Hbase存储架构
Hbase通过元数据信息来管理,数据都是通过ReginServer存储在HDFS上
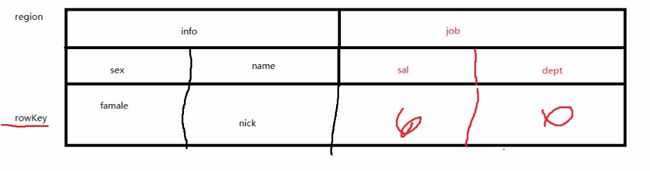
Hbase是列式存储,以rowkey做唯一标识,Rowkey 是一个二进制码流,rowkey里面有多个列族(info,job),一个列族有多个列(sex和name),列下面包含对应的数据(famale,nick)
Rowkey设计原则
rowkey作为hbase里的唯一标识,且是自动排序的,按照abc的顺序排序.Hbase有三种查询方式 通过get方式,指定rowkey获取唯一一条记录 通过scan方式,设置startRow和stopRow参数进行范围匹配 通过全表扫描,即直接扫描整张表中所有行记录
1. rowkey的长度设计原则
rowkey的大小网上大都是说10-100个字节, 在我看来,在唯一标识和可读性识别性的前提下,rowkey越小越好!
2. rowkey散列原则
rowkey要散列是因为它要放到分区里面,假如rowkey不够散列,那很有可能集中到一个分区,导致数据倾斜.降低查询效率
3. rowkey唯一原则
保证其唯一性,可以的话,保证它的可读性,有意性
4. 时间戳rowkey设计
有些事务数据是带时间属性的,那样建议把时间戳放到rowkey中,那样利于检索,提高效率,可以用hash,亦或来打散
Hbase预分区
在建表的时候,要清楚数据的key是怎么分布的,然后再对Hbase的region预分区,也就是多建几个表,这就是Hbase的预分区.rowkey的预分区可以防止rowkey设计不合理的数据插入,可以缓解数据的热写,热写就是数据集中写到一台或者多台机器上,从而提高数据插入的效率
Hbase的读写流程
Hbase读流程
HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在的位置信息,即找到这个meta表在哪个HRegionServer上保存着。
接着Client通过刚才获取到的HRegionServer的IP来访问Meta表所在的HRegionServer,从而读取到Meta,进而获取到Meta表中存放的元数据。Client通过元数据中存储的信息,访问对应的HRegionServer,然后扫描所在HRegionServer的Memstore和Storefile来查询数据。最后HRegionServer把查询到的数据响应给Client。
Hbase写流程
Client也是先访问zookeeper,找到Meta表,并获取Meta表元数据。
确定当前将要写入的数据所对应的HRegion和HRegionServer服务器。
Client向该HRegionServer服务器发起写入数据请求,然后HRegionServer收到请求并响应。
Client先把数据写入到HLog,以防止数据丢失。
然后将数据写入到Memstore。
如果HLog和Memstore均写入成功,则这条数据写入成功
如果Memstore达到阈值,会把Memstore中的数据flush到Storefile中。
当Storefile越来越多,会触发Compact合并操作,把过多的Storefile合并成一个大的Storefile。
当Storefile越来越大,Region也会越来越大,达到阈值后,会触发Split操作,将Region一分为二。