- 概述
Attention Model 的出现,在sequence model的领域中算是一个跨时代的事件。在Many-to-Many的sequence model中,在decoder network中的每一个time step的输出应该跟encoder network中的不同的time step的值的联系度是不一样的;举个例子,如果咱们将一段中文翻译成英文,如果用传统的Many-to-Many的结构的sequence model来做的话,如果是句子的长度不长的话,咱们的结果准确度也不会很差,但是如果是一段较长的句子的话,咱们的LSTM 中的记忆的Hidden state不能记忆太多的信息,从而导致了咱们的结果可能很差,那么这个时候就很需要咱们的Attention Model啦, 具体的它是如何做到将decoder network中的输出跟encoder network中的每一个time step的值联系的,是咱们这节内容的重点,同时咱们这一节也会中代码实现这个attention model的过程。
- Attention Model的结构分析
Attention Model是由2层LSTM组成的,这2层LSTM layer并不是直接相连的,而是通过Attention简介的将2个LSTM layer连接在一起,这一步的分析咱们分成2个阶段:第一步先分析整体的Attention Model的结构;第二步再分析分析具体的Attention的内部结构。首先咱们先看一下Attention Model的整体结构,如下图所示
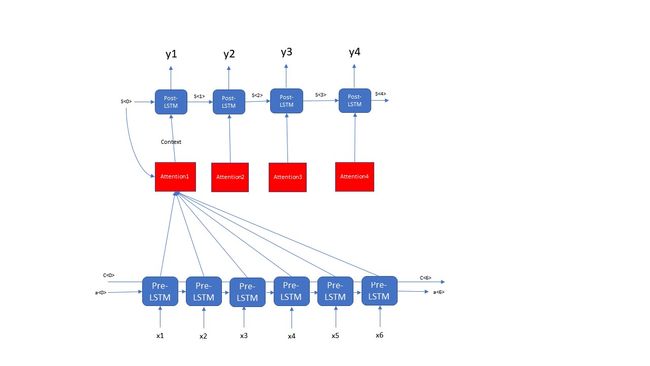
这一步咱们通过演示一个Attention的例子来展示一个Attention model的整体结构,咱们可以看出来Attention Model是由Pre-LSTM layer, Post-LSTM layer, Attention三个主要模块组成的,这里有个细节上图中画错了,大家注意一下,那就是Pre-LSTM layer是Bi-directional的而不是上图的画的那样forward feed的network。每一个time step的Post-LSTM都对应一个相应的Attention, 每一个Attention的输入都由以下两个部分组成:Post-LSTM 前一个time step的hidden state- s
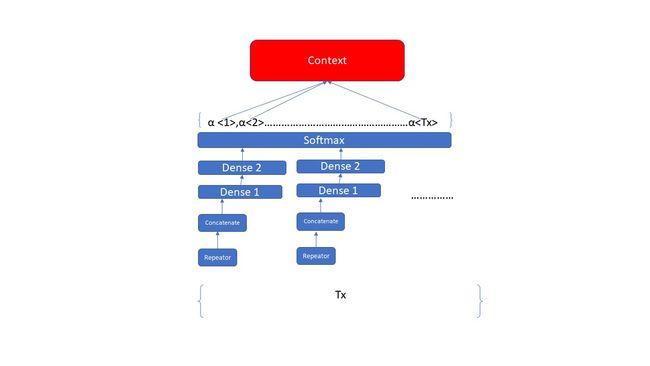
从上图的Attention的结构咱们可以看出来,咱们需要先将t-1步的hidden state 通过repeator去复制Tx份,然后将这些repeator的结构和咱们的输入X 去拼接,生成一个(batch_size, Tx, n_a+n_s)维度的数据,并且将这些数据输入到2层Fully connected 的dense layer中,输出的结果是(batch_size, Tx, 1)的数据结构,最后将这些数据输入到一个softmax layer中,生成一个装有咱们对于每一个Pre-LSTM权重,这些权重之和是1,dimension是(batch_size, Tx); 最后咱们用相应的权重乘以相应的time step 的Pre-LSTM的hidden state,最终生成了咱们的Context,Context的dimension是(batch_size, n_a)。上面的两步共同决定了咱们Attention Model的结构,那么接下来的任务就是实现,用代码来构建上面的Attention Model的结构。
- Attention Model的代码实现
既然上面的结构分析以及展示了咱们Attention Model的细节结构,那么咱在实现上图中的结构也是要分成2部分,第一部分就是用代码构建一个Attention Unit的结构;第二部分就是用代码来构建咱们Attention Model的整体结构。接下来咱们先来看一下构建Attention Model的中的Attention的实现过程,代码如下:
def one_step_attention(a, s_pre): """ Performs one step of attention: Outputs a context vector computed as a dot product of the attention weights "alphas" and the hidden states "a" of the Bi-LSTM. Arguments: a -- hidden state output of the Bi-LSTM, numpy-array of shape (m, Tx, 2*n_a) s_prev -- previous hidden state of the (post-attention) LSTM, numpy-array of shape (m, n_s) Returns: context -- context vector, input of the next (post-attention) LSTM cell """ # Use repeator to repeat s_prev to be of shape (m, Tx, n_s) so that you can concatenate it with all hidden states "a" s_pre = repeator(s_pre) # Use concatenator to concatenate a and s_prev on the last axis # For grading purposes, please list 'a' first and 's_prev' second, in this order. concat = concatenator([a,s_pre]) # Use densor1 to propagate concat through a small fully-connected neural network to compute the "intermediate energies" variable e. e = densor1(concat) # Use densor2 to propagate e through a small fully-connected neural network to compute the "energies" variable energies. (≈1 lines) energies = densor2(e) # Use "activator" on "energies" to compute the attention weights "alphas" alphas = activator(energies) # Use dotor together with "alphas" and "a" to compute the context vector to be given to the next (post-attention) LSTM-cell context = dotor([alphas,a]) return context
注意上图中的repeator, concatenator, densor1, densor2, activator, dotor等等都是在上面函数体外面实例化好了的,他们都是Keras的layer,在这里因为篇幅的原因,我就没有写出来了,这里我主要展示的是Attention Model的结构的构建,而忽略了一些细节处理的部分。上面代码展示了一个attention unit如何将pre-LSTM的每一步的输出转化成post-LSTM的输入的;既然有了这个输入,那么咱们就来看一下咱们如何来实现这个整体的attention model的结构吧
def model(Tx, Ty, n_a, n_s): X = tf.keras.layers.Input(shape=(Tx,vocab_dimension)) s0 = tf.keras.layers.Input(shape = (n_s,)) c0 = tf.keras.layers.Input(shape = (n_s,)) s = s0 c = c0 a = Bidirectional(LSTM(n_a, return_sequence = True))(X) outputs = [] for i in range(Ty): context = one_step_attention(a, s) s,_,c = post_lstm_cell(context, initial_state = [s,c]) output = output_layer(s) outputs.append(output) model = Model(inputs = [X,s0,c0], outputs = outputs) return model