第一周ARTS
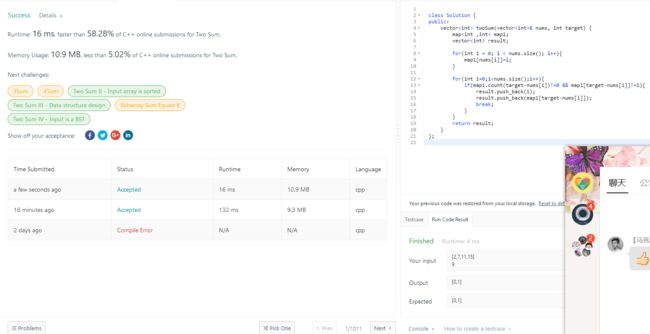
A:TWO SUM
第一种方法我试了暴力破解法,即用两个for循环试出target的加数和被加数,但是时间耗费多。
暴力破解法
方法一tip: 注意函数用法:nums.at(), 访问向量的元素。
第二种方法是从网上学到的哈希图法,第一次学习这种方法,特意去看了一下map的基础用法,map
首先创建哈希表,我们已知了target,以及nums的一个元素,只需要判断target-nums[i]是不是存在即可;
所以我们的key=nums[i]; 而我们的value=i;因为需要判断它是否为同一个元素。
map1.count(x)可以判断x在哈希表内是否存在。当然它判断的是key的值
参考地址
R
文章名:BUSINESS INTELLIGENCE AND ANALYTICS:FROM BIG DATA TO BIG IMPACT
主要讲述了商业智能和分析(BI&A)的运作与影响。文章介绍了BI 1.0-3.0.,其中3.0即基于大数据移动商务智能理论。相关课程:数据库,机器学习,计量经济学,统计学,可视化
T
做了two sum 对unordered_map产生了好奇,所以找了一些资料了解下~
unordered_map介绍:
无序映射是关联容器,用于存储由键值和映射值组合而成的元素,并允许基于键快速检索各个元素。
在unordered_map中,键值通常用于唯一标识元素,而映射值是与该键关联的内容的对象。键和映射值的类型可能不同。
在内部,unordered_map中的元素没有按照它们的键值或映射值的任何顺序排序,而是根据它们的散列值组织成桶以允许通过它们的键值直接快速访问单个元素(具有常数平均时间复杂度)。
unordered_map容器比映射容器更快地通过它们的键来访问各个元素,尽管它们通过其元素的子集进行范围迭代通常效率较低。
无序映射实现直接访问操作符(operator []),该操作符允许使用其键值作为参数直接访问映射值。
容器中的迭代器至少是前向迭代器
unordered_map使用方法:
在c++11以前要使用unordered_map需要
#include
using namespace std::tr1;//与此同时需要加上命名空间
[查找元素是否存在]
若有unordered_map
方法1: 若存在 mp.find(x)!=mp.end()
方法2: 若存在 mp.count(x)!=0
[插入数据]
map.insert(Map::value_type(1,"Raoul"));
[遍历map]
unordered_map
(*it).first; //the key value
(*it).second //the mapped value
for(unordered_map
cout<<"key value is"<
也可以这样
for(auto& v : mp)
print v.first and v.second
map和unordered_map的比较:
[与map的区别]
内部实现机理
map: map内部实现了一个红黑树,该结构具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素,因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行这样的操作,故红黑树的效率决定了map的效率。
unordered_map: unordered_map内部实现了一个哈希表,因此其元素的排列顺序是杂乱的,无序的
map
优点:
有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
红黑树,内部实现一个红黑书使得map的很多操作在的时间复杂度下就可以实现,因此效率非常的高
缺点:
空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点,孩子节点以及红/黑性质,使得每一个节点都占用大量的空间
适用处:
对于那些有顺序要求的问题,用map会更高效一些
T总结
unordered_map
优点:
因为内部实现了哈希表,因此其查找速度非常的快
缺点:
哈希表的建立比较耗费时间
适用处:
对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
S
自觉代码不规范的小白决定第一天从规范自己的代码开始
代码样例