Raid1源代码分析--同步流程
同步的大流程是先读,后写。所以是分两个阶段,sync_request完成第一个阶段,sync_request_write完成第二个阶段。第一个阶段由MD发起(md_do_sync),第二个阶段由守护进程发起。
如果是用户发起的同步请求。该请求下发到raid1层,首先进入同步读函数sync_request。在正常的成员盘中,将所有active可用的盘(rdev->flags中有In_sync标记)设置为read盘,而所有不可用的盘不做设置。对每一个可用盘对应的bios[]都单独申请页结构,对所有的read盘下发读请求,读成功之后,每块read盘对应的bios[]的页结构中都存放有该read盘中的内容。当所有读请求都完成之时,将r1_bio添加到retry_list队列,交由守护进程处理。接着,切换到守护进程,守护进程获取到retry_list中的内容,判断r1_bio->state为R1BIO_IsSync。然后调用同步写函数sync_request_write来进行同步写操作。接着顺序遍历成员盘的bios[],找到第一个读成功的bio。然后将其与其他所有读成功的bio做对比,如果有不一致的页,那么将不一致的页拷贝到这些其他的读成功bio中,并将这些bio也标记为写请求,并将所有的写请求下发,写成功返回;所有页都是一致的盘,则不用下发写bio。见图1。
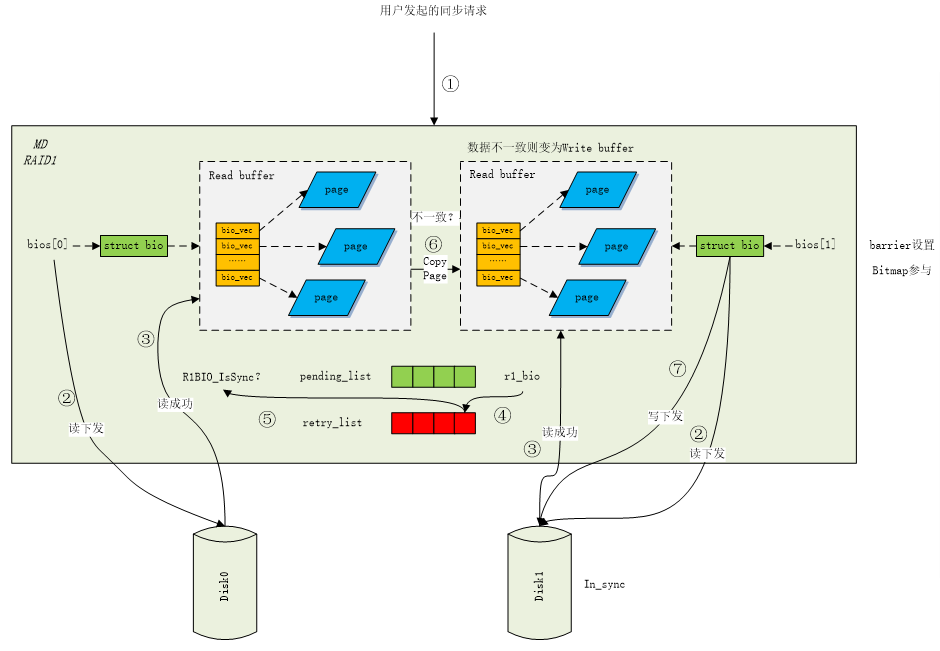
图1 用户发起的同步流程
如果是非用户发起的同步请求。该请求下发到raid1层,首先进入同步读函数sync_request。在正常的成员盘中,将有In_sync标记的盘(标记在rdev->flags上)设置为read盘,将没有In_sync标记的盘设置为write盘,对所有找不到的或Faulty盘不设置读写。所有成员盘对应的bios[]都共享一份页结构,选取一个read盘下发读请求,读成功之后,该块read盘中的内容读取到bios[]的页结构中。当读请求完成之时,将r1_bio添加到retry_list队列,交由守护进程处理。接着,切换到守护进程,守护进程获取到retry_list中的内容,判断r1_bio->state为R1BIO_IsSync。然后调用同步写函数sync_request_write来进行同步写操作。接着该函数将除了执行读操作的盘之外的所有盘都标记为WRITE盘,并将写操作下发。由于所有成员盘的bio都共享一份页结构,所以写操作下发的均为读操作读取到这份页结构的所有内容。见图2。
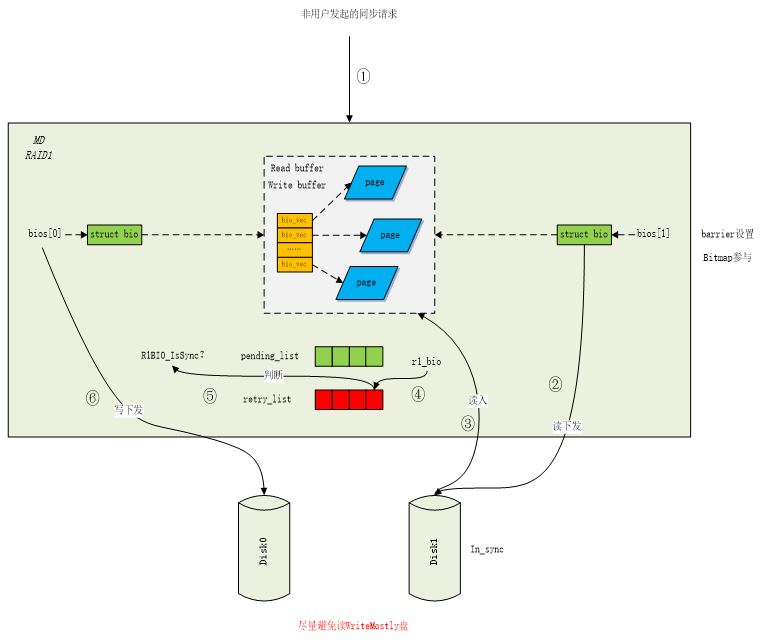
图2 非用户发起的同步流程
1)同步读函数sync_request
函数在MD进行同步操作时调用,作用是对设备上指定的chunk进行数据同步。入参go_faster指示是否应该更快速进行同步。
具体代码流程如下:
1. 如果同步缓存的mempool没有设置,则此时创建。
2. 如果同步位置不在盘阵内,可能同步出错了,或者已经完成同步。更新bitmap的相关信息,并结束同步过程。
3. 如果没有指定bitmap(只有置位的bit对应的chunk才需要进行同步),并且盘阵没有必要进行同步(磁盘正常工作时设置了mddev->recovery_cp = MaxSector),并且没有设置同步请求位(!test_bit( MD_RECOVERY_REQUESTED, & mddev-> recovery)),并且conf设置为不需要全同步(conf->fullsync == 0,fullsync表示阵列要强制完全同步),则设置该段数据跳过,结束返回。
4. 如果bitmap(bitmap_start_sync)认为无需同步,并且没有设置同步请求位(!test_bit( MD_RECOVERY_REQUESTED, & mddev-> recovery)),并且conf设置为不需要全同步(conf->fullsync == 0),则设置该段数据跳过,结束返回。
5. 如果当前设备请求队列忙于处理其他非同步类的访问,并且没有设置快速同步(go_fast为0),该同步请求就延时等待一会。如果设置了快速同步则没有延时等待这一步。
6. 在盘阵上设置barrier,保证盘阵的同步操作不受其他操作打扰。同样,这里也有bitmap的相关设置。
注:raise_barrier(conf),该障碍在同步结束后end_sync_write中调用put_buf清除。
7. 申请r1_bio,具体见r1buf_pool_alloc的流程,将其状态设置为同步状态。
8. 遍历盘阵中所有磁盘,进入循环。
8.1 如果磁盘不存在,或者为Faulty状态,则设置still_degraded 为1,遍历下一个磁盘。
8.2 如果磁盘不为In_sync状态,则就是同步过程写入的对象(非active盘)。
8.3 否则就是同步过程中读的目标。尽量避免通过WriteMostly的盘来读,这是针对系统发起的同步而言的。
注:通过变量wonly和disk来实现。
9. 保证读目标只有一个,其余都是写目标。
10. 如果都为读目标盘,或者都为写目标盘,那么则结束返回。
11. 将max_sector调整为mddev->resync_max,同步不能超过这个值。
12. 构建r1_bio中每个bio的bi_io_vec,将缓存页申请并添加到数组中。直到数组满或者达到一个同步操作要求的数据长度。
13. 如果是用户发起的同步(通过sysfs写入“repair”),则对所有读对象都发起读请求;如果不是,则只发起一个可读的磁盘的读就可以了。
2)同步读结束函数end_sync_read
同步读操作结束后,调用end_sync_read。
- 如果读成功,该函数设置r1_bio的状态为update态(set_bit(R1BIO_Uptodate, &r1_bio->state))。
- 如果r1_bio中所有读都完成了,则调用reschedule_retry将r1_bio插入到盘阵的retry队列中(队列头为conf的retry_list,队列元素为r1_bio的retry_list),唤醒守护进程。
3)同步写函数sync_request_write
守护进程调用sync_request_write,进入同步的写流程。
1. 如果同步是用户发起的。
test_bit(MD_RECOVERY_REQUESTED, &mddev-> recovery)
1.1 前面对所有可以读的对象都发出了读请求,而且也已经读完成了。只要其中一个读成功,则r1_bio的状态会被设置为R1BIO_Uptodate,如果此时r1_bio仍然不为R1BIO_Uptodate,说明所有的读都失败了,此时设置所有读的盘为故障,并且结束同步过程,结束返回。
1.2 找到读成功的第一个盘,递减rdev的下发IO计数。并且将它与从其他盘读的数据比较,如果发现有的盘和第一个读成功的盘数据不同,则将这些盘也列为写入对象,将读成功的第一个盘的数据拷贝到这些盘的对应bio中,跳到步骤4。
2. 如果同步不是用户发起的。由于是在mempool中分配了RESYNC_PAGES个页,所有的bio的bvec都指向它们。这就是说,对于非用户发起的同步操作,读和写的缓存区是同一个,所以不需要单独的拷贝操作。直接进行后面的工作。
3. 如果所有读盘的读操作全部失败了,!test_bit(R1BIO_Uptodate, &r1_bio->state),则进行恢复尝试。
3.1 尝试通过同步访问接口sync_page_io从所有可能的磁盘读出数据块。
3.2 如果读成功,则对这个同步操作的读失败的磁盘,尝试进行一次写,进行一次读(都使用同步访问接口)。
3.3 如果都成功,则说明错误已经被纠正,否则调用md_error将该盘作废。
4. 最后,将所有需要写的盘上的同步bio进行提交。设置bio结束操作为end_sync_write,返回。
4)同步写结束函数end_sync_write
最后,同步写操作完成,调用end_sync_write函数,清除盘阵障碍,释放r1_bio缓存区,唤醒障碍上等待的任务。如果写出错,设置磁盘错误,并且调用bitmap_end_sync将本次同步操作的所有chunk对应的bitmap设置为需要进行同步(needed_mask)操作,下次同步时会尝试恢复这个写错误。
5)一些补充
5.1 读写缓冲区分析
读的数据要写入,应该由读的缓存区拷贝到写的缓存区中,在用户发起的同步中,是在sync_request_write的1.2中执行的。
对于非用户发起的同步而言,这个操作是在r1buf_pool_alloc函数中完成的。在函数sync_request的第一步,r1_bio = mempool_alloc(conf->r1buf_pool, GFP_NOIO); [fp3] 这个语句中,mempool会调用r1buf_pool_alloc进行实际的内存分配。
这个函数在分配r1_bio的缓存区时,除分配了其中的bio数组外,还分配了bio中的bvec页,对于用户发起的同步操作,是每个bio都分配了RESYNC_PAGES个页;对于非用户发起的同步操作,则是分配了RESYNC_PAGES个页,所有的bio的bvec都指向它们。这就是说,对于非用户发起的同步操作,读和写的缓存区是同一个,所以不需要单独的拷贝操作。
r1buf_pool_alloc()函数在sync_request刚开始时调用。具体代码流程如下:
- r1bio_pool_alloc申请一个r1_bio的空间。
- 如果r1_bio不存在,则返回NULL。
- 分配r1_bio中所有盘的bio。
- 如果同步请求是用户发出的,则针对盘阵中的每一个bio分配RESYNC_PAGES个页。
- 如果同步请求不是用户发出的,那么先对一个bio分配RESYNC_PAGES个页,再将盘阵中的其他所有bio指针都指向第一个bio的page页面,也就说所有bio的bvec都指向它们。
关于内存池机制(mempool)多说两句:
首先利用mempool_create()来预先分配一定内存空间,作为一个“备用池”,在raid1中这个机制是用来分配r1_bio结构(包含bio的页结构)。入参min_nr是预分配对象的数目;alloc_fn和free_fn是指向分配和回收函数的指针,在raid1中分别对应的是r1buf_pool_alloc和r1buf_pool_free;pool_data指的是缓冲池对象的一些信息,raid1中pool_data是*mddev和raid_disk。
接着在缓冲池机制中,需要分配r1_bio空间的时候,调用mempool_alloc()。该函数首先在“备用池”外寻求分配空间,如果外面的空间不足,那么就在“备用池”中分配。这样就保证了重要的结构在分配的时候减少因为内存不够导致空间分配失败。
其实就是先在内存中圈一片自留地,表明这是我的家底,不到资源紧缺的危急时刻不会动用它;当有结构分配的内存需求时,就先在自留地外面去寻找,先占用公用的地方;如果公用的地方都被占完了,那就只能占用自留地来满足需求了。
5.2 用户发起的同步的流程中,无WRITE盘的相关操作
最初我怀疑是自己漏掉了某些代码流程,后来分析发现用户发起的同步中没有WRITE盘相关操作的代码是正确的。
sync_request()函数在判断每个盘的bio是否为READ盘或者为WRITE盘,并指定对应的bio->bi_end_io是end_sync_read还是end_sync_write,是根据rdev->flages的In_sync是否置位来判断的。但是,在这一步判断之前,先判断的是rdev->flages的Faulty标志是否置位,如果Faulty置位,那么就不设置READ或者WRITE,也不设置回调函数,此时的回调函数指针指向的是NULL。
而rdev->flages的In_sync标志表示的是这个盘是否active,置位则为active。设置In_sync为0的时候,除去sys接口和do_md_run中的特殊情况,只有下面两种情况:
1、盘阵中的盘出错,调用error()函数的时候;
2、Add disk的时候。
而Add disk时候会由系统发起同步,可能还会在后面将rdev->flages的Insync标志置为1,反正不会是用户来进行这种同步操作,没有具体进到函数中去看。
在盘阵出错的时候,会调用到error()函数,而在清除掉In_sync的时候,会降级,并设置Faulty标志。
在用户发起的同步的时候,rdev->flags的In_sync位为1的盘,一定是READ盘;In_sync位为0的盘,Faulty位一定被置1了,所以不会标记为READ或者WRITE盘,并且bio->bi_end_io还是为NULL。这样一来,用户发起同步的时候,就不存在标记为WRITE的盘了,所以只确定READ盘的一致即可,不标记的盘只可能是error盘,用户发起的同步对其不做任何处理。
而在由于用户发起的同步请求mddev->recovery也带有MD_RECOVERY_SYNC标志位,所以流程会走到write_targets += read_targets-1,于是就不会走到if (write_targets == 0 || read_targets == 0)的判断条件中,从而避免了流程的终止。
所以在用户发起的同步时,流程中找不到WRITE操作的相关代码是正确的。