本文始发于个人公众号:TechFlow,原创不易,求个关注
在之前Python系列当中,我们介绍了heapq这个库的用法,它可以在\(O(nlogn)\)的时间里筛选出前K大或者前K小的元素。今天我们一起来看一个可以更快实现选择的快速选择算法。
思维推导
在公布答案之前,我想先带着大家试着推导一下解法。这其实才是算法能力的精髓,即是应用已知能力解决未知问题的能力。我们学的各种各样的算法都可以看成是已知能力,已知能力越多,说明能力的边界越广,也就意味着理论上可以解决的问题也就越多。相比已知能力,解决问题的能力同样重要,尤其是当我们有了一定的基础之后,这一点甚至更加重要。因为有了这项能力,在一些极端情况下我们甚至可以自己推导出新算法,也即是开创和创新。
假设当下我们并不知道正确的解法是什么,我们想要尽可能快地找到前K大的元素。如果一个一个找这个过程会很慢,除非我们可以做到\(O(1)\)的查找。显然这是不可能的,因为即使是平衡树这类快速查找的数据结构,单词查找也需要\(O(logn)\)。所以一个一个找是不行的。那么就只剩下一批一批找,批量查找又有两种,一种是直接查找K个,还有一种是多次查找,最后得到正解。
我们并不知道哪种方法更靠谱,但是第一种看起来不太可行,因为它就是问题本身,第二种方法看起来稍微可行一些。在这个问题下,我们并没有多余的信息,想要直接查找K个元素应该不太容易。所以可能通过多次查找得到解是比较好的方法。多次查找也可以简单分为两种情况,一种是每次查找一批,最后合并在一起,还有一种是每次缩小查找的范围,最后锁定答案。
到这里,如果你对分治算法熟悉的话,你会觉得它和分治算法的应用场景很相似。我们想要求解一个比较大的问题,但是直接求解很困难,所以我们将它拆解,将大问题拆解成小问题,通过对小问题的解决来搞定原本的大问题。
我们目前比较熟悉的分治算法好像只有归并排序和快速排序这两个,我们可以试着把这两个算法往这个问题上套。归并排序核心思路是每次将数组一分为二,然后通过这两个数组归并的过程找到我们想要的解法。这个方案可行,但是和排序并没有区别。我们文章开头就已经说过了,我们想要寻找的是比排序更快的算法。再看快排,它每次是设置一个标杆,然后对数组当中的元素进行调整,保证比标杆小的元素都在它的左边,比它大的都在它的右边。标杆最后在的位置就是数据有序之后它正确的位置。这个方法好像和我们想要的很接近。
于是,我们就这样顺藤摸瓜,找到了正确的方法。当然实际的思考过程可能要比这个复杂,考虑的情况也会更多,但是总体的思维推导过程应该是差不多的。同样是解题,新手往往靠灵光一闪,而高手都是有一个完整的思维链。很多算法问题看起来一头雾水,但其实是有迹可循的。训练出一个思维模型来寻找正确的解法是新手通往高手的必经之路,也是算法能力的核心。
算法原理
我们来仔细分析一下,一次快速排序的调整之后,我们可以确定标杆的位置,这样一来就有三种情况。第一种,它所在的位置刚好是K,说明它前面的这一段数组就是答案,直接返回即可。如果它小于K,说明这个标杆取小了,我们应该在它右侧的数组当中重新选择一个标杆。如果它大于K说明这个标杆取大了,我们可以直接忽略它右侧的元素,因为它右侧的元素一定不在答案里。
我们可以参考一下下面这张图:

思路有了,代码就不难写了:
def quick_select_without_optimizer(arr, k):
n = len(arr)
# 如果k大于n,没啥好说的,直接返回
if k >= n:
return arr
# 缓存
buffer = []
while arr:
# 选择最后一个元素作为标杆
mark = arr.pop()
less, greater = [], []
# 遍历数组,将元素分为less和greater
for x in arr:
if x <= mark:
less.append(x)
else:
greater.append(x)
# 判断三种情况,如果相等直接返回
if len(less) == k:
return less
# 如果小于,将less存入buffer,因为它一定是答案的一部分,可以简化计算
elif len(less) < k:
buffer += less
# k要减去less的长度
k -= len(less)
arr = [mark] + greater
else:
# 如果大于,直接舍弃右边
arr = less
复杂度分析
写完了代码,我们来分析一下算法的复杂度。有些同学可能会有些疑惑,这个算法和快排基本上一样,为什么会更快呢?
这是因为我们每次迭代的过程中,数组都会被舍弃一部分,我们把完整的搜索树画出来大概是下面这个样子。
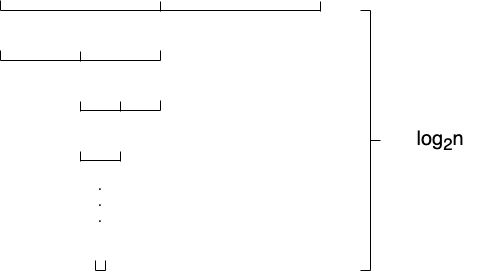
可以看到,虽然总的迭代次数还是\(log_2n\)次,但是每一层当中遍历的元素个数不再是n。我们假设每次迭代数组的长度都会折损一半,到数组长度等于1的时候结束。我们把每一层遍历的长度全部相加,就得到了一个等比数列:
这个等比数列的长度是\(log_2n\),我们套用等比数列求和公式:
也就是说虽然它的形式看起来和快排很接近,但是由于我们在遍历的过程当中,每次都会缩小遍历的范围,所以整体的复杂度控制在了\(O(n)\)。当然这也只是理想情况下的复杂度,一般情况下随着数据分布的不同,实际的复杂度也会稍有浮动。可以理解成乘上了一个浮动的常数。
之前我们分析快排的时候曾经得出过结论,如果原始数组是逆序的,那么快排的复杂度会退化到\(O(n^2)\)。我们当前的快速选择算法和快排算法几乎如出一辙,整个的思路是一样的,也就是说,在数组是逆序的情况下同样会遇到复杂度降级的问题。不过好在这个问题并不是不可解的,我们下面就来分析一下关于这种情况的优化。
优化探索
优化目标很明显,就是极端情况下复杂度会出现降级的情况。问题出现的原因也已经知道了,是由于数组逆序,并且我们默认选择最后一个元素作为标杆。所以想要解决这个问题的入手点就有两个,一个是数组逆序的情况,一个是标杆的选择。
相比于标杆的选择来说,数组逆序情况的判断不太可取。因为对于不是严格逆序的数组,也一样可能出现复杂度很大的情况。如果我们通过逆序数来判断数组的逆序程度,又会带来额外的开销,所以只能从标杆的选择入手。之前我们默认选择最后一个元素,其实这并不是元素位置的问题,无论选择什么样的位置,都有可能出现对应的极端情况使得复杂度升级,所以简单地改变选择的位置是不能解决问题的,我们需要针对这个问题单独设计算法。
一个比较简单的思路是我们可以选择首尾和中间三个位置的元素,然后选择其中第二大的元素作为标杆。这种方案实现简单,效果也不错,但是分析一下的话,其实没有从根本上解决问题,因为依然还是可能出现极端情况,比如首尾和中间刚好是三个最大的元素。虽然这个概率比单个元素出现最大降低了很多。还有一个问题是,这样选出来的标杆不能保证分割出来的数组是平衡的。
BFPRT算法
这里要给大家介绍一个牛哄哄的算法,说它牛不是因为它很难,而是因为它真的很牛。它的名字叫BFPRT,是由Blum、Floyd、Pratt、Rivest、Tarjan五位大牛一起发明的。如果你读过《算法导论》的话,一定会找到其中好几个人的名字。该算法可以找到一个比较合适的标杆,用来在快排和快速选择的时候切分数组。
算法的流程很简单,一共只有几个步骤:
- 判断数组元素是否大于5,如果小于5,对它进行排序,并返回数组的中位数
- 如果元素大于5个,对数组进行分组,每5个元素分成一组,允许最后一个分组元素不足5个。
- 对于每个分组,对它进行插入排序
- 选择出每个分组排序之后的中位数,组成新的数组
- 重复以上操作
算法思路很朴素,其实就是一个不断选择中位数的过程。我们先来证明它的正确性,我们假设最终选出来的数是x,一个长度为n的数组会产生n/5个分组。由于我们取的是中位数的中位数,所以在这n/5个分组当中,有一半的中位数小于x,还有一半大于x。在中位数大于它的分组当中至少有3个元素大于等于它,所以整体而言,至少有 n/10 * 3 = 0.3n的元素大于等于x,同理也可以证明有30%元素小于等于x。所以最坏的情况选出来的x是70%位置的数。
最后,我们来分析一下它的复杂度,我们可以得到一个不等式:
其中\(T(\frac{n}{5})\)是寻找\(\frac{n}{5}\)个中位数的复杂度,\(T(\frac{7n}{10})\)是递归的最坏的情况,即只能减少30%数组的长度。\(cn\)是我们使用插入排序进行多次排序的复杂度,这里的c是一个常数。
我们很容易可以证明\(T(n)=T(\frac{n}{2}) + cn\)和\(T(n)=T(\frac{7n}{10}) + cn\)都是\(O(n)\)的复杂度,这里我们证明一下前者作为一个例子:
我们把这个式子累加起来,可以得到:
同理,我们也可以证明\(T(n)=T(\frac{7n}{10})+cn\)也是\(O(n)\)的算法,所以\(\displaystyle T(n) \leq T(\frac{n}{5}) + T(\frac{7n}{10}) + cn\)也是\(O(n)\)的算法。
根据BFPRT算法的定义很容易写出代码:
def bfprt(arr, l=None, r=None):
if l is None or r is None:
l, r = 0, len(arr)
length = r - l
# 如果长度小于5,直接返回中位数
if length <= 5:
arr[l: r] = insert_sort(arr[l: r])
return l + length // 2
medium_num = l
start = l
# 否则每5个数分组
while start + 5 < r:
# 对每5个数进行插入排序
arr[start: start + 5] = insert_sort(arr[start: start + 5])
arr[medium_num], arr[start + 2] = arr[start + 2], arr[medium_num]
medium_num += 1
start += 5
# 特殊处理最后不足5个的情况
if start < r:
arr[start:r] = insert_sort(arr[start:r])
_l = r - start
arr[medium_num], arr[start + _l // 2] = arr[start + _l // 2], arr[medium_num]
medium_num += 1
# 递归调用,对中位数继续求中位数
return bfprt(arr, l, medium_num)
这个代码写出来了之后,剩下的就容易了,改动量并不大,只需要加上两行即可。:
def quick_select(arr, k):
n = len(arr)
if k >= n:
return arr
# 获取标杆的下标
mark = bfprt(arr)
arr[mark], arr[-1] = arr[-1], arr[mark]
buffer = []
while arr:
mark = arr.pop()
less, greater = [], []
for x in arr:
if x <= mark:
less.append(x)
else:
greater.append(x)
if len(less) == k:
return buffer + less
elif len(less) < k:
k -= len(less)
buffer += less
arr = [mark] + greater
else:
arr = less
看代码的话和上面基本上没有什么差别,唯一的不同就是选择之前先获取了一下标杆。在这里我只是在一开始的时候调用了一次,当然也可以在while循环里每一次都调用,不过我个人觉得没什么必要,因为在获取标杆的时候,会将数组全部打乱,足够避免极端情况了。
今天的文章篇幅有点长,但内容还可以,尤其是BFPRT算法,真的是非常经典,算得上是不复杂但是很巧妙了。感兴趣的同学可以了解一下它背后五个大佬的故事,估计比我的文章精彩得多。
好了,今天的文章就是这些,如果觉得有所收获,请顺手扫码点个关注吧,你们的举手之劳对我来说很重要。
