前言
这两天琢磨了下spark-deep-learning和spark-sklearn两个项目,但是感觉都不尽人如意。在training时,都需要把数据broadcast到各个节点进行并行训练,基本就失去实用价值了(tranning数据都会大于单节点内存的好么),而且spark-deep-learning目前还没有实现和tf cluster的结合。所以这个时候转向了开源已久的yahoo的TensorFlowOnSpark项目。简单了过了下他的源码,大致理清楚了原理,这里算是记录下来,也希望能帮到读者。
TensorFlowOnSpark 代码运行剖析
从项目中打开examples/mnist/spark/mnist_spark/mnist_dist.py,
第一步通过pyspark创建SparkContext,这个过程其实就启动了Spark cluster,至于如何通过python启动spark 并且进行相互通讯

第二步是接受一些命令行参数,这个我就不贴了。
第三步是使用标准的pyspark API 从HDFS获取图片数据,构成一个
![]()
接着就是开始进入正题,启动tf cluster了:
cluster = TFCluster.run(sc, mnist_dist.map_fun, args, args.cluster_size, num_ps, args.tensorboard, TFCluster.InputMode.SPARK)
TFCluster.run 里的sc 就是sparkcontext,mnist_dist.map_fun函数则包含了你的tensorflow业务代码,在这个示例里就是minist的模型代码,模型代码具体细节代码我们会晚点说。我们先看看TFCluster.run方法:

上面是确定parameter server和worker的数目,这两个概念是和tf相关的。
接着会启动一个Server:

在driver端启动一个Server,主要是为了监听待会spark executor端启动的tf worker,进行协调。
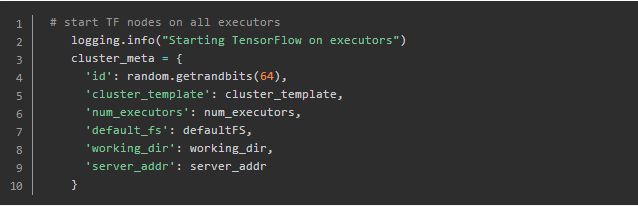
上面的代码获取完整的启动tf cluster所需要的信息。建议大家可以去google下如何手动配置tf cluster,然后就能更深入理解TensorFlowOnSpark是如何预先收集好哪些参数。
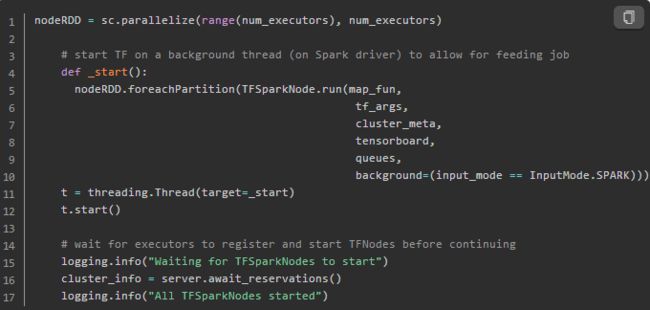
上面的第一段代码其实是为了确保启动cluster_size个task,每个task对应一个partition,每个partition其实只有一个元素,就是worker的编号。通过对partition进行foreatch来启动对应的tf worker(包含ps)。倒数第二行代码我们又看到了,前面的那个server了,它会阻塞代码往下执行,直到所有tf worker都启动为止。
到这里我们也可以看到,一个spark executor可能会启动多个tf worker。
现在我们进入 TFSparkNode.run看看,这里面包含了具体如何启动tf worker的逻辑,记得这些代码已经在executor执行了。

首先定义了一个函数_mapfn,他的参数是一个iter,这个iter 没啥用,就是前面的worker编号,只有一个元素。该函数里主要作用其实就是启动tf worker(PS)的,并且运行用户的代码的:

启动的过程中会启动一个client,连接我们前面说的Server,报告自己成功启动了。
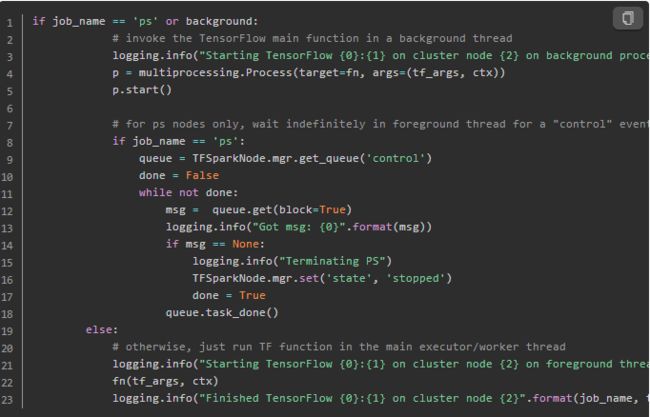
这里会判断是ps还是worker。如果是后台运行,则通过multiprocessing.Process直接运行我们前年提到的mnist_dist.map_fun方法,而mnist_dist.map_fun其实包含了tf session的逻辑代码。当然这个时候模型虽然启动了,但是因为在获取数据时使用了queue.get(block=True) 时,这个时候还没有数据进来,所以会被阻塞住。值得注意的是,这里的代码会发送给spark起的python worker里执行。
在获得cluster对象后,我们就可以调用train方法做真实的训练了,本质上就是开始喂数据:

进入 cluster.train看下,会进入如下代码:
![]()
这里会把数据按partition的方式喂给每个TF worker(通过调用train方法):
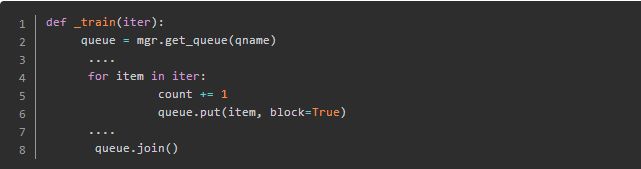
这里会拿到tf的queue,然后通过iter(也就是实际的spark rdd包含的训练数据)往里面放,如果放满了就会阻塞。
直至,大致流程就完成了。现在我们回过头来看我们的业务代码mnist_dist.map_fun,该方法其实是在每个tf worker上执行的:
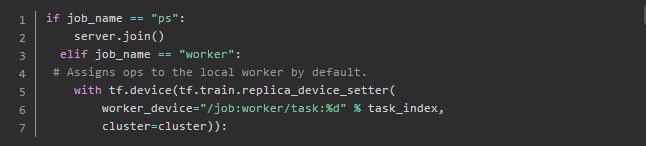
简单的做了判定,如果是ps则停止在这,否则执行构建模型的工作。在with tf.device.. 里面就是开始定义模型什么的了,标准的tf 代码了:

当然,在TensorFlowOnSpark的示例代码里,使用了Supervisor:
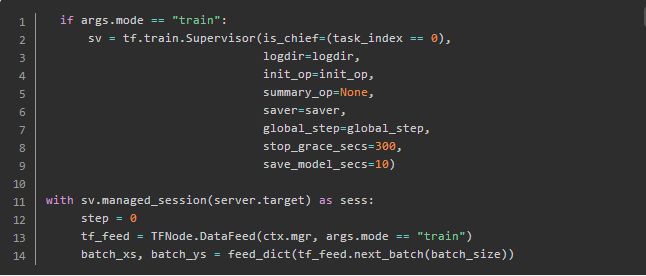
TFNode.DataFeed提供了一个便捷的获取批量数据的方式,让你不用操心queue的事情。
在训练达到必要的数目后,你可以停止训练:

现在整个流程应该是比较清晰了。