问题描述
5月底到6月初期间,一旦push kafka集群流量到达高峰,Kafka Producer就会出现写入超时,会丢失部分消息。解决此问题周期比较长,是个循序渐进的过程
影响范围:部分topics的推送消息丢失
故障处理人:xxx
处理过程
05月29日 16:00 xxx组织push超时讨论会议,参与人员:xxx、xxx、xxx
05月30日 11:45 push小组xxx反馈相关topics写入超时,希望帮助解决
05月30日 11:55 由xxx牵头创建“push写入超时攻关专项小组”钉钉群,纳入相关同学集中处理
05月30日 20:35 优化kafka broker配置,滚动重启push kafka集群,具体优化项为kafka broker jvm heap配置从32GB降到16GB,随后观察运行情况
05月31日 10:50 调整大流量topics分区数,把push_strategy_interface_user_fast、push_strategy_interface_user_most_fast、push_strategy_interface_user_pool从12调大到72
05月31日 15:20 协助优化客户端代码配置,consumer fetch/次从1MB调大到20MB
06月01日 11:20 所有push kafka上测试topics都逐步迁移到测试环境test-env集群
06月14日 17:47 协助优化客户端producer配置,batch.size和buffer.memory分别从默认值400B和32MB调整到2MB和64MB
06月19日 15:05 配合广告API业务代码修改,push_delivery_interface_user扩大到48
06月20日 13:52 经push小组小伙伴们确认,写入超时问题已圆满解决
定位分析
push kafka集群用户部门反馈,高峰期会出现写入超时情况:
![]()
流量高峰期从监控看网卡流入/流出分别为,高峰期流量超过80%


接着看磁盘延时,高峰期延时时间都超过2.6s
从以下磁盘IO情况,IOPS极其不均衡,在某个时间段有的磁盘使用率偏高,某些严重偏低
通过上面sdi挂载点找到对应目录,对topics的partitions读写频率数据采集,进行降序排序统计,具体情况如下:
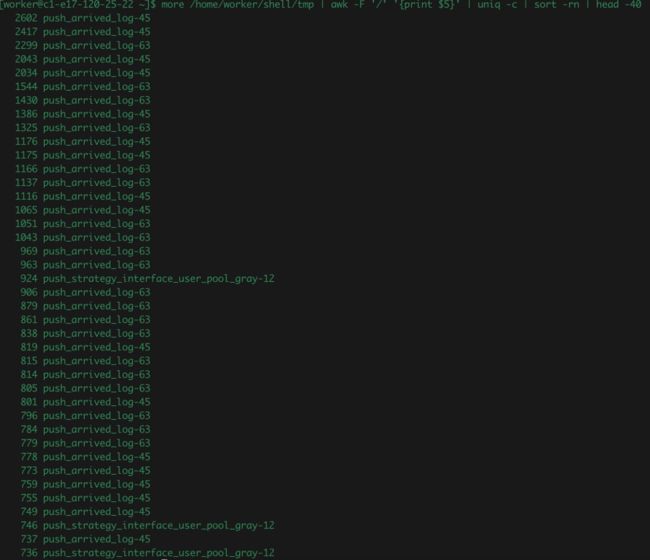
高峰期不同时间点,不断执行上述系列脚本,收集整理出来数据量大、读写高频的topics列表:push_strategy_interface_user_fast、push_strategy_interface_user_most_fast、push_strategy_interface_user_pool、push_delivery_interface_user 分析其对集群资源的使用和影响
这些topics生产环境配置情况如下:
push_strategy_interface_user_fast、push_strategy_interface_user_most_fast、push_strategy_interface_user_pool、push_delivery_interface_user 都只有12个partitions,只分布在12块磁盘上
但是push kafka集群有6个物理节点,每个节点有12块盘,总共72块盘,上述3个topics磁盘使用率只覆盖了16.7%。
降低解决磁盘间IOPS不均衡方法如下:
当前高频大流量topics只是分布在1/6的磁盘上,IO极其不均衡,IO集中在少数磁盘上。push_strategy_interface_user_fast、push_strategy_interface_user_most_fast、push_strategy_interface_user_pool三个topics统一调整到72个partitions保证能覆盖80%以上磁盘,push_strategy_interface_user_pool需要配合业务修改代码partitions扩展到48。以上4个topics扩展完成后,然后观察效果,用户(用户)反馈反馈producer写入超时有所缓解,但依然没有完全解决。
继续优化
用户反馈依然有超时现象,只是会比以前少些,下载用户项目代码,继续优化,优化方案如下:
1.consumer fetch request 降低频次 更大datchunk/perfetch
2.replica fetch request 降低频次 更大datchunk/perfetch
3.IOPS较均衡分布到所有磁盘 分摊IO压力
4.producer batch messages/persend
用户反馈超时日志和持续时间大幅减少,但依然存在问题:
经过优化后,再次分析相关监控数据,延迟最高延时时间降到了700ms

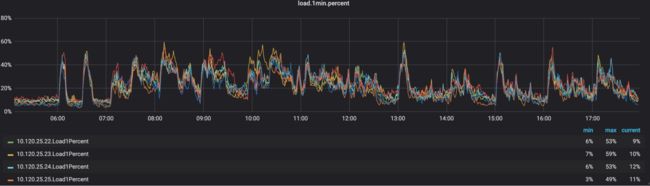
以上延时最高700ms、cpu 55%、load 60% 都在合理安全范围内,kafka broker指标正常,留有充足的buf
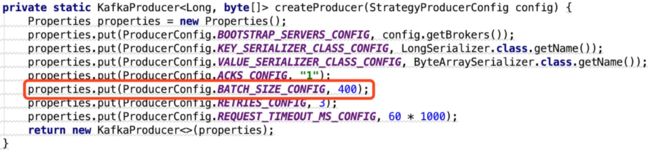
ProducerConfig.BATCH_SIZE_CONFIG:public static final String BATCH_SIZE_CONFIG = "batch.size";
用户部门误以为batch.size为消息条数,实际是字节数下面kafka-client中RecordAccumulator类中append方法逻辑
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
batchSize小于单条message大小,则设置为message实际大小batch.size:批量发送大小(默认:16384,16K)缓存到本地内存,批量发送大小,意思每次最大发送16K到broker。当多个记录被发送到同一个分区时,生产者将尝试将记录批处理成更少的请求。这有助于客户机和服务器上的性能。此配置以字节为单位控制默认批处理大小。
综上所述,用户部门producer配置,每次生产请求不是批量发送消息,而是单条消息发送,没有充分利用kafka打包一批消息一次性发送的优势,造成了居多劣势。
- batch.size/perrequest太小,produce tps就会过大,会阻塞本地BufferPool,缓存写入速率大于下发broker,造成BufferPool超时过期
- broker磁盘IOPS大幅飙升
- consumer fetch QPS成倍扩大,每次拉取都是小fetch messageset,fetch频率变高
解决方法:
- batch.size从400B改到2MB
- buffer.memory=64MB
用户部门反馈最终效果:

思考总结
为什么花了这么长时间才解决?
因为刚开始用户部门及相关参与同学一致认为是kafka集群存在问题:
第一个原因 1.资源不足,需要加机器扩容 2.kafka集群不稳定,造成的映像好像是push kafka集群经常出问题 这样无形中我们压力和重心都盯在了服务端Kafka集群上,随着服务端问题逐步解决,但producer写入超时痼疾依然存在,自然会考虑到用户客户端可能存在问题。
第二个原因 解决优化,需要收集并观察大量在线性能metrics,然后系统化分析,再制定优化手段,然后再观察,循环往复的过程。而且push的流量是一直是变化的,只有早上和晚上才有流量高峰,需要时间耐心等待。
第三个原因 在6月以前用户部门就反馈写入超时问题了,根据此前解决rdkafka的经验和分析,需要集中投入大量时间,调整优化并做运行时数据分析,才能使kafka集群达到更佳状态,当时的重心在解决其他问题,没法抽身集中时间和精力专门解决此问题。
后续工作
