明晚8:30,k3s实战课程开启!将由Rancher研发总监带你畅游k3s与边缘AI的奇妙世界。课程内容完全由实际使用场景中总结而来,别错过啦~!访问以下链接即可传送到课程现场:
http://z-mz.cn/PmxF
作者丨Daniel Weibel
原文链接:
https://learnk8s.io/blog/kubectl-productivity
本文来自Rancher Labs
如果你正在使用Kubernetes,那么kubectl一定是你最常使用的工具。无论你需要学习任何工具,都应该先提前了解kubectl并有效地使用它。本文包含了一系列技巧,可以让你更高效而且有效地使用kubectl。同时,可以加深你对Kubernetes各个方面工作方式的理解。
本文的目标不仅是使你使用Kubernetes的日常工作更高效,而且更愉快!

目 录
-
什么是kubectl?
-
使用命令补全功能保存输入
-
迅速查找资源规范
-
使用自定义列输出格式
-
轻松在集群和命名空间之间切换
-
使用自动生成别名(Aliases)保存输入
-
使用插件扩展kubectl
什么是kubectl
在学习如何更高效地使用kubectl之前,你应该对它是什么以及如何工作有个基本的了解。从用户的角度来说,kubectl是你控制Kubernetes的“驾驶舱”。它可以让你执行所有可能的Kubernetes操作。
从技术角度上看,kubectl是Kubernetes API的客户端。Kubernetes API是一个 HTTP REST API。这个API是真正的Kubernetes用户界面。Kubernetes完全受这个API控制,这意味着每个Kubernetes操作都作为API端点公开,并且可以由对此端点的HTTP请求执行。因此,kubectl的主要工作是执行对Kubernetes API的HTTP请求:
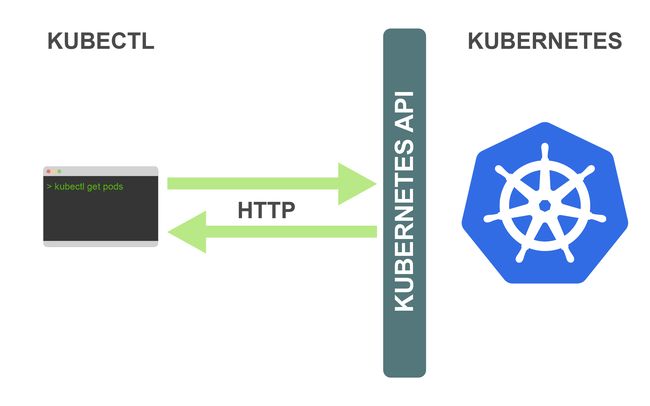
Kubernetes是一个完全以资源为中心的系统。这意味着,Kubernetes维护资源的内部状态并且所有的Kubernetes操作都是针对这些资源的CRUD(增加、读取、更新、删除)操作。你完全可以通过操控这些资源(Kubernetes会根据资源的当前状态找出解决方案)来控制Kubernetes。因此,Kubernetes API reference主要是资源类型及其相关操作的列表。
来,我们来看一个例子。
假设你想要创建一个ReplicaSet资源。为了达成此目标,你在一个名为replicaset.yaml的文件中定义ReplicaSet,然后运行以下命令:
kubectl create -f replicaset.yaml
显然,在Kubernetes已经创建了你的ReplicaSet。但之后会发生什么呢?
Kubernetes有一个创建ReplicaSet的操作,并且它和其他所有Kubernetes操作一样,都会作为API端点暴露。对于这个操作而言,该特定API端点如下:
POST /apis/apps/v1/namespaces/{namespace}/replicasets
你可以在API reference中找到所有Kubernetes操作对应的API端点,包括以上端点(https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.13 )。要向端点发出实际请求,你需要一开始就在API reference中列出的端点路径中添加API server的URL。
因此,当你执行上述命令时,kubectl将向上述API端点发出HTTP POST请求。ReplicaSet定义(你在replicaset.yaml文件中所提供的)在请求的正文中传递。
这就是kubectl对于与Kubernetes集群交互的所有命令的工作方式。在这些情况下,kubectl只需向适当的Kubernetes API端点发出HTTP请求即可。
请注意,通过手动向Kubernetes API发出HTTP请求,完全有可能使用curl之类的工具来控制Kubernetes。Kubectl只是让你更轻松地使用Kubernetes API。
以上就是什么是kubectl及其工作原理的简单介绍。但是,每个kubectl用户都应该了解更多有关Kubernetes API的信息。为此,我们先简要地介绍一下Kubernetes的内部结构。
Kubernetes 内部
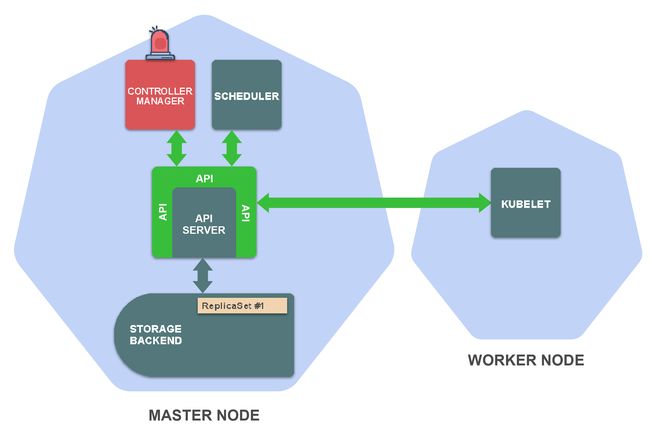
Kubernetes由一系列独立组件构成,这些组件会在集群的节点上作为单独的进程运行。一些组件运行在master节点,一些组件运行在worker节点,每个组件都有其特定功能。
在master节点上,有以下重要组件:
-
存储后端:存储资源定义(通常使用etcd)
-
API Server:提供Kubernetes API并管理存储后端
-
Controller manager:确保资源状态与规范相匹配
-
Scheduler:将Pod调度到worker节点
在worker节点上最重要的组件为:
- Kubelet:在worker节点上管理容器的执行
为了充分了解这些组件是如何一起工作的,让我们来看一个例子。
假设你刚刚执行了kubectl create -f replicaset.yaml,此后,kubectl向_create ReplicaSet API端点_发出了HTTP POST请求(传递你的ReplicaSet资源定义)。哪些因素会导致集群中出现这种情况?如下:

执行kubectl create -f replicaset.yaml之后,API server将会在存储后端保存你的ReplicaSet资源定义。
这将触发controller manager中的ReplicaSet controller,后者监视ReplicaSet资源的创建,更新和删除。
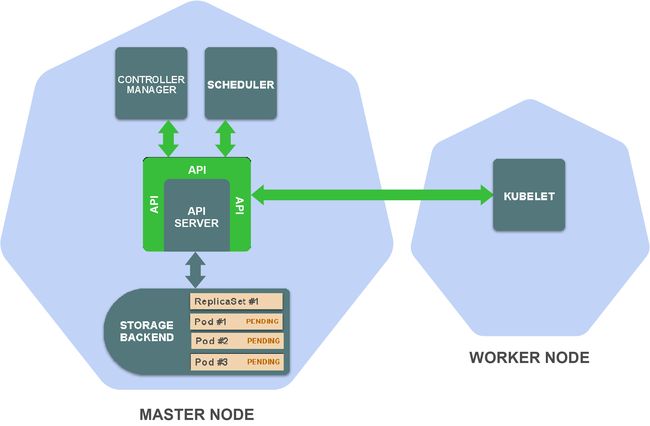
ReplicaSet controller为每个ReplicaSet副本创建了一个Pod定义(根据在ReplicaSet定义中的Pod模板创建)并将它们保存到存储后端。

这触发了scheduler,它监视尚未被分配给worker节点的Pod。
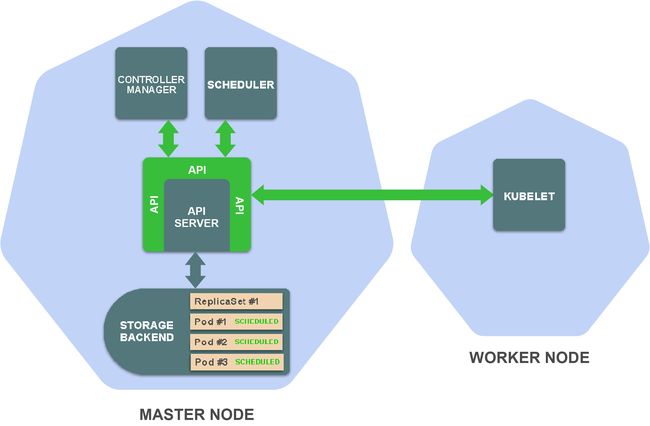
Scheduler为每个Pod选择一个合适的worker节点,并在存储后端中添加该信息到Pod定义中。
请注意,到目前为止,集群中任何地方都没有运行工作负载的代码。至今,我们所完成的事就是在master节点上的存储后端中创建和更新资源。
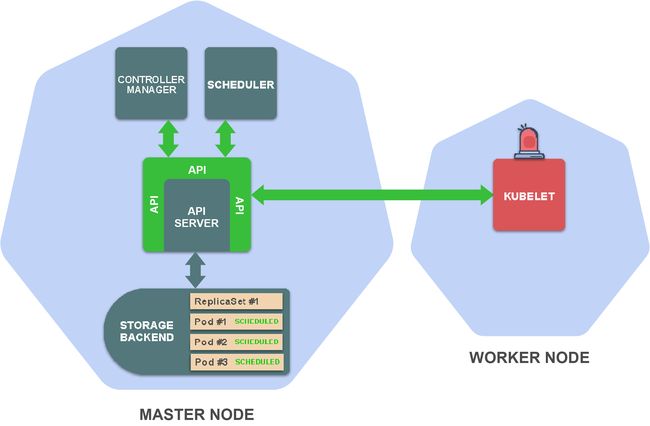
这触发了在Pod所调度到的worker节点上的kubelet,它监视调度到其worker节点上的pod。

Kubelet从存储后端读取Pod定义并指示容器运行时(比如,Docker)来运行在worker节点上的容器。
此时,你的ReplicaSet应用程序已经在运行啦!
Kubernetes API的角色
从上述例子可知,Kubernetes组件(除了API server和存储后端)通过在存储后端监视资源更改和操控资源工作。然而,这些组件无法直接访问存储后端,仅能通过Kubernetes API进行访问。
看一下以下示例:
-
ReplicaSet controller使用带有watch参数_的list ReplicaSets API 端点_API操作来监视ReplicaSet资源的更改。
-
ReplicaSet controller使用_create Pod API 端点_来创建Pod
-
Scheduler使用_patch Pod API端点_以及有关选定的worker节点信息来更新Pod。
正如你所见,这与kubectl所使用的API相同。
Kubernetes API对于内部组件和外部用户的重复操作是Kubernetes的基本设计概念。现在,我们来总结一下Kubernetes如何工作的:
-
存储后端存储(如,资源)Kubernetes的状态
-
API server以Kubernetes API的形式提供到存储后端的接口
-
所有其他Kubernetes的组件和用户通过Kubernetes API读取、监视以及操控Kubernetes的状态(如资源)。
熟悉这些概念将在很大程度上帮助你更好地理解kubectl并利用它。
接下来,我们来看一下具体的技巧,来帮助你提升kubectl的生产力。
1、 使用命令补全功能保存输入
命令补全是提高kubectl生产率的最有用但经常被忽略的技巧之一。
命令补全功能使你可以使用Tab键自动完成kubectl命令的各个部分。这适用于子命令、选项和参数,包括诸如资源名称之类难以键入的内容。
在这里,你可以看到kubectl命令的完成情况:

命令补全可用于Bash和Zsh Shell。
官方文档中包含有关设置命令完成的详细说明(https://kubernetes.io/docs/tasks/tools/install-kubectl/#enabling-shell-autocompletion),但是以下部分会简要向您介绍如何设置。
命令补全功能工作方式
总体而言,命令补全是通过补全脚本而起作用的Shell功能。补全脚本是一个shell脚本,它为特定命令定义了补全行为。通过输入补全脚本可以补全相应的命令。Kubectl可以使用以下命令为Bash和Zsh自动生成并print out补全脚本:
kubectl completion bash
# or
kubectl completion zsh
理论上,在合适的shell(Bash或Zsh)中提供此命令的输出将会启用kubectl的命令补全功能。然而,实际上,在Bash和Zsh之间存在一些细微的差别(包括在Linux和macOS之间也存在差别)。以下部分将对此进行详细解释。
Bash on Linux
Bash的补全脚本主要依赖bash-completion项目(https://github.com/scop/bash-completion),所以你需要先安装它。
你可以使用不同的软件包管理器安装bash-completion。如:
sudo apt-get install bash-completion
# or
yum install bash-completion
你可以使用以下命令测试bash-completion是否正确安装:
type \_init\_completion
如果输出的是shell功能的代码,那么bash-completion就已经正确安装了。如果命令输出的是not found错误,你必须添加以下命令行到你的~/.bashrc文件:
source /usr/share/bash-completion/bash_completion
你是否需要添加这一行到你的~/.bashrc文件中,取决于你用于安装bash-completion的软件包管理器。对于APT来说,这是必要的,对于yum则不是。
bash-completion安装完成之后,你需要进行一些设置,以便在所有的shell会话中获得kubectl补全脚本。一种方法是将以下命令行添加到~/.bashrc文件中:
source <(kubectl completion bash)
另一种可能性是将kubectl补充脚本添加到/etc/bash_completion.d目录中(如果不存在,则需要先创建它):
kubectl completion bash >/etc/bash_completion.d/kubectl
/etc/bash_completion.d目录中的所有补全脚本均由bash-completion自动提供。
以上两种方法都是一样的效果。重新加载shell后,kubectl命令补全就能正常工作啦!
Bash on macOS
使用macOS时,会有些复杂。原因是截至成文时macOS上Bash的默认版本是3.2,这已经过时了。不幸的是,kubectl补全脚本至少需要Bash 4.1,因此不适用于Bash 3.2。
苹果依旧在macOS上默认使用过时的Bash版本是因为更新版本的Bash使用的是GPLv3 license,而苹果不支持这一license。
这意味着,要在macOS上使用kubectl命令补全功能,你必须安装较新版本的Bash。你甚至可以将其设置为新的默认shell,这将在将来为你省去很多此类麻烦。这实际上并不难,你可以在我之前写的文章中找到说明:
https://itnext.io/upgrading-bash-on-macos-7138bd1066ba
在继续剩下的步骤之前,确保你现在已经在使用Bash 4.1或更高的版本(使用bash --version查看版本)。
同上一部分一样,Bash的补全脚本主要依赖bash-completion项目(https://github.com/scop/bash-completion ),所以你需要先安装它。
你可以使用Homebrew安装bash-completion:
brew install bash-completion@2
@2代表bash-completion v2。Kubectl补全脚本要求bash-completion v2,而bash-completion v2要求至少是Bash 4.1。这就是你不能在低于4.1的Bash版本上使用kubectl补全脚本的原因。
brew intall命令的输出包括一个“Caveats”部分,其中的说明将以下行添加~/.bash_profile文件:
export BASH\_COMPLETION\_COMPAT_DIR=/usr/local/etc/bash_completion.d
[[ -r "/usr/local/etc/profile.d/bash_completion.sh" ]] && . "/usr/local/etc/profile.d/bash_completion.sh"
你必须执行此操作才能完成bash-completion的安装。但是,我建议将这些行添加到~/.bashrc而不是~/.bash_profile文件中。这可以确保bash-completion在子shell中也可用。
重新加载shell之后,你可以使用以下命令测试bash-completion是否正确安装:
type \_init\_completion
如果输出为shell功能的代码,意味着一切都设置完成。现在,你需要进行一些设置,以便在所有的shell会话中获得kubectl补全脚本。一种方法是将以下命令行添加到~/.bashrc文件中:
source <(kubectl completion bash)
另一种方法是将kubectl补全脚本添加到/usr/local/etc/bash_completion.d目录中:
kubectl completion bash >/usr/local/etc/bash_completion.d/kubectl
仅当你使用Homebrew安装了bash-completion时,此方法才有效。在这种情况下,bash-completion会在此目录中提供所有补全脚本。
如果你还用Homebrew安装了kubectl,则甚至不必执行上述步骤,因为补全脚本应该已经由kubectl Homebrew公式放置在/usr/local/etc/bash_completion.d目录中。在这种情况下,kubectl补全应该在安装bash-completion后自动开始工作。所有方法都是效果都是一致的。
重新加载shell后,kubectl完成就能正常工作!
Zsh
Zsh的补全脚本没有任何依赖项。所以,你所需要做的是去进行一些设置,以便它能在所有的shell会话中被获取到。
你可以通过添加以下命令行到你的~/.zshrc文件中来实现这一效果:
source <(kubectl completion zsh)
如果在重新加载你的shell之后,你获得了command not found: compdef错误,你需要启动内置的compdef,你可以在将以下行添加到开始的~/.zshrc文件中:
autoload -Uz compinit
compinit
2、迅速查看资源规范
当你创建YAML资源定义时,你需要知道字段以及这些资源的意义。API reference中提供了一个查找此类信息的位置,其中包含所有资源的完整规范:
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.13/
然而,每次你需要查找某些内容时都要切换到Web浏览器,这十分繁琐。因此,kubectl提供了kubectl explain命令,它能在你的terminal中正确地输入所有资源规范。
kubectl explain的用法如下:
kubectl explain resource\[.field\]...
该命令输出所请求资源或字段的规范。kubectl explain所显示的信息与API reference中的信息相同。默认情况下,kubectl explain仅显示单个级别的字段。你可以使用--recursive标志来显示所有级别的字段:
kubectl explain deployment.spec --recursive
如果你不确定哪个资源名称可以用于kubectl explain,你可以使用以下命令查看:
kubectl api-resources
该命令以复数形式显示资源名称(如deployments)。它同时显示资源名称的缩写(如deploy)。无需担心这些差别,所有名称变体对于kubectl都是等效的。也就是说,你可以使用它们中的任何一个。
例如,以下命令效果都是一样的:
kubectl explain deployments.spec
# or
kubectl explain deployment.spec
# or
kubectl explain deploy.spec
3、 使用自定义列输出格式
kubectl get命令默认的输出方式如下(该命令用于读取资源):
kubectl get pods
NAME READY STATUS RESTARTS AGE
engine-544b6b6467-22qr6 1/1 Running 0 78d
engine-544b6b6467-lw5t8 1/1 Running 0 78d
engine-544b6b6467-tvgmg 1/1 Running 0 78d
web-ui-6db964458-8pdw4 1/1 Running 0 78d
这是一种很好的可读格式,但是它仅包含有限的信息量。如你所见,每个资源仅显示了一些字段,而不是完整的资源定义。此时,自定义列输出格式应运而生,它使你可以自由定义列和想在其中显示的数据。你可以选择资源的任何字段,使其在输出中显示为单独的列。
自定义列输出选项的用法如下:
-o custom-columns=:\[,:\]...
你必须将每个输出列定义为
-
-
让我们看一个简单的例子:
kubectl get pods -o custom-columns='NAME:metadata.name'
NAME
engine-544b6b6467-22qr6
engine-544b6b6467-lw5t8
engine-544b6b6467-tvgmg
web-ui-6db964458-8pdw4
在这里,输出包括显示所有Pod名称的一列。
选择Pod名称的表达式是meta.name。原因是Pod的名称是在Pod资源的元数据字段的name字段中定义的(你可以在API reference中或使用kubectl explain pod.metadata.name进行查找)。
现在,假设你想在输出中添加一个附加列,例如,显示每个Pod在其上运行的节点。为此,你只需在自定义列选项中添加适当的列规范即可:
kubectl get pods \
-o custom-columns='NAME:metadata.name,NODE:spec.nodeName'
NAME NODE
engine-544b6b6467-22qr6 ip-10-0-80-67.ec2.internal
engine-544b6b6467-lw5t8 ip-10-0-36-80.ec2.internal
engine-544b6b6467-tvgmg ip-10-0-118-34.ec2.internal
web-ui-6db964458-8pdw4 ip-10-0-118-34.ec2.internal
选择节点名称的表达式是spec.nodeName。这是因为已将Pod调度的节点保存在Pod的spec.nodeName字段中(请参阅kubectl explain pod.spec.nodeName)。
请注意,Kubernetes资源字段区分大小写。
你可以通过这种方式将资源的任何字段设置为输出列。只需浏览资源规范并尝试使用任何你喜欢的字段即可!
但是首先,让我们仔细看看这些字段选择表达式。
JSONPath 表达式
用于选择资源字段的表达式基于JSONPath:
https://goessner.net/articles/JsonPath/index.html
JSONPath是一种用于从JSON文档提取数据的语言(类似于XPath for XML)。选择单个字段只是JSONPath的最基本用法。它具有很多功能,例如list selector、filter等。
但是,kubectl explain,仅支持JSONPath功能的子集。以下通过示例用法总结了这些得到支持的功能:
# Select all elements of a list
kubectl get pods -o custom-columns='DATA:spec.containers[*].image'
# Select a specific element of a list
kubectl get pods -o custom-columns='DATA:spec.containers[0].image'
# Select those elements of a list that match a filter expression
kubectl get pods -o custom-columns='DATA:spec.containers[?(@.image!="nginx")].image'
# Select all fields under a specific location, regardless of their name
kubectl get pods -o custom-columns='DATA:metadata.*'
# Select all fields with a specific name, regardless of their location
kubectl get pods -o custom-columns='DATA:..image'
特别重要的是[ ]运算符。Kubernetes资源的许多字段都是列表,使用此运算符可以选择这些列表中的项目。它通常与通配符一起用作[*],以选择列表中的所有项目。
在下面,你将找到一些使用此符号的示例。
示例应用程序
使用自定义列输出格式有无限可能,因为你可以在输出中显示资源的任何字段或字段组合。以下是一些示例应用程序,但你可以自己探索并找到对你有用的应用程序。
Tip:如果你经常使用这些命令,则可以为其创建一个shell别名。
显示Pod的容器镜像
kubectl get pods \
-o custom-columns='NAME:metadata.name,IMAGES:spec.containers[*].image'
NAME IMAGES
engine-544b6b6467-22qr6 rabbitmq:3.7.8-management,nginx
engine-544b6b6467-lw5t8 rabbitmq:3.7.8-management,nginx
engine-544b6b6467-tvgmg rabbitmq:3.7.8-management,nginx
web-ui-6db964458-8pdw4 wordpress
此命令显示每个Pod的所有容器镜像的名称。
请记住,一个Pod可能包含多个容器。在这种情况下,单个Pod的容器镜像在同一列中显示为由逗号分隔的列表。
显示节点的可用区
kubectl get nodes \
-o custom-columns='NAME:metadata.name,ZONE:metadata.labels.failure-domain\.beta\.kubernetes\.io/zone'
NAME ZONE
ip-10-0-118-34.ec2.internal us-east-1b
ip-10-0-36-80.ec2.internal us-east-1a
ip-10-0-80-67.ec2.internal us-east-1b
如果您的Kubernetes集群部署在公有云基础架构(例如AWS,Azure或GCP)上,则此命令很有用。它显示每个节点所在的可用区。
可用区是一个公有云的概念,表示一个地理区域内的复制点。
每个节点的可用区均通过特殊的failure-domain.beta.kubernetes.io/zone 标签获得。如果集群在公有云基础架构上运行,则将自动创建此标签,并将其值设置为节点的可用性区域的名称。
标签不是Kubernetes资源规范的一部分,因此您无法在API reference中找到以上标签。但是,如果将节点输出为YAML或JSON,则可以看到它(以及所有其他标签):
kubectl get nodes -o yaml
# or
kubectl get nodes -o json
除了探索资源规范外,这通常是发现更多有关资源的信息的好方法。
4、轻松在集群和命名空间之间切换
当kubectl必须向Kubernetes API发出请求时,它将读取系统上的所谓kubeconfig文件,以获取它需要访问的所有连接参数并向API服务器发出请求。
默认的kubeconfig文件是〜/ .kube / config。该文件通常是通过某些命令自动创建或更新的(例如,如果使用托管的Kubernetes服务,则为aws eks update-kubeconfig或gcloud container clusters get-credentials)。
使用多个集群时,在kubeconfig文件中配置了多个集群的连接参数。这意味着,你需要一种方法来告诉kubectl要将其连接到哪些集群中。
在集群中,您可以设置多个命名空间(命名空间是物理集群中的一种“虚拟”集群)。Kubectl还可确定kubeconfig文件中用于请求的命名空间。因此,你需要一种方法来告诉kubectl你要使用哪个命名空间。
请注意,您还可以通过在KUBECONFIG环境变量中列出它们,以拥有多个kubeconfig文件。在这种情况下,所有这些文件将在执行时合并为一个有效的配置。你还可以为每个kubectl命令使用--kubeconfig选项覆盖默认的kubeconfig文件。具体请参阅官方文档:
https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig/
Kubeconfig文件
让我们看看kubeconfig文件实际包含什么:
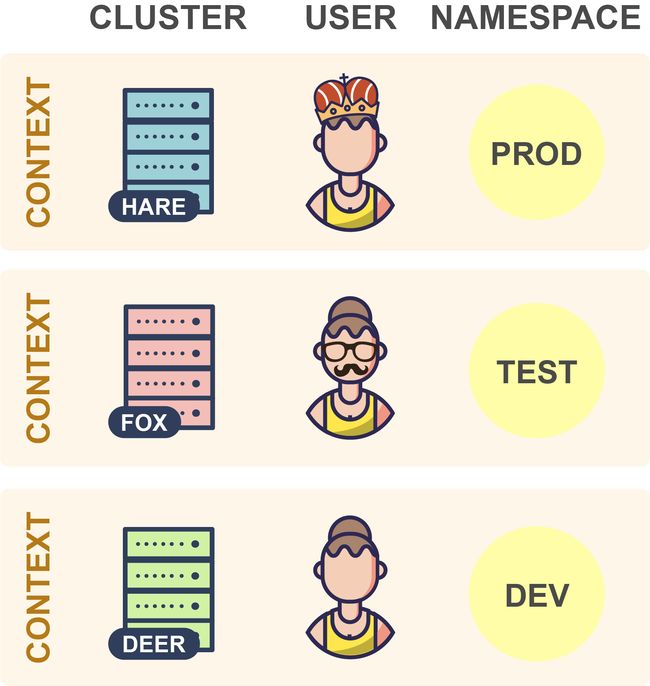
如你所见,kubeconfig文件由一组上下文组成。上下文包含以下三个元素:
-
集群:集群的API server的URL
-
用户:集群中特定用户的身份验证凭据
-
命名空间:连接到集群时要使用的命名空间
实际上,人们通常在其kubeconfig文件中为每个集群使用单个上下文。但是,每个集群也可以有多个上下文,它们的用户或命名空间不同。但这似乎不太常见,因此集群和上下文之间通常存在一对一的映射。
在任何给定时间中,这些上下文其中之一都可以被设置为当前上下文(通过kubeconfig文件中的专用字段):
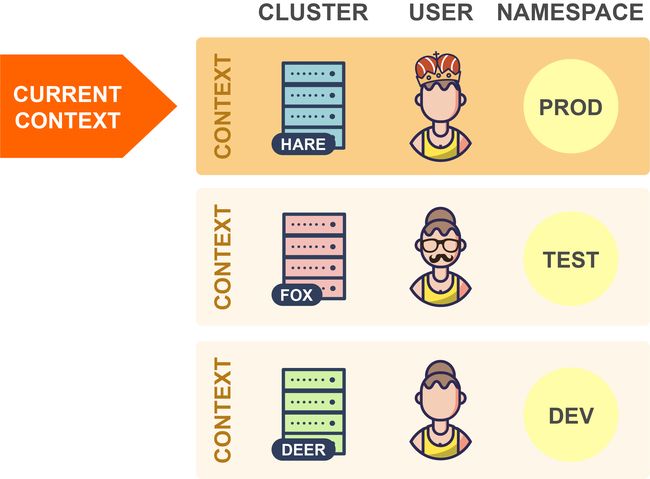
当kubectl读取kubeconfig文件时,它总是使用当前上下文中的信息。因此,在上面的示例中,kubectl将连接到Hare集群。
因此,要切换到另一个集群时,你只需在kubeconfig文件中更改当前上下文即可:
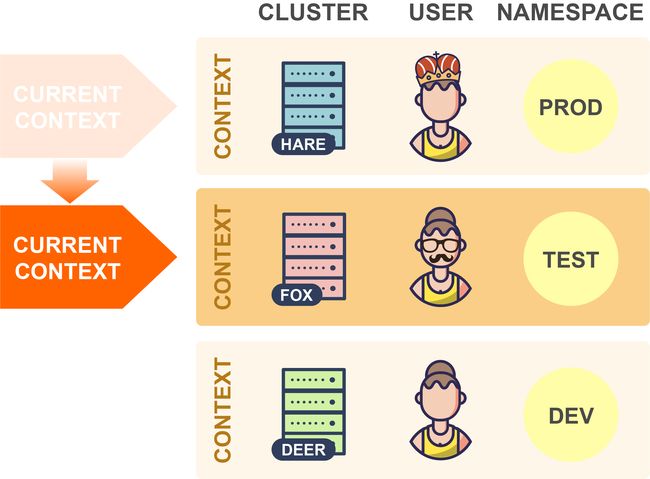
在上面的示例中,kubectl现在将连接到Fox集群。
并切换到同一集群中的另一个命名空间,可以更改当前上下文的命名空间元素的值:
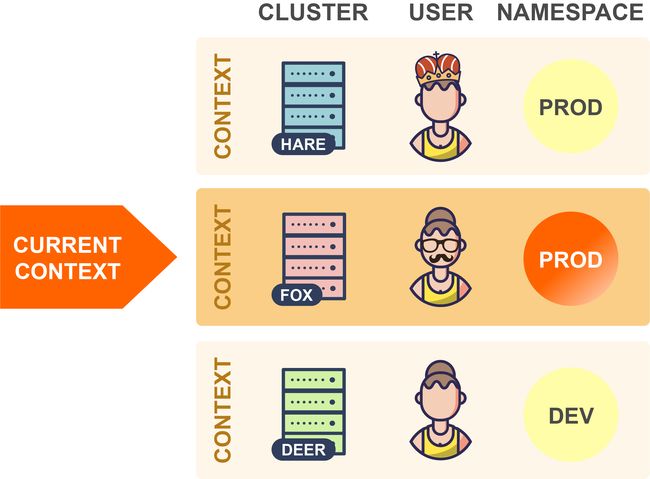
在上面的示例中,kubectl现在将在Fox集群中使用Prod命名空间(而不是之前设置的Test命名空间)。
请注意,kubectl还提供了—cluster、-user、-namespace和--context选项,无论kubeconfig文件中设置了什么,它们都可以覆盖单个元素和当前上下文本身。请参阅kubectl options
从理论上讲,你可以通过手动编辑kubeconfig文件来进行这些更改。但是,这十分繁琐。以下各节介绍了各种工具,可让你自动进行这些更改。
Kubectx
Kubectx可以有效帮助集群和命名空间之间进行切换。该工具提供了kubectx和kubens命令,使你可以分别更改当前上下文和命名空间。
如前所述,如果每个集群只有一个上下文,则更改当前上下文意味着更改集群。
在这里,你可以看到这两个命令的作用:

如上一节所述,这些命令仅需在后台编辑kubeconfig文件即可。
要安装kubectx,只需按照GitHub页面上的说明进行操作即可:
https://github.com/ahmetb/kubectx/#installation
kubectx和kubens都通过补全脚本提供命令补全功能。这使你可以自动完成上下文名称和命名空间的输入。你也可以在GitHub页面上找到设置完成的说明:
https://github.com/ahmetb/kubectx/#installation
kubectx的另一个十分有用的功能是交互模式。这与fzf工具(它必须单独安装)一起工作(实际上,安装fzf会自动启用kubectx交互模式)。交互式模式允许你通过交互式模糊搜索界面(由fzf提供)选择目标上下文或命名空间。
fzf Github主页:https://github.com/junegunn/fzf
使用shell别名
实际上,你并不需要单独的工具来更改当前上下文和命名空间,因为kubectl也提供了执行此操作的命令。特别是,kubectl config命令提供了用于编辑kubeconfig文件的子命令。这里是其中的一些:
-
kubectl config get-contexts:列出所有上下文 -
kubectl config current-context:获取当前上下文 -
kubectl config use-context:更改当前上下文 -
kubectl config set-context:更改上下文的元素
但是,直接使用这些命令不是很方便,因为它们的键入时间很长。但是你可以做的是将它们包装到可以更容易执行的shell别名中。
我根据这些命令创建了一组别名,这些别名提供了与kubectx类似的功能。在这里,你可以看到它们的作用:

请注意,别名使用fzf提供的交互式模糊搜索界面(例如kubectx的交互式模式)。这意味着,你需要安装fzf才能使用这些别名。
以下是别名的定义:
# Get current context
alias krc='kubectl config current-context'
# List all contexts
alias klc='kubectl config get-contexts -o name | sed "s/^/ /;\\|^ $(krc)$|s/ /*/"'
# Change current context
alias kcc='kubectl config use-context "$(klc | fzf -e | sed "s/^..//")"'
# Get current namespace
alias krn='kubectl config get-contexts --no-headers "$(krc)" | awk "{print \$5}" | sed "s/^$/default/"'
# List all namespaces
alias kln='kubectl get -o name ns | sed "s|^.*/| |;\\|^ $(krn)$|s/ /*/"'
# Change current namespace
alias kcn='kubectl config set-context --current --namespace "$(kln | fzf -e | sed "s/^..//")"'
要安装这些别名,只需将以上定义添加到〜/ .bashrc或〜/ .zshrc文件中,然后重新加载你的shell。
使用插件
Kubectl允许安装可以像原生命令一样调用的插件。例如,你可以安装名为kubectl-foo的插件,然后将其作为kubectl foo调用。kubectl插件将在本文后面的部分中详细介绍。
能够像这样更改当前上下文和命名空间不是很好吗?例如,运行kubectl ctx更改上下文,运行kubectl ns更改命名空间?
我创建了两个可以实现这一功能的插件:
-
kubectl-ctx:https://github.com/weibeld/kubectl-ctx
-
kubectl-ns:https://github.com/weibeld/kubectl-ns
在内部,插件建立在上一部分的别名基础上。
在这里,你可以看到正在使用的插件:

请注意,插件使用fzf提供的交互式模糊搜索界面。这意味着,您需要安装fzf才能使用这些插件。
要安装插件,只需将名为kubectl-ctx和kubectl-ns的shell脚本下载到PATH中的任何目录,并使它们可执行(例如,使用chmod + x)。之后,你应该立即可以使用kubectl ctx和kubectl ns。
5、 使用自动生成的别名保存输入
Shell别名通常是保存输入内容的好方法。kubectl-aliases项目则是这一想法的具体体现,并为常见的kubectl命令提供了约800个别名:
https://github.com/ahmetb/kubectl-aliases
你可能想知道如何记住800个别名?实际上,你不需要记住它们,因为它们都是根据简单的方案生成的,如下所示:


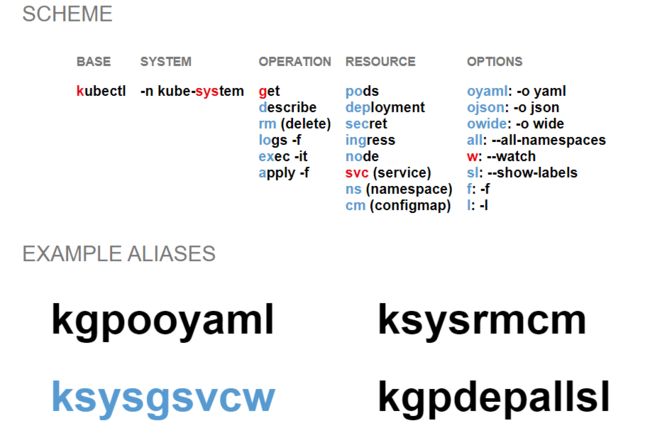

如你所见,别名由组件组成,每个组件代表kubectl命令的特定元素。每个别名可以具有一个用于基本命令、操作和资源的组件,以及一个用于选项的多个组件,你只需按照上述方案从左到右“填充”这些组件即可。
请注意,当前详细的方案位于GitHub页面上:
https://github.com/ahmetb/kubectl-aliases/blob/master/.kubectl_aliases
在这里您还可以找到别名的完整列表:
https://github.com/ahmetb/kubectl-aliases#syntax-explanation
例如,别名kgpooyamlall代表命令kubectl get pods -o yaml --all-namespaces:
-
k→ kubectl
-
g→ get
-
po→ pods
-
oyaml→ -o yaml
-
all→ --all-namespaces
请注意,大多数选项组件的相对顺序无关紧要。因此,kgpooyamlall等同于kgpoalloyaml。
你不需要使用所有组件作为别名。例如,k、kg、klo、ksys或kgpo也是有效的别名。此外,你可以在命令行上将别名与其他单词组合在一起。
例如,你可以使用k proxy来运行kubectl proxy。或使用kg roles来运行kubectl get roles(当前不存在Roles资源的别名组件)。要获得特定的Pod,你可以使用kgpo my-pod来运行kubectl get pod my-pod。
请注意,某些别名甚至需要在命令行上进一步输入参数。例如,kgpol别名代表kubectl get pods -l。-l选项需要一个参数(标签规范)。因此,你必须使用此别名,例如:

因此,你只能在别名末尾使用a,f和l组件。
总而言之,一旦掌握了该方案,就可以从要执行的命令中直观地推断出别名,并节省大量输入!
安装
要安装kubectl-aliases,只需从GitHub下载.kubectl-aliases文件,然后将其从〜/ .bashrc或〜/ .zshrc文件中获取即可:
source ~/.kubectl_aliases
重新加载shell后,你应该可以使用所有800个kubectl别名!
补全功能
如你所见,你经常在命令行上将其他单词附加到别名上。例如:
kgpooyaml test-pod-d4b77b989
如果使用kubectl命令补全功能,则可能习惯于自动完成资源名称之类的事情。但是当你使用别名时仍然可以这样做吗?
这是一个重要的问题,因为如果补全功能无法正常工作,这些别名的某些好处将会被削弱。
那么,这一问题的答案取决于你所使用的shell。
对于Zsh,补全可以立即和别名一起使用。
对于Bash,默认情况下补全功能将不会正常工作。但是它可以通过一些额外的步骤来使其正常运行。
在Bash中同时启用别名和补全功能
Bash的问题在于,它会在别名名称上(而不是在别名命令上)尝试补全(无论何时按Tab键)。由于你没有所有800个别名的补全脚本,因此无法使用。
complete-alias项目提供了解决此问题的通用方法(https://github.com/cykerway/complete-alias )。它利用别名的补全机制,在内部将别名扩展为别名命令,并返回扩展命令的补全建议。这意味着,别名的补全行为与别名命令的行为完全相同。
在下面的内容中,我将首先说明如何安装complete-alias,然后如何配置它以启用所有kubectl别名的补全。
安装complete-alias
首先,complete-alias依赖于bash-completion。因此,在安装complete-alias之前,你需要确保已安装bash-completion。前面已经针对Linux和macOS给出了相关说明。
对于macOS用户的重要说明:与kubectl补全脚本一样,complete-alias不适用于Bash 3.2,后者是macOS上Bash的默认版本。特别是,complete-alias依赖于bash-completion v2(brew install bash-completion@2),至少需要Bash 4.1。这意味着,要在macOS上使用complete-alias,您需要安装较新版本的Bash。
要安装complete-alias,你只需要从GitHub存储库(https://github.com/cykerway/complete-alias )下载bash_completion.sh脚本,并将其source到你的〜/ .bashrc文件中:
source ~/bash_completion.sh
重新加载你的shell之后,complete-alias将完成安装。
为kubectl别名启用补全功能
从技术上讲,complete-alias提供了_complete_alias shell函数。此函数检查别名,并返回别名命令的补全建议。
要将其与特定别名联系起来,你必须使用完整的Bash内置函数将_complete_alias设置为别名的补全功能。
例如,让我们使用k别名代表kubectl命令。要将_complete_alias设置为该别名的补全功能,你必须执行以下命令:
complete -F _complete_alias k
这样的效果是,每当你对k别名自动补全时,就会调用_complete_alias函数,该函数将检查别名并返回kubectl命令的补全建议。
再举一个例子,让我们使用代表kubectl get的kg别名:
complete -F _complete_alias kg
同样,这样做的效果是,当你对kg自动补全时,你将获得与kubectl get相同的补全建议。
请注意,可以通过这种方式对系统上的任何别名使用complete-alias。
因此,要为所有kubectl别名启用补全功能,只需为每个别名运行以上命令。如下所示(假设你将kubectl-aliases安装到〜/ .kubectl-aliases):
for _a in $(sed '/^alias /!d;s/^alias //;s/=.*$//' ~/.kubectl_aliases); do complete -F _complete_alias "$_a"
done
只需将此片段添加到你的〜/ .bashrc文件中,重新加载你的shell,现在你就可以对800个kubectl别名使用补全功能了!
6、使用插件扩展kubectl
从1.12版开始,kubectl包含插件机制,可让你使用自定义命令扩展kubectl。
这是一个可以作为kubectl hello调用的kubectl插件的示例:

如果你对此十分熟悉,其实kubectl插件机制与Git插件机制的设计十分相近。
本节将向您展示如何安装插件,你可以在其中找到现有插件以及如何创建自己的插件。
安装插件
Kubectl插件作为简单的可执行文件分发,名称形式为kubectl-x。前缀kubectl-是必填项,其后是允许调用插件的新的kubectl子命令。
例如,上面显示的hello插件将作为名为kubectl-hello的文件分发。
要安装插件,你只需要将kubectl-x文件复制到PATH中的任何目录并使其可执行(例如,使用chmod + x)。之后,你可以立即使用kubectl x调用插件。
你可以使用以下命令列出系统上当前安装的所有插件:
kubectl plugin list
如果你有多个具有相同名称的插件,或者存在无法执行的插件文件,此命令还会显示警告。
使用krew查找和安装插件
Kubectl插件使自己像软件包一样可以共享和重用。但是在哪里可以找到其他人共享的插件?
krew项目旨在为共享、查找、安装和管理kubectl插件提供统一的解决方案(https://github.com/GoogleContainerTools/krew )。该项目将自己称为“ kubectl插件的软件包管理器”(krew与brew十分相似)。
Krew根据kubectl插件进行索引,你可以从中选择和安装。在这里,你可以看到实际操作:
如你所见,krew本身就是一个kubectl插件。这意味着,安装krew本质上就像安装其他任何kubectl插件一样。你可以在GitHub页面上找到krew的详细安装说明:
https://github.com/GoogleContainerTools/krew/#installation
最重要的krew命令如下:
# Search the krew index (with an optional search query)
kubectl krew search []
# Display information about a plugin
kubectl krew info
# Install a plugin
kubectl krew install
# Upgrade all plugins to the newest versions
kubectl krew upgrade
# List all plugins that have been installed with krew
kubectl krew list
# Uninstall a plugin
kubectl krew remove
请注意,使用krew安装插件不会阻止你继续使用传统方式安装插件。即使你使用krew,你仍然可以通过其他方式安装在其他地方找到的插件(或创建自己的插件)。
此外,kubectl krew list命令仅列出已与krew一起安装的插件,而kubectl plugin list命令列出了所有插件,即,与krew一起安装的插件和以其他方式安装的插件。
在其他地方寻找插件
Krew仍然是一个年轻的项目,目前krew索引中只有大约30个插件。如果找不到所需的内容,则可以在其他地方(例如,在GitHub上)查找插件。
我建议你查看kubectl-plugins GitHub主题。你会在这里找到几十个可用的插件:
https://github.com/topics/kubectl-plugins
创建自己的插件
当然,你也可以创建自己的kubectl插件,这并不困难。
你只需要创建一个执行所需操作的可执行文件,将其命名为kubectl-x,然后按照如上所述的方式安装即可。
可执行文件可以是任何类型,可以是Bash脚本、已编译的Go程序、Python脚本,这些类型实际上并不重要。唯一的要求是它可以由操作系统直接执行。
让我们现在创建一个示例插件。在上一节中,你使用了kubectl命令列出每个Pod的容器镜像。你可以轻松地将此命令转换为可以使用kubectl img调用的插件。
为此,只需创建一个名为kubectl-img的文件,其内容如下:
#!/bin/bash kubectl get pods -o custom-columns='NAME:metadata.name,IMAGES:spec.containers\[*\].image'
现在,使用chmod + x kubectl-img使该文件可执行,并将其移动到PATH中的任何目录。之后,你可以立即将插件与kubectl img一起使用!
如前所述,kubectl插件可以用任何编程或脚本语言编写。如果使用Shell脚本,则具有可以轻松从插件调用kubectl的优势。但是,你可以使用真实的编程语言编写更复杂的插件,例如,使用Kubernetes客户端库。如果使用Go,还可以使用cli-runtime库,该库专门用于编写kubectl插件。
共享你的插件
如果你认为其中一个插件可能对其他人有用,欢迎在GitHub上共享。只需将其添加到kubectl-plugins主题,其他人就可以方便地找到它。
你还可以将插件添加到krew索引。你可以在krew GitHub存储库中找到有关如何执行此操作的说明。
命令补全功能
遗憾的是,目前插件机制尚不支持命令补全。这意味着你需要完整键入插件名称以及插件的所有参数。但是,kubectl GitHub存储库中对此有一个开放功能请求。因此,将来有可能实现此功能。