摘要:云栖TechDay41期,阿里云资深开发工程师流生带来CodePipeline联动容器的DevOps实践。开发界关注如何让Docker的持续交付更简单、安全、高效。在推出容器服务之后,阿里云研发了开源持续交付工具CodePipeline,它提供多种语言的持续交付向导模板,通过模板快速填写进行持续集成,从而实现多平台、多环境的持续交付。
以下是内容整理:
开发者在云上的“最后一公里问题”
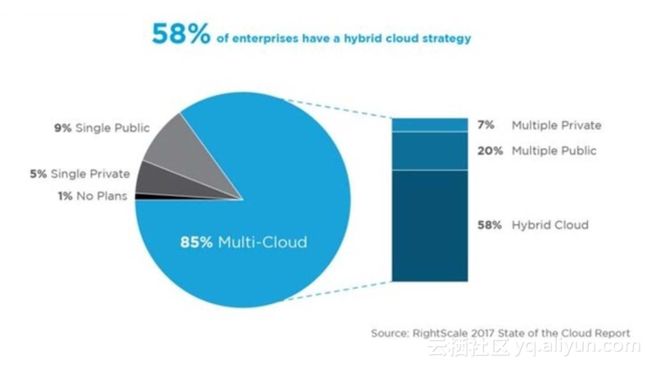
云计算的最后一公里是说云计算技术已经成熟了,很快或者是平滑的落实到企业当中,这幅图其实是RightScale2017年最新关于云计算市场的调研,可以看到只有1%的企业现在没有使用云技术,或者是没有计划去使用云平台,由此可见云计算已经很普及了。云趋势越来越明显,越来越多的开发者把开发工作放到云上,开发者在云上最后一公里问题,其实是要怎么样解决从代码提交到服务发布与运营整个阶段的问题,包括配置管理、集成、测试、部署以及技术运营等领域。
怎么样做好这一步?我觉得就是要开发者和服务运营人员之间能够有一种互相延伸的能力,开发者可以参与到运营的工作里边,运营也可以参与到开发设计工作当中,以及他们之间的互相反馈信息能力,对用户的价值会更凸显出来。走好开发者在云上的最后一公里的技术价值在于:
1. 提高交付的频率;
2. 降低交付的故障率;
3. 缩短交付周期;
4. 缩短平均修复问题的时间;
5. 专注于创造有价值的开发活动。
举个简单例子,我们在刚刚公测产品的时候,只提供了Java和Node.JS两个构建环境,那当时就有用户说我们用的是PHP语言,能不能尽快把构建环境给我们提供出来,我们当时的开发优先级其实是添加海外的构建节点,或者是对开源云code的一些集成。由于能够及时得到用户的需求反馈,所以我们才会把它调整为优先级最高,也意识到用户提出来的才是最有价值的。然后从开发测试到验证到上线大概有三个工作日,用户已经可以用到这个功能。
Jenkins与容器技术
Jenkins工具在开源界多年,其实经过了生产实践检验,它有庞大的社区,认知广泛,1000+插件体系。它是能够集成端到端的持续交付工具链,还给你提供了一些扩展接口,想要自己做集成就可以通过它的接口扩展做开发,然后它的构建部分也提供了接口,如果社区没有这样的插件也可以做自己的二次开发。2016 Java开发工具调查占比60% ,2016 中国开发者白皮书调查占比70%,CI市场占比70%,2017技术趋势预测中最受欢迎持续集成工具第一。

Jekins是master加slave的架构,master负责作业调度,Slave负责作业执行,然后slave节点都可以打标签分类,我们在使用的时候一定要做到构建分类,比如用于测试构建的作业要绑定到用于测试的节点上,不要混用,因为可能会产生数据污染,还可能会因为在构建装包的时候因为依赖版本不同会把旧的升级到新的,导致构建作业的失败。
在开发过程当中可能用到源码仓库、打包构建、部署进行测试、再部署进行验证,以及环境当中出现任何问题都能得到及时沟通反馈,都可以通过Jenkins Master来做,每一个部分其实都是一个作业,如果有依赖可以顺序执行,如果没有依赖可以并行执行,可以最大效率的把构建作业的运行周期缩短。一个Jenkins作业的基本配置,包括基本信息以及源码管理、构建触发器、构建和部署,还有构建后的操作,主要就是一些邮件通知以及钉钉或者其他一些通讯工具的通知。
DevOps
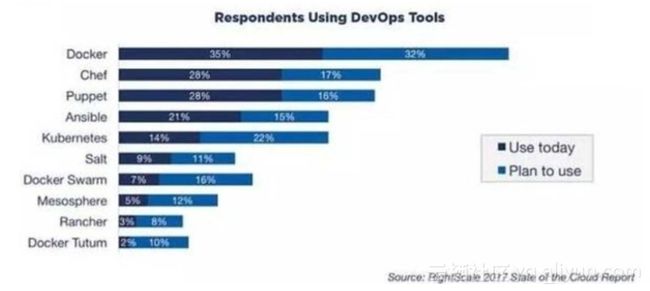
DevOps工具里边容器包括Docker、Chef这些容器技术,容器技术的使用占比已经达到60%以上。
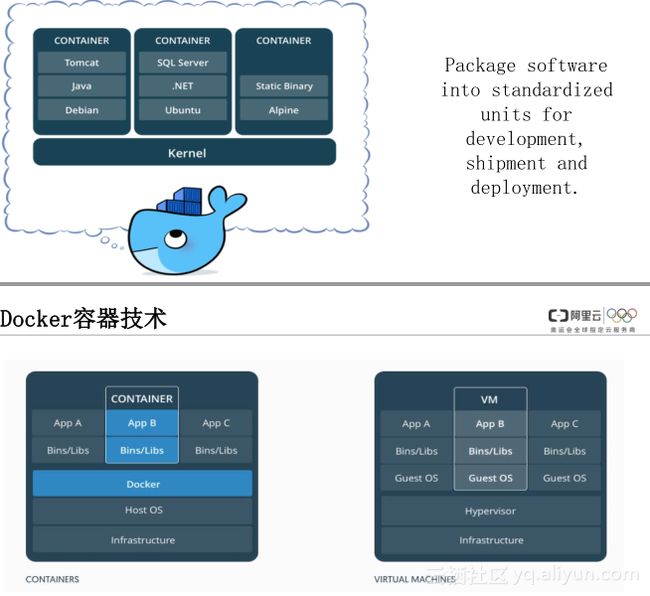
Docker用来打包标准软件包,这些软件包可以用于开发、部署、交付,它跟虚拟机比起来,底层架构容器主要是共享宿主机的一个OS内核,虚拟机要在物理环境上安装一个Hypervisor,虚拟机需要用到CPU内存都是Hypervisor虚拟出来,虚拟机是自己独享自己的操作系统,自己独享自己的内核,容器在占用资源、启动速度以及并发性和性能资源利用率方面都要强于VM,因为它要具备尽量快、资源的利用率高、高性能损害小这些特点,这与DevOps要缩短交付周期理念是很契合的。
交付环境
另外,容器可以打包标准的交付环境,我们有时候可能把64位开发环境下开发的程序放到32位的机器上去运行,会有兼容性的问题,或者还有一些依赖性问题,容器都可以通过打包一个Docker Image把这些解决掉,它的Docker Image联合文件系统一层加一,最下边是Base Image,如Ubuntu等都是Docker公司自己做的,再往上安装自己的依赖,再安装自己的应用,所以打包出来的话,无论你以后要部署到哪里,你的应用都是部署在上边,就不会有兼容性问题以及依赖问题。
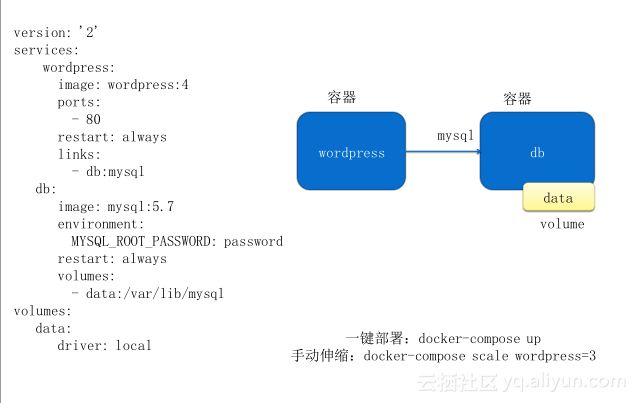
如果你的应用比较复杂,比如说应用后面还依赖一些数据库服务,他们之间要有个先后的启动顺序,以及数据库要提供一些参数给前面的服务,这样的编排就可以用Docker compose,它的优点就是能够把比较复杂的应用简单化。
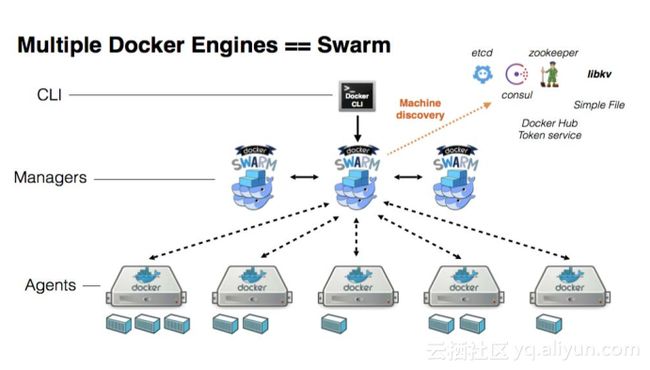
你的应用想要真正的部署在线上服务给用户的话,其实还需要放到集群里边,这个集群可以给你提供网络存储调度以及编排,还可以帮你做服务的高可用性,你可以在里边做多个副本,,不至于有一个节点出问题会导致整个服务停止。
CodePipeline联动容器技术的实践
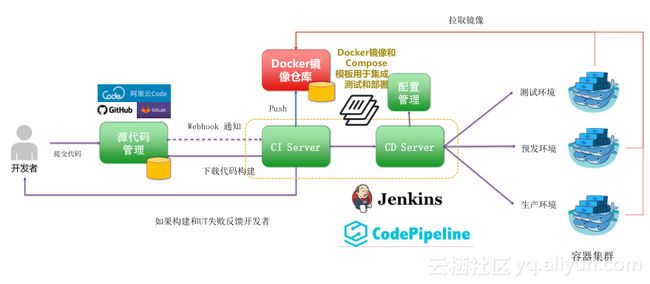
图为开发者从提交代码到部署到自己的测试环境或者是预发环境的一个过程,首先要有一个源代码的管理仓库,可以是私有的,可以是公有的,像阿里云它有自己的阿里云Code产品,然后公网上边还有GitHub,私有现在用的比较多的是Gitlab,其实Jenkins这方面的插件支持都是很丰富的,代码管理仓库下来就是Jenkins CI server和CD server,CI要配一个源码的触发器,你在这边提交代码以后, CI要根据自己的需求配一个触发器来监听动作,自动化的触发作业,作业触发以后要做构建,然后再做打包,再放到Docker Image里边,通过DockerFile打包自己的Docker私有镜像仓库里边。然后下一步部署的时候,通过自己的Docker Compose编排模板来进行部署,要把服务做成几个副本,然后你的服务开放端口是多少,这些东西我们不管是在公有云还是私有云上都可以这样去做,应用部署我们建议使用容器集群去做。
开发者自行搭建DevOps的过程中可能会遇到一些痛点如下:
1. 日常运维。日常运维最主要的是数据方面,哪一些是有用的数据,你要及时的做备份,哪一些是没用的数据,你要及时的做定期处理。备份如果是私有云环境可能要依赖于存储的高可用性做保证,数据清理可能需要自己去写脚本,定期做清理。
2. 升级。如果是自己搭建,Jenkins master的迭代速度说快不快说慢也不慢了,插件这一部分会有很多的漏洞需要你去升级。所以这些东西都需要你自己去监控,及时的去做更新,包括里边应用一些JDK,或者其他开源工具,有更新的时候都得自己去维护。
3. 安全隐患。这些开源工具都是有很多的漏洞需要自己去补。
4. 有些用户使用阿里云的产品,自己在上边搭建Jenkins服务端,可能用到其他阿里云服务,都需要自己去整合,比如说你要用容器服务,就要自己写客户端去调用API使用一些服务。
CodePipeline与容器技术
CodePipeline 的解决方案如下:
1. 一个SaaS化持续交付引擎:无需运维,开箱即用;资源按需使用,动态生成;
2. 全量兼容Jenkins插件:提供经过阿里云安全加固的Jenkins插件,根据开发者需求不断开放。
3. 与阿里云产品生态无缝集成:客户私有OSS提供安全构建分发,支持ECS、容器服务持续部署,我们自己开发了插件已经包括服务用户名密码,在CodePipeline的过程中已经可以自由的调动三个服务所提供的能力。
4. 多维度安全策略保障:容器化构建环境用完即焚,构建物私有仓库存储。
5. 全语言环境支持:公测开放Java、Node.js、PHP、Python等,已支持Go、C++等。
6. 多维度部署方式:支持跨Region部署(经典、VPC),支持本地集群、远程集群混合部署(高级)。
7. 引导式交互:提供特定语言最佳实践的向导模板。及时用自己公司内部的私有云环境,我们也有解决方案可以连接到用户的私有云里边去做一个构建,这是我们做的模板帮用户去使用。

首先就是构建环境,Slave可以是虚拟机,可以是容器,我们为什么不用虚拟机是因为它没法去做动态的创建。如果好多用户都用一个虚拟机去做构建,那他们的数据隔离性其实不是很强,可能会造成数据污染,这样就不是很安全,所以我们用的容器还是临时的Slave模式,我们slave节点资源池是一个Swarm容器集群,在有作业构建任务来的时候,我们才会从集群里边去创建一个容器,然后把容器独享给这个任务,这个任务在容器里边做构建执行,它产生的数据会上传到用户自己的私有仓库里边,等作业构建完了以后,这个容器就会销毁,所以在没有作业运行的时候,CI集群里边是没有Slave节点的,在有作业需要构建的时候我们才给它创建,这样就是最大限度的利用了资源,这样做的好处一个是安全,一个是灵活性,按需分配。
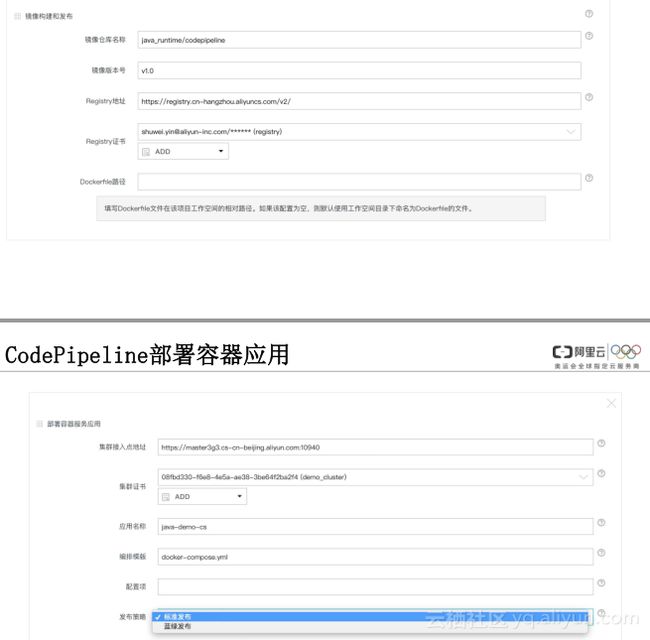
构建节点类型有海外节点跟国内节点,我们的考虑就是不要因为网络的问题影响构建效率,其实大家在自己做的时候还是分类,还有不同语言的构建环境,像源码管理跟触发器管理,我们现在要做的构建和部署有两部分,一个是镜像的构建和发布,一个是部署容器服务的应用。镜像构建就是用户要自己搭一个镜像仓库,要把自己仓库名称版本镜像的版本号放上去,然后仓库的地址以及证书、dockerfile默认git代码里边的Root路径的dockerfile,打包好以后就会上传到仓库里边,然后再把打包好的应用镜像部署到集群里边,这个是集群的接入入口、集群的证书以及应用的名字、编排的模板,最后有一个发布策略,发布策略有两个,一个是标准发布,就是直接新的应用把旧的应用踢下去,先把旧的容器删掉,然后再部署新的,蓝绿发布是旧的服务继续运行,新的服务先上来,上来以后有一个路由权重,网络流量其实还是走旧的,新的网络流量是0,在你经过验证确认以后,再把网络流量调过去,这样就是容器的服务升级,服务升级之间的间隙会尽量降到最低。