1.python基础的准备
本课程拟采用Python做为机器算法应用的实现语言,所以请确保:
1)安装好Python开发环境, PyCharm 或 Anaconda等都可以,按个人习惯喜好。
2)基本库的安装,如numpy、pandas、scipy、matplotlib
3)具备一定的Python编程技能,如果不熟悉,可选择一个教程进行学习,Python简单好上手,资源也很丰富。
菜鸟教程 Python 3 教程 http://www.runoob.com/python3/python3-tutorial.html
廖雪峰的官方网站 Python3 https://www.liaoxuefeng.com/wiki/1016959663602400
学习视频
2.本周视频学习内容:https://www.bilibili.com/video/BV1Tb411H7uC?p=1
1)P4 Python基础
2)P1 机器学习概论
机器学习是一门多领域交叉学科,涉及较多的数学知识,我们不做太多理论上的要求,如果有听不懂的地方,不要放弃,看一遍就有个印象。通过观看视频,大家对课程有个总体的认识。
建议大家边看边做笔记,记录要点及所在时间点,以便有必要的时候回看。学习笔记也是作业的一部分。
3.作业要求:
1)贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。
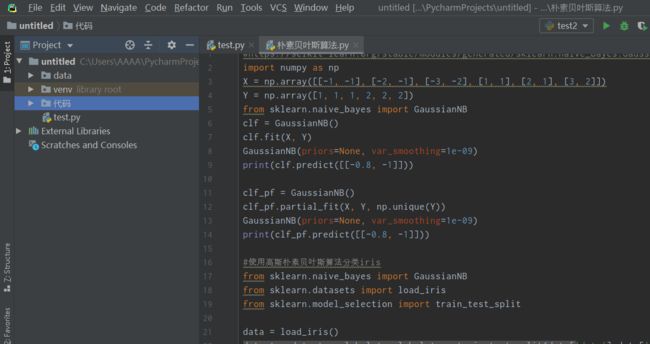
图1 工作环境

图2 数据包(一部分)
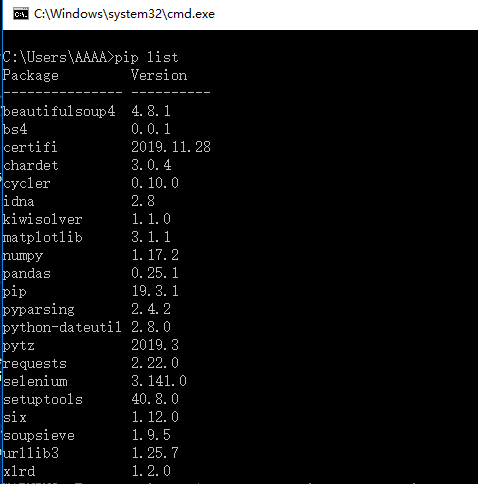
图3 pip list
2)贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。
机器学习概论讲的基本就是函数及概率论的运用,python基础讲的是一些区别和基本的数据结构应用以及绘图等知识。


图4 机器概述主要内容 图5 什么是机器学习

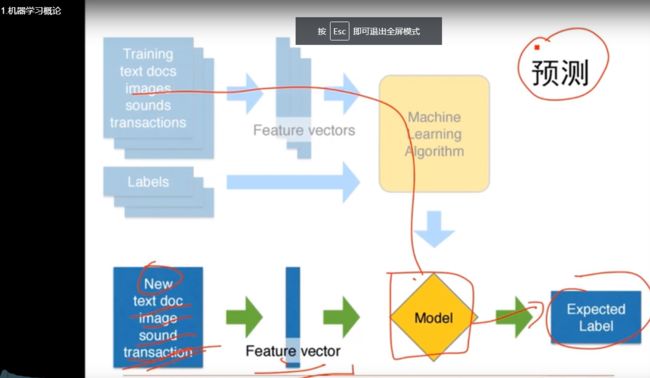
图6 机器学习的内涵与外延 图7 步骤:建模→预测
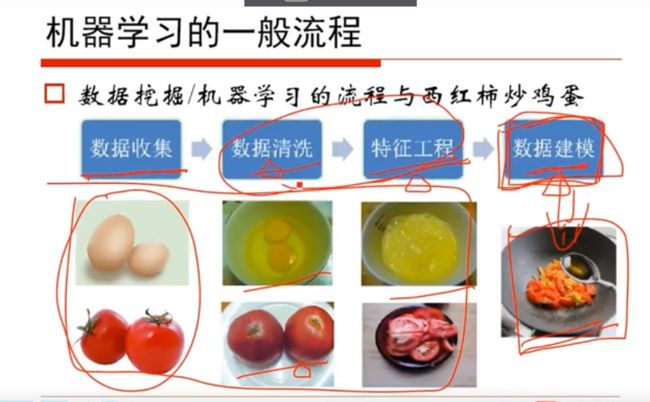

图8 一般流程 图9 凸函数举例

图10 多次提及Taylor展式 图11 numpy与python数学库的时间比较
图12 词云
3)什么是机器学习,有哪些分类?结合案例,写出你的理解。
答:机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径。机器学习有下面几种定义:① 机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。②机器学习是对能通过经验自动改进的计算机算法的研究。③ 机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。传统机器学习的研究方向主要包括决策树、随机森林、人工神经网络、贝叶斯学习等方面的研究。上学期我们初步接触了决策树算法、神经网络算法以及贝叶斯算法,但是还不够深入。
机器学习通常分为四类:监督学习、无监督学习、半监督学习、强化学习。
监督学习:监督学习是从标记的训练数据来推断一个功能的机器学习任务。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。监督学习有两个典型分类:分类(离散的数据),比如邮件过滤就是一个二分类问题,分为正例即正常邮件,负例即垃圾邮件。回归(从连续的数据,进行预测),回归的任务是预测目标数值,比如房屋的价格,给定一组特性(房屋大小、房间数等),来预测房屋的售价。我们上学期学的基本都是监督学习方法。
无监督学习:我们有一些问题,但是不知道答案,我们要做的无监督学习就是按照他们的性质把他们自动地分成很多组,每组的问题是具有类似性质的(比如数学问题会聚集在一组,英语问题会聚集在一组,物理........)所有数据只有特征向量没有标签,但是可以发现这些数据呈现出聚群的结构,本质是一个相似的类型的会聚集在一起。把这些没有标签的数据分成一个一个组合,就是聚类。这一类算法常见的工作有:①降维。降维的目标是简化数据,但是损失尽量少的信息。一个方法是将几个相似的特征或者代表一个属性的几个特征提取成一个特征,也是我们通常说的特征提取。②异常检测。比如说检测信用卡欺诈,我们用正例来训练模型,然后当一个新的实例到来的时候,判断是否像正实例,否则就是负例。③关联规则。可以参照啤酒喝尿布的例子???
半监督学习:半监督学习在训练阶段结合了大量未标记的数据和少量标签数据。与使用所有标签数据的模型相比,使用训练集的训练模型在训练时可以更为准确,而且训练成本更低。在现实任务中,未标记样本多、有标记样本少是一个比价普遍现象,如何利用好未标记样本来提升模型泛化能力,就是半监督学习研究的重点。要利用未标记样本,需假设未标记样本所揭示的数据分布信息与类别标记存在联系。
强化学习:所谓强化学习就是智能系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大。如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势便会加强 -《百科》。简单来说就是给你一只小白鼠在迷宫里面,目的是找到出口,如果他走出了正确的步子,就会给它正反馈(糖),否则给出负反馈(点击),那么,当它走完所有的道路后。无论比把它放到哪儿,它都能通过以往的学习找到通往出口最正确的道路。强化学习的典型案例就是阿尔法狗。