1. Bit Map算法简介
来自于《编程珠玑》。所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
2、 Bit Map的基本思想
我们先来看一个具体的例子,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0,如下图:

然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作 p+(i/8)|(0x01<<(i%8)) 当然了这里的操作涉及到Big-ending和Little-ending的情况,这里默认为Big-ending),因为是从零开始的,所以要把第五位置为一(如下图):

然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
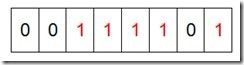
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。
优点:
1.运算效率高,不许进行比较和移位;
2.占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:
所有的数据不能重复。即不可对重复的数据进行排序和查找。
算法思想比较简单,但关键是如何确定十进制的数映射到二进制bit位的map图。
3、 Map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:
bitmap表为:
a[0]--------->0-31
a[1]--------->32-63
a[2]--------->64-95
a[3]--------->96-127
..........
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
如题:
给你一个文件,里面包含40亿个整数,写一个算法找出该文件中不包含的一个整数, 假设你有1GB内存可用。
如果你只有10MB的内存呢?
一个位代表一个数据,那40一个数据大概要40*10^8*bit = 0.5GB,满足内存要求。
首先我们用int来表示:int bmap[1+N/32]; //N是总数,N=40亿,一个int32bit
然后我们插入一个整数val,要先计算val位于数组bmap中的索引:index = val/32;
比如整数33,index=33/32=1,第33位于数组中的index=1
比如整数67,index=67/32=2,位于数组中index=2
然后在计算在这个index中的位置,因为数组中的每个元素有32位
33,index=1,在1中的位置为33%32=1
67,index=2,在2中的位置为67%32=3
然后就是标识这个位置为1:
bmap[val/32] |= (1<<(val%32));
33: bmap[1] != (1<<1);//xxxxxx1x,红丝位置被置为1
67: bmap[2] != (1<<3);//xxxx1xxx
void setVal(int val)
{
bmap[val/32] |= (1<<(val%32));
//bmap[val>>5] != (val&0x1F);//这个更快?
}
怎样检测整数是否存在?
比如我们检测33,同样我们需要计算index,以及在index元素中的位置
33: index = 1, 在bmap[1]中的位置为 1,只需要检测这个位置是否为1
bmp[1] &(1<<1),这样是1返回true,否侧返回false
67:bmp[2]&(1<<3)
127:bmp[3]&(1<<31)
bool testVal(int val)
{
return bmap[val/32] & (1<<(val%32));
//return bmap[val>>5] & (val&0x1F);
}
现在我们来看如果内存要求是10MB呢?
这当然不能用bitmap来直接计算。因为从40亿数据找出一个不存在的数据,我们可以将这么多的数据分成许
多块, 比如每一个块的大小是1000,那么第一块保存的就是0到999的数,第2块保存的就是1000 到1999的数……
实际上我们并不保存这些数,而是给每一个块设置一个计数器。 这样每读入一个数,我们就在它所在的块对应的计数器加1。
处理结束之后, 我们找到一个块,它的计数器值小于块大小(1000), 说明了这一段里面一定有数字是文件中所不包含的。然后我们单独处理
这个块即可。接下来我们就可以用Bit Map算法了。我们再遍历一遍数据, 把落在这个块的数对应的位置1(我们要先把这个数
归约到0到blocksize之间)。 最后我们找到这个块中第一个为0的位,其对应的数就是一个没有出现在该文件中的数。)
4、 Bit-Map的应用
1)可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下。
2)去重数据而达到压缩数据
5、 具体实现(JAVA)
【问题实例】
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。
位图法需要的空间很少(依赖于数据分布,但是我们也可以通过一些放啊发对数据进行处理,使得数据变得密集),在数据比较密集的时候效率非常高。例如:8位整数可以表示的最大十进制数值为99999999,如果每个数组对应于一个bit位,那么把所有的八进制整数存储起来只需要:99Mbit = 12.375MB.
实际上,Java jdk1.0已经提供了bitmap的实现BitSet类,不过其中的某些方法是jdk1.4之后才有的。
分别使用自己实现的BitMap和jdk的BitSet类:
1 //去除重复并排序
2 import java.util.Arrays;
3 import java.util.BitSet;
4 import java.util.Random;
5
6 /**
7 * @author 8 * @date Time:
9 * @des:
10 */
11 public class BitMap {
12 int ARRNUM = 800;
13 int LEN_INT = 32;
14 int mmax = 9999;
15 int mmin = 1000;
16 int N = mmax - mmin + 1;
17
18 public static void main(String args[]) {
19 new BitMap().findDuplicate();
20 new BitMap().findDup_jdk();
21 }
22
23 public void findDup_jdk() {
24 System.out.println("*******调用JDK中的库方法--开始********");
25 BitSet bitArray = new BitSet(N);
26 int[] array = getArray(ARRNUM);
27 for (int i = 0; i < ARRNUM; i++) {
28 bitArray.set(array[i] - mmin);
29 }
30 int count = 0;
31 for (int j = 0; j < bitArray.length(); j++) {
32 if (bitArray.get(j)) {
33 System.out.print(j + mmin + " ");
34 count++;
35 }
36 }
37 System.out.println();
38 System.out.println("排序后的数组大小为:" + count );
39 System.out.println("*******调用JDK中的库方法--结束********");
40 }
41 //下面是自己实现的方法:
42 public void findDuplicate() {
43 int[] array = getArray(ARRNUM);
44 int[] bitArray = setBit(array);
45 printBitArray(bitArray);
46 }
47
48 public void printBitArray(int[] bitArray) {
49 int count = 0;
50 for (int i = 0; i < N; i++) {
51 if (getBit(bitArray, i) != 0) {
52 count++;
53 System.out.print(i + mmin + "\t");
54 }
55 }
56 System.out.println();
57 System.out.println("去重排序后的数组大小为:" + count);
58 }
59
60 public int getBit(int[] bitArray, int k) {// 1右移 k % 32位 与上 数组下标为 k/32 位置的值
61 return bitArray[k / LEN_INT] & (1 << (k % LEN_INT));
62 }
63
64 public int[] setBit(int[] array) {// 首先取得数组位置下标 i/32, 然后 或上
65 // 在该位置int类型数值的bit位:i % 32
66 int m = array.length;
67 int bit_arr_len = N / LEN_INT + 1;
68 int[] bitArray = new int[bit_arr_len];
69 for (int i = 0; i < m; i++) {
70 int num = array[i] - mmin;
71 bitArray[num / LEN_INT] |= (1 << (num % LEN_INT));
72 }
73 return bitArray;
74 }
75
76 public int[] getArray(int ARRNUM) {
77
78 @SuppressWarnings("unused")
79 int array1[] = { 1000, 1002, 1032, 1033, 6543, 9999, 1033, 1000 };
80
81 int array[] = new int[ARRNUM];
82 System.out.println("数组大小:" + ARRNUM);
83 Random r = new Random();
84 for (int i = 0; i < ARRNUM; i++) {
85 array[i] = r.nextInt(N) + mmin;
86 }
87
88 System.out.println(Arrays.toString(array));
89 return array;
90 }
91 }
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
给你一个文件,里面包含40亿个整数,写一个算法找出该文件中不包含的一个整数, 假设你有1GB内存可用。
如果你只有10MB的内存呢?原文地址:https://www.cnblogs.com/protected/p/6626447.html
-END-
