1、什么是Fork/Join框架 及产生背景
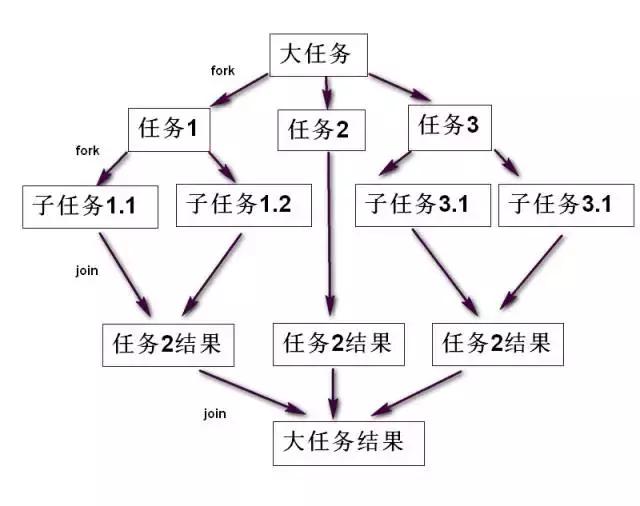
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。上边是书上的定义。
我们用粗话说:Fork/Join是一个框架,来解决执行效率,手段是并行,但是是拆分型的并行!则,如果一个应用能被分解成多个子任务,并且组合多个子任务的结果就能够获得最终的答案,那么这个应用就适合用 Fork/Join 模式来解决。
产生背景:
多核处理器已广泛应用要提高应用程序在多核处理器上的执行效率,只能想办法提高应用程序的本身的并行能力。常规的做法就是使用多线程,让更多的任务同时处理,或者让一部分操作异步执行,这种简单的多线程处理方式在处理器核心数比较少的情况下能够有效地利用处理资源,因为在处理器核心比较少的情况下,让不多的几个任务并行执行即可。但是当处理器核心数发展很大的数目,上百上千的时候,这种按任务的并发处理方法也不能充分利用处理资源,因为一般的应用程序没有那么多的并发处理任务(服务器程序是个例外)。所以,只能考虑把一个任务拆分为多个单元,每个单元分别得执行最后合并每个单元的结果,而fork/join框架就是为这而生的,java7中才认识到了这个问题。
2、工作窃取(work-stealing)算法
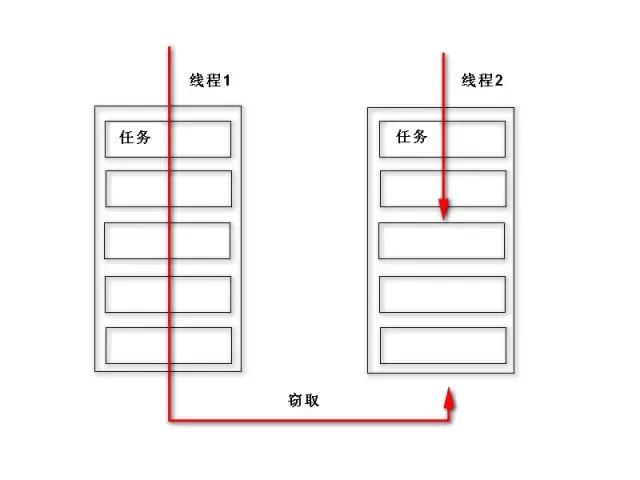
了解这个框架之前我们需要了解一下这其中最终要的算法--工作窃取算法。工作窃取算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下
如果有想学习java的程序员,可来我们的java学习扣qun:79979,2590免费送java的视频教噢!小编是一名5年java开发经验的全栈工程师,整理了一份适合18年学习的java干货,送给每一位想学习Java的小伙伴,欢迎大家一起学习哦。
下边介绍的工作窃取算法的定义我会把我认为重要的东西标记出来,大家着重看一下:
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
3、Fork/Join框架的设计
设计整个框架主要包括两个步骤:
(1)分割任务
分割任务主要指的是将一个fork大类分割成小的任务,但是这些小的任务可能还是很大,所以要不停的分割,直到任务足够小。
(2)执行任务,合并结果
刚才我们说到,不同的任务对应不通的双端队列,这样的话几个不同的队列分别从各自的双端队列中执行任务,子任务执行完成之后将结果都统一的放在一个队列中,这时候启动一个线程从队列里边拿数据,然后将这些数据合并。
说了这么多定义,那么Fork/Join到底是如何工作呢,好 下边我们来看主要用到的类:
ForkJoinTask:我们要执行ForkJoin任务就要创建一个ForkJoinTask任务,这个任务提供fork(),join()机制,通常状况下,我们不需要直接继承ForkJoinTask任务,只需继承他的子类就可以了,框架提供了下边两个子类:
RecursiveAction:用于没有返回结果的任务
RecursiveTask:用于有返回结果的任务
4、Fork/Join框架的异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。使用如下代码:
if(task.isCompletedAbnormally())
{
System.out.println(task.getException());
}
getException方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
5、使用场景
工作中可能会遇到的使用场景:
(1)有大量计算工作的程序,可以将这些计算分别fork之后join
(2)处理大文件,处理大文件的时候我们可以将大文件分割开来,分别处理,最后结果汇总。
(3)处理海量的数据库的程序,因为访问数据库每次消耗性能最大的就是io,访问次数多了,性能就会急剧下降,这样的话我们分开处理,最后汇总结果,可以并发执行。
(4)高并发的消息队列
暂时想到这些,当然工作中远不止这些应用场景。
(5)处理排序算法,具体大家可以看看这个人写的文章,很不错,快排,归并,和桶排序都有分析:http://blog.csdn.net/yinwenjie/article/details/72828691
6、约束条件
(1)除了fork() 和 join()方法外,线程不得使用其他的同步工具。线程最好也不要sleep()
(2)线程不得进行I/O操作
(3)线程不得抛出checked exception
7、和普通的多线程相比有什么优势。
有人说了,想从1+2+3+。。100 这样的程序用普通的多线程也可以实现,是的可以实现,但是fork/join和ThreadPoolExecutor 相比会有什么优势呢?
(1)代码量的问题,fork/join已经是集成的代码,我们拿来直接使用即可,不用自己在写好多代码做判断。
(2)从分治的算法思想到fork/join框架,这种并行性的的融入可以更加高效率的解决一大批的问题。和我们一些传统的多线程应用方式如ThreadPoolExecutor比起来,它有一些自己的特点。一个典型的地方就是work-stealing,它的一个优点是在传统的线程池应用里,我们分配的每个线程执行的任务并不能够保证他们执行时间或者任务量是同样的多,这样就可能出现有的线程完成的早,有的完成的晚。在这里,一个先完成的线程可以从其他正在执行任务的线程那里拿一些任务过来执行。我们可以说这是人家学习雷锋好榜样。这样发挥主观能动性的线程框架肯定办起事来就效率高了。
8、总结
fork-join 方法提供了一种表示可并行化算法的简单方式。所有的排序、搜索和数字算法都可以进行并行分解。随着处理器数量的增长,我们将需要在程序内部使用更多的并行性,以有效利用这些处理器;我在这个fork/join框架中看到的还是分支的思想,就像对三大排序算法,归并排序,堆排序,快排等,都是分治的思想,希望大家可以仔细琢磨,对这个框架起码到会用的状态,有可能会大大提升你的工作效率。