的指令。不同的是,查询类型的模块可能还包含默认值查询和自定义查询。
为了解耦合以及代码可读性,同时结合上面的分析,需要新建一个命令解析器cmd_parser.py文件专门负责解析信息。这个命令解析器会分析收到的信息是不是指令,是指令的话还会分析属于哪个模块的什么指令,代码大致如下所示:
if '自动回复' in msg:
module = 'auto_reply'
if msg.startswith('开启自动回复'):
cmd = 'open'
elif msg.startswith('关闭自动回复'):
cmd = 'close'
elif msg.startswith('设置自动回复,'):
cmd = 'set'
...
elif '热搜' in msg:
module = 'hot_topic'
if msg.startswith('开启热搜'):
cmd = 'open'
elif msg.startswith('关闭热搜'):
cmd = 'close'
elif msg.startswith('设置热搜,'):
cmd = 'set'
...
elif msg.startswith('热搜,'):
cmd = 'begin'
...
elif msg == '热搜':
cmd = 'default'
else:
print('不是指令!')为了代码的可读性,代码中将几个指令固定为open,close,set,同时查询指令固定为default和begin。后续只需要根据module和cmd的值就知道要去哪个模块执行哪个命令了。命令解析器的另一个作用就是在确认是指令时,解析出这个命令的参数,传递给命令分发器。
命令分发器
目前看来,命令分发器其实没有特别的必要,直接在命令解析器中实现命令的分发就可以。但长期来看,随着模块越来越多,每增加一个模块要修改很多处的代码,这无疑增加了维护的难度,也让代码可读性大打折扣。
所以新建一个文件夹components,把所有模块的代码移动到这里来。同时,增加一个命令分发器distributor.py,代码如下:
# In distributor.py
from components.auto_reply import auto_reply
from components.hot_topic import hot_topic
distributor = {
'auto_reply': auto_reply,
'hot_topic': hot_topic,
}
# In cmd_parser.py
from cmd_parser import distributor
...
distributor[module](sender, cmd, paras)
...这样,增加命令分发器之后,命令解析器成为一个通用框架,所有新的模块都要先经过命令解析器的解析后才能到命令分发器进行分发。
命令执行器
一个命令被分发到各个模块中,最后就要在模块内部被执行,所以这里的命令执行器其实就是模块本身。
由于前面已经为各种命令代码进行了标准化,所以在模块内部只需要按照对应的代码分别处理即可。在开发新的模块时也必须遵循这样的规则,示例如下:
import itchat
from utils.logger import logger
def auto_reply(sender, cmd, paras):
logger.info('recieved: sender={}, cmd={}, paras={}'.format(sender, cmd, str(paras)))
if 'default' == cmd:
...
if 'open' == cmd:
...
elif 'close' == cmd:
...
elif 'set' == cmd:
...全局变量写进配置文件
上面根据信息处理的流程对项目结构进行了优化,下面从项目配置方面进行优化。
前面的文章中,所有需要自定义的内容都是通过全局变量的方式实现的,如下:


为了便于后期的维护,现在全部改为配置文件的方式。新建一个config.py文件,如下:
switches = {
'auto_reply': False,
'hot_topic': True,
}
settings = {
'auto_reply': '【自动回复】工作中,有事请留言!',
'hot_topic_platform': '',
'hot_topic_limit': 0,
}【本文来自微信公众号Titus的小宇宙,ID为TitusCosmos,转载请注明!】
【为了防止网上各种爬虫一通乱爬还故意删除原作者信息,故在文章中间加入作者信息,还望各位读者理解】
这样只需要在使用的地方引入一下,就可以使用了,比如:
# -*-coding=utf8-*-
from config import switches, settings
import itchat
from utils.logger import logger
def auto_reply(sender, cmd, paras):
logger.info('recieved: sender={}, cmd={}, paras={}'.format(sender, cmd, str(paras)))
if 'default' == cmd and switches['auto_reply']:
itchat.send_msg(settings['auto_reply'], sender)
return
if 'open' == cmd:
switches['auto_reply'] = True
itchat.send_msg('已开启自动回复!', sender)
elif 'close' == cmd:
switches['auto_reply'] = False
itchat.send_msg('已关闭自动回复!', sender)
elif 'set' == cmd:
settings['auto_reply'] = paras[0]
itchat.send_msg('已设置自动回复内容!', sender)优化后的结构
接着前面的优化,现在把所有工具性的代码移动到新建的utils文件夹中。最后的项目文件树就是下面这样了:

项目第一阶段的优化就到此结束了。
短视频下载功能
我们在刷皮皮虾或者抖音的时候,偶尔会碰到自己特别想保存下来的短视频,结果却发现无法保存,这个时候就会特别的糟心。为了不再糟心,微信助手特意解决了这一问题。
获取分享链接
不管是皮皮虾还是抖音里的短视频,都可以分享到微信,分享的文本里就包含这个视频所在网页的地址。首先通过正则表达式解析出分享文本里面的url:
import re
pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
url = re.findall(pattern, string)上面的正则表达式是专门用来匹配文本中的网址的,因为分享的文本中默认是只有一个网址的,所以url[0]肯定就是我们要找的网址了。
获取视频地址
我们以皮皮虾的视频https://h5.pipix.com/s/7TC2Gk/为例,打开谷歌浏览器,开启开发者工具然后回车。
首先注意到网址栏的网址被重定向到了https://h5.pipix.com/item/6809239849397131528?app_id=1319&app=super×tamp=1585401078&user_id=51901622841&carrier_region=cn®ion=cn&language=zh&utm_source=weixin:
![]()
然后打开开发者工具的XHR标签页发现有一个请求https://h5.pipix.com/bds/webapi/item/detail/?item_id=6809239849397131528&source=share:
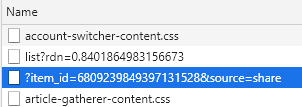
它的返回值里面信息特别丰富,其中就发现了视频的地址:

我们打开这个地址看是不是真能显示出视频:

果然是我们想要的。我们倒回去观察,发现XHR请求中只有一个未知参数item_id,而这个参数在重定向的网址中有出现过:
![]()
这下问题就容易多了,代码如下:
import requests
r = requests.get('https://h5.pipix.com/s/7TC2Gk/')
item_id = r.url.split('?')[0].split('/')[-1]
r = requests.get('https://h5.pipix.com/bds/webapi/item/detail/?item_id={}&source=share'.format(item_id), headers=headers)
pipixia = json.loads(r.text)
video_url = pipixia['data']['item']['video']['video_download']['url_list'][0]['url']保存视频
有了视频地址很容易就可以保存视频了,只不过因为这个是视频文件,所以不能像写文本一样,需要用二进制模式:
video = requests.get(video_url).content
with open(save_path, 'wb') as f:
f.write(video)同时要注意,微信对要发送文件的大小是有限制的,所以需要先判断下载的文件是否超出限制,对不符合的视频要做对应的处理才能正常发送。这不是本篇的主要内容,这里就不展开了。
其他平台的视频下载原理也是大同小异。至此,短视频下载功能就实现好了,按照前半段的设置可以很方便的集成到项目中。
后记
到目前为止,微信助手已经有如下的功能,任何有想法或者建议的同学都可以后台留言一起交流。想要体验的同学可以后台留言体验获取联系方式。

不管写什么,希望能跟更多人沟通,有问题或者需求随时欢迎交流。
我所有的项目源码都会放在下面的github仓库里面,有需要可以参考,有问题欢迎指正,谢谢!
https://github.com/TitusWongCN/【Python开发微信助手】往期推荐:
下面是我的公众号,里面记载了一些我有兴趣可以扫一下: