全栈 线程与进程
开始之前先问自己几个问题
1、大学用C语言写的main函数里只写了hello word ,面有线程么
2、CPU频率和个数与多线程有什么关系
3、进程和线程的关系
4、线程的访问权限 ,它都可以访问哪些东西
5、线程同步 都有哪几种锁
6、线程中都有哪些坑需要注意
大学用C语言写的main函数里只写了hello word ,面有线程么
In a non-concurrent application, there is only one thread of execution. That thread starts and ends with your application’s main routine and branches one-by-one to different methods or functions to implement the application’s overall behavior.
这是来自苹果官方文档,之所以要摘自文档,只想让答案更有说服力。也就是即使只有一个main函数也是存在线程的。
CPU频率和个数与多线程有什么关系
目前CPU的频率已经达到了一个极限,很难在技术上有很高的突破,于是人们开始向多核发展。当只有一个CPU的时候不存在真正意义上的多线程,只不过是CPU在各个线程不停的切换,切换的频率即CPU的频率。多个CPU才是真正的多线程
进程和线程的关系
线程是CPU调度的基本单位,一个进程至少包含一个线程。Linux内核中并不存在真正意义上的线程概念,所有的执行实体都称为任务(Task),每个人物概念上都类似于一个单线程的进程,具有内存空间、执行实体、文件资源,不过Linux下不同的人物之间可以选择共享内存空间。因此共享了同一个内存空间的多个任务构成了一个进程,这些任务也就成了进程里的线程。另外一个程序可能包含多个进程。可以在mac里执行 ps aux |grep Xcode查看Xcode运行了多个进程
线程的访问权限 ,它都可以访问哪些东西
每个线程都有自己的栈(尽管并非完全无法被其它线程访问,但是一般情况下仍然可以认为是私有的数据)、寄存器(执行流的基本数据,因此为线程私有)和线程局部存储(Thread Local Storage,TLS )。因此从代码上来看,线程私有的有:局部变量、函数的参数、TLS数据。线程间共有的有:全局变量、堆上的数据、函数里的静态变量、打开的文件(A线程打开的文件可以由B线程读写)
官方文档中TLS
Configuring Thread-Local Storage
Each thread maintains a dictionary of key-value pairs that can be accessed from anywhere in the thread. You can use this dictionary to store information that you want to persist throughout the execution of your thread. For example, you could use it to store state information that you want to persist through multiple iterations of your thread’s run loop.
Cocoa and POSIX store the thread dictionary in different ways, so you cannot mix and match calls to the two technologies. As long as you stick with one technology inside your thread code, however, the end results should be similar. In Cocoa, you use the threadDictionary method of an NSThread object to retrieve an NSMutableDictionary object, to which you can add any keys required by your thread. In POSIX, you use the pthread_setspecific and pthread_getspecific functions to set and get the keys and values of your thread.
线程同步 都有哪几种锁
信号量 (Semaphore)
信号量又分为二元信号量 和多元信号量。二元信号量是最简单的一种锁,它只有两种状态:占用和非占用。它适合只能被唯一一个线程独占访问的资源。当二元信号量处于非占用的状态时,第一个试图获取该二元信号量的线程会获得该锁,并将二元信号量之为占用状态,此后其它所有试图获取该二元信号量的新城将会等待,直到该锁被释放。多元信号量会有一个N值,获取信号量后N减一,如果N小于0则等待。访问资源后线程释放信号量N加1,如果N小于1,唤醒下一个等待的线程
互斥量 (Mutex)
互斥量和二元信号量相似,不同的是信号量在整个系统中可以被任意线程获取并释放,而互斥量则有求那个线程获取了互斥量,哪个线程就要负责释放这个锁,其它线程想去释放是不行的。
临界区 (Critical Section)
临界区是比互斥量更加严格的同步手段,在术语中把临界区的锁的获取称为进入临界区,而把锁的释放称为离开临界区。它与互斥量和信号量的区别在于,互斥量和信号量在系统的的任何进程都是可见的,也就是说一个进程创建了一个互斥量和信号量,另一个进程试图去获取该锁是合法的。而临界区的作用范围仅限于本进程。其它进程无法获取该锁。除此之外,临界区具有和互斥量相同的性质。
读写锁 (Read-Write Lock)
对于一段数据,多个线程读写频繁,但是仅仅偶尔写入,如果用以上几种锁就会非常低效,用读写锁更快一点。读写锁的获取又分为共享的(Shared)或独占的(Exclusive),看字面意思也能猜个大概,就不解释了。
条件变量 (Condition Variable)
作用类似于栅栏,使用条件变量可以使许多线程一起等待某个事件的发生,当事件发生时(条件变量被唤醒),所有的线程可以一起恢复执行。
线程中都有哪些坑需要注意
线程安全比较难搞,因为你即使合理用了锁,也不一定能保证线程安全。原因有三:
1、编译器会为了提高速度将一个变量缓存到寄存器中而不写回
2、编译器会在进行优化的时候为了效率交换毫不相干的两条相邻指令的执行顺序
3、早在几十年前,CPU就发展出了动态调度,为了执行程序的时候为了提高效率有可能交换指令的顺序
解决1用volatile,解决后两者用barrier
从AFNetworking看上面iOS里面的多线程
iOS各种多线程的介绍点我
我们主要看多线程相关 所以请将AFNetworking切换到2.x分支,尽管NSURLConnection已经在iOS9.0停用了,but我们只关注多线程。
我们知道实现多线程主要有NSThread、POSIX(pthread)、NSOperation、GCD。而NSThread、NSOperation、GCD都是由pthread实现,只不过它们的使用方法各有不同。首先AFNetworking要面向所有的网络请求,应该有取消的功能,这时可以排出GCD,其次网络请求还有可能需要批量处理,或者请求之间有依赖、或者可以设置线程并发数,这时又可以排出NSThread,现在只剩下了NSOperation。
现在来看NSURLConnection文件夹下三个类AFHTTPRequestOperation、AFURLConnectionOperation、AFHTTPRequestOperationManager。其中AFHTTPRequestOperation继承自AFURLConnectionOperation,而AFURLConnectionOperation又继承自NSOperation。ok,现在看到想看的了,话说回来NSOperation要想实现并发需要做什么 ?
需要重载start isReady isExecuting isFinished isConcurrent ,现在是上代码的时候了。
- (BOOL)isReady {
return self.state == AFOperationReadyState && [super isReady];
}
- (BOOL)isExecuting {
return self.state == AFOperationExecutingState;
}
- (BOOL)isFinished {
return self.state == AFOperationFinishedState;
}
- (BOOL)isConcurrent {
return YES;
}
- (void)start {
[self.lock lock];
if ([self isCancelled]) {
[self performSelector:@selector(cancelConnection) onThread:[[self class] networkRequestThread] withObject:nil waitUntilDone:NO modes:[self.runLoopModes allObjects]];
} else if ([self isReady]) {
self.state = AFOperationExecutingState;
[self performSelector:@selector(operationDidStart) onThread:[[self class] networkRequestThread] withObject:nil waitUntilDone:NO modes:[self.runLoopModes allObjects]];
}
[self.lock unlock];
}
由上面的代码我们可以看到在start又通过performSelector与其它线程进行通信。而这个线程又是怎么来的呢。继续看代码
+ (void)networkRequestThreadEntryPoint:(id)__unused object {
@autoreleasepool {
[[NSThread currentThread] setName:@"AFNetworking"];
NSRunLoop *runLoop = [NSRunLoop currentRunLoop];
[runLoop addPort:[NSMachPort port] forMode:NSDefaultRunLoopMode];
[runLoop run];
}
}
+ (NSThread *)networkRequestThread {
static NSThread *_networkRequestThread = nil;
static dispatch_once_t oncePredicate;
dispatch_once(&oncePredicate, ^{
_networkRequestThread = [[NSThread alloc] initWithTarget:self selector:@selector(networkRequestThreadEntryPoint:) object:nil];
[_networkRequestThread start];
});
return _networkRequestThread;
}
在networkRequestThread这个类方法中创建了一个NSThread的单例,然后紧接着就start了。而在初始化这个NSThread的时候又调用了networkRequestThreadEntryPoint 主要作用就是获取这个线程的currentRunLoop给它设置一个输入源NSPort,然后再run一下,这样这个线程就一直处于工作状态不退出。这个又是干啥呢?
继续看代码
- (void)operationDidStart {
[self.lock lock];
if (![self isCancelled]) {
self.connection = [[NSURLConnection alloc] initWithRequest:self.request delegate:self startImmediately:NO];
NSRunLoop *runLoop = [NSRunLoop currentRunLoop];
for (NSString *runLoopMode in self.runLoopModes) {
[self.connection scheduleInRunLoop:runLoop forMode:runLoopMode];
[self.outputStream scheduleInRunLoop:runLoop forMode:runLoopMode];
}
[self.outputStream open];
[self.connection start];
}
[self.lock unlock];
dispatch_async(dispatch_get_main_queue(), ^{
[[NSNotificationCenter defaultCenter] postNotificationName:AFNetworkingOperationDidStartNotification object:self];
});
}
这里NSURLConnection使用的是代理模式来回调,如果不把它设置到runLoop上执行完这个NSOperation就退出,当NSURLConnection的调用delegate的方法时,delegate已经为空。就不会发生后面的事了。所以必须将NSURLConnection设置一个NSRunLoop。另外这个runLoopMode也是️讲究的,必须是NSRunLoopCommonModes,才能保证手机屏幕在接受手势事件的时候,网络访问不受影响。参考我写的关于NSRunLoop的博客。另外说一句NSRunLoop接受的输入源包括NSPort、NSConnection、NSTimer
另外如果发通知又用GCD来切换到主线程发通知,这样看代码比较清晰吧
dispatch_async(dispatch_get_main_queue(), ^{
NSNotificationCenter *notificationCenter = [NSNotificationCenter defaultCenter];
[notificationCenter postNotificationName:AFNetworkingOperationDidFinishNotification object:self];
});
还有一个比较有趣的是下面的代码
- (void)resume {
if (![self isPaused]) {
return;
}
[self.lock lock];
self.state = AFOperationReadyState;
[self start];
[self.lock unlock];
}
- (void)setState:(AFOperationState)state {
if (!AFStateTransitionIsValid(self.state, state, [self isCancelled])) {
return;
}
[self.lock lock];
NSString *oldStateKey = AFKeyPathFromOperationState(self.state);
NSString *newStateKey = AFKeyPathFromOperationState(state);
[self willChangeValueForKey:newStateKey];
[self willChangeValueForKey:oldStateKey];
_state = state;
[self didChangeValueForKey:oldStateKey];
[self didChangeValueForKey:newStateKey];
[self.lock unlock];
}
看到没lock多次,再看lock的类型是NSRecursiveLock 即递归锁。
是时候亮亮iOS的同步的法宝了
法宝出处
原子操作(AtomicOperations)
只支持基本类型,比如int 什么的,优点:快。快到什么程度呢?它在相同的CPU情况下速度的是互斥锁的四分之一。但是用的比较少,众多代码中在RAC库中见到过,在这里提一下防止看到代码不知道啥意思就尴尬了。
如RACCommand的
- (void)setAllowsConcurrentExecution:(BOOL)allowed {
[self willChangeValueForKey:@keypath(self.allowsConcurrentExecution)];
if (allowed) {
OSAtomicOr32Barrier(1, &_allowsConcurrentExecution);
} else {
OSAtomicAnd32Barrier(0, &_allowsConcurrentExecution);
}
[self didChangeValueForKey:@keypath(self.allowsConcurrentExecution)];
}
OSMemoryBarrier和volatile
作用上面已经说了,用的也比较少,只在RAC库中见过。由此可见RAC的代码还是挺屌的啊
各种锁 Locks
查看NSLock代码头文件中列了四种NSLock、NSConditionLock、NSRecursiveLock、NSCondition。既然只有这几个类,说明只有这几个常用,AFNetworking不就是用的NSRecursiveLock锁么,虽然在上面苹果官方文档我看到的是Mutex、Recursive lock、Read-write lock、Distributed lock、Spin lock、Double-checked lock
Conditions
好吧 我也是只在RAC中见到过
@synchronized
这个用的比较多,苹果建立@synchronized的初衷就是方便开发者快速的实现代码同步,语法如下:
@synchronized(obj) {
//code
}
有人在测试项目的main.m中写了下面的代码
void testSync()
{
NSObject* obj = [NSObject new];
@synchronized (obj) {
}
}
然后在Xcode中选择菜单Product->Perform Action->Assemble “main.m”,就得到了如下的汇编代码:
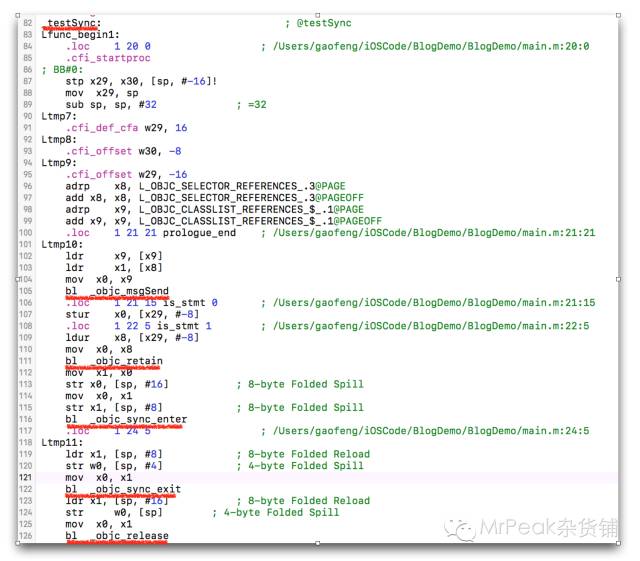
_objc_sync_enter、_objc_sync_exit这两个函数应该就是synchronized进入和退出的调用
上objc-sync.mm源码
// Begin synchronizing on 'obj'.
// Allocates recursive mutex associated with 'obj' if needed.
// Returns OBJC_SYNC_SUCCESS once lock is acquired.
int objc_sync_enter(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, ACQUIRE);
assert(data);
data->mutex.lock();
} else {
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
}
return result;
}
// End synchronizing on 'obj'.
// Returns OBJC_SYNC_SUCCESS or OBJC_SYNC_NOT_OWNING_THREAD_ERROR
int objc_sync_exit(id obj)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, RELEASE);
if (!data) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
} else {
bool okay = data->mutex.tryUnlock();
if (!okay) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
}
}
} else {
// @synchronized(nil) does nothing
}
return result;
}
typedef struct SyncData {
struct SyncData* nextData;
DisguisedPtr object;
int32_t threadCount; // number of THREADS using this block
recursive_mutex_t mutex;
} SyncData;
synchronized是使用的递归mutex来做同步。
那么@synchronized后面跟的参数是做什么用的呢
看objc_sync_enter 里面的 SyncData* data = id2data(obj, ACQUIRE);,跟进id2data,看到spinlock_t *lockp = &LOCK_FOR_OBJ(object);再跟进LOCK_FOR_OBJ
#define LOCK_FOR_OBJ(obj) sDataLists[obj].lock
#define LIST_FOR_OBJ(obj) sDataLists[obj].data
static StripedMap sDataLists;
template
class StripedMap {
enum { CacheLineSize = 64 };
#if TARGET_OS_EMBEDDED
enum { StripeCount = 8 };
#else
enum { StripeCount = 64 };
#endif
struct PaddedT {
T value alignas(CacheLineSize);
};
PaddedT array[StripeCount];
static unsigned int indexForPointer(const void *p) {
uintptr_t addr = reinterpret_cast(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount;
}
public:
T& operator[] (const void *p) {
return array[indexForPointer(p)].value;
}
const T& operator[] (const void *p) const {
return const_cast>(this)[p];
}
#if DEBUG
StripedMap() {
// Verify alignment expectations.
uintptr_t base = (uintptr_t)&array[0].value;
uintptr_t delta = (uintptr_t)&array[1].value - base;
assert(delta % CacheLineSize == 0);
assert(base % CacheLineSize == 0);
}
#endif
};
static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData **listp = &LIST_FOR_OBJ(object);
SyncData* result = NULL;
#if SUPPORT_DIRECT_THREAD_KEYS
// Check per-thread single-entry fast cache for matching object
bool fastCacheOccupied = NO;
SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY);
if (data) {
fastCacheOccupied = YES;
if (data->object == object) {
// Found a match in fast cache.
uintptr_t lockCount;
result = data;
lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);
if (result->threadCount <= 0 || lockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
switch(why) {
case ACQUIRE: {
lockCount++;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
break;
}
case RELEASE:
lockCount--;
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount);
if (lockCount == 0) {
// remove from fast cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL);
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
#endif
// Check per-thread cache of already-owned locks for matching object
SyncCache *cache = fetch_cache(NO);
if (cache) {
unsigned int i;
for (i = 0; i < cache->used; i++) {
SyncCacheItem *item = &cache->list[i];
if (item->data->object != object) continue;
// Found a match.
result = item->data;
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy");
}
switch(why) {
case ACQUIRE:
item->lockCount++;
break;
case RELEASE:
item->lockCount--;
if (item->lockCount == 0) {
// remove from per-thread cache
cache->list[i] = cache->list[--cache->used];
// atomic because may collide with concurrent ACQUIRE
OSAtomicDecrement32Barrier(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
// Thread cache didn't find anything.
// Walk in-use list looking for matching object
// Spinlock prevents multiple threads from creating multiple
// locks for the same new object.
// We could keep the nodes in some hash table if we find that there are
// more than 20 or so distinct locks active, but we don't do that now.
lockp->lock();
{
SyncData* p;
SyncData* firstUnused = NULL;
for (p = *listp; p != NULL; p = p->nextData) {
if ( p->object == object ) {
result = p;
// atomic because may collide with concurrent RELEASE
OSAtomicIncrement32Barrier(&result->threadCount);
goto done;
}
if ( (firstUnused == NULL) && (p->threadCount == 0) )
firstUnused = p;
}
// no SyncData currently associated with object
if ( (why == RELEASE) || (why == CHECK) )
goto done;
// an unused one was found, use it
if ( firstUnused != NULL ) {
result = firstUnused;
result->object = (objc_object *)object;
result->threadCount = 1;
goto done;
}
}
// malloc a new SyncData and add to list.
// XXX calling malloc with a global lock held is bad practice,
// might be worth releasing the lock, mallocing, and searching again.
// But since we never free these guys we won't be stuck in malloc very often.
result = (SyncData*)calloc(sizeof(SyncData), 1);
result->object = (objc_object *)object;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t();
result->nextData = *listp;
*listp = result;
done:
lockp->unlock();
if (result) {
// Only new ACQUIRE should get here.
// All RELEASE and CHECK and recursive ACQUIRE are
// handled by the per-thread caches above.
if (why == RELEASE) {
// Probably some thread is incorrectly exiting
// while the object is held by another thread.
return nil;
}
if (why != ACQUIRE) _objc_fatal("id2data is buggy");
if (result->object != object) _objc_fatal("id2data is buggy");
#if SUPPORT_DIRECT_THREAD_KEYS
if (!fastCacheOccupied) {
// Save in fast thread cache
tls_set_direct(SYNC_DATA_DIRECT_KEY, result);
tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1);
} else
#endif
{
// Save in thread cache
if (!cache) cache = fetch_cache(YES);
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result;
}
可以看到 根据传入的参数会获取一个spinlock_t,再进行mutex生成的时候会用到,应该起到一个key的作用吧