Bw树:新硬件平台的B树(内存数据库中的b树索引)
Bw树:新硬件平台的B树
1.1 原子记录存储(Atomic Record Stores)
1. 概述
1.1 原子记录存储(Atomic Record Stores)
很多现在讨论的NO-SQL本质上是原子记录存储,很多都是独立的产品,但是也可以使完整事务系统的一个组件。
ARS支持每个独立的记录的读写,记录都是以key来识别。基于树的ARS可以提供更快的key range 扫描。ARS不单单是访问方法,也包含了固态存储的管理,并且要求在系统奔溃之后可以恢复。Bw树就是利用ARS形成新的b树。
1.2 新的环境
处理器已经被修改,不再提高单个内核性能。已经有了以下一些修改:
1. 针对多核的设计:现在大多数的处理器都是高性能多核处理器。单核速度提升变慢,因此为了更好的内核,需要注意以下两点:
a.多核cpu提高了高并发,并发的增加会导致latch的block,限制了可扩展性。
b.好的多核处理器依赖于高cpu cache的hit率。
对于第一点,bwtree是latch-free,这样thread在碰到冲突的时候,不会被yield或者重定向。对于第二点,bwtree使用增量更新,避免page中的更新,保护之前cache line的地址。
2.针对现代存储的设计:磁盘的延迟是主要的问题,flash存储有很快的随机和顺序读取性能,但是因为在写入之前需要先擦除,所以随机写会比顺序写速度要慢。Bwtree会生产日志结构,这种方法可以避免FTL保证写入性能尽量的高。
1.3 实现
1.Bwtree通过mapping table来组织,page的大小和位置被虚拟化。实际上是对latch-free和日志结构的虚拟化。
2.通过在原来的page前加上一个增量记录来更新bwtree。
3.对page的splitting和merge做了设计。SMOs由多个原子操作实现,若thread发现有在处理的SMO操作,并不会堵塞而是来完成SMO操作。
4.日志结构存储(LSS),是名义上的page存储,实际上是通过post增量的修改来提高存储的效率。
5.根据LSS和bwtree来实现ARS。
会做这些实现是因为,认为latch free技术和状态修改避免了update-in-place可以再当前处理器上得到性能提升。
2 Bwtree的体系结构
Bw-tree是典型的b+树,提供对数级的访问,如图: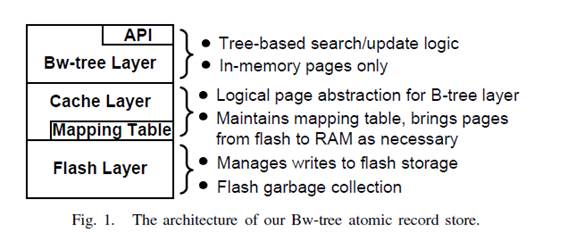
Bw-tree层在最上面,和Cache层交互,cache管理建立在存储层之上,实现了LSS。现在LSS是使用flash存储,但也可以支持磁盘。
2.1 现代的硬件敏感性
在bwtree中,threads基本不会block,消除latch是设计的目的之一。我们使用原子比较切换指令(CAS)来代替latch。Bwtree只会在从固态存储中获取page是才会block(也就是LSS)。持续的threads运行保障了内核指令cache,避免线程的空闲时间和上下文切换的开销。甚至使用增量来更新,而不是update-in-place,从来避免cpu cache的miss,提高cpu cache的hit率。
数据管理系统的瓶颈往往是在IO上,所以我们选用了flash存储,使用SSD挂载,但是还是会限制性能。LSS存储启用了大的写入buffer来消除写入瓶颈,flash存储的高随机读取能力和大缓存组合何以最小化读取的block。大的多页buffer允许我们写入改变page的大小,不需要填充到一个统一的偏移大小。
2.2 Mapping Table
Mapping Table在Cache层维护,mapping table包含了物理页到逻辑页的映射,每个逻辑页都有一个PID来识别。PID可以通过mapping table翻译成内存的物理地址或者flash的偏移地址。Bwtree就是通过PID来构建一个b+树。
mapping table隔离了物理地址和bwtree节点,这样每次修改page或者写入到固态存储不需要把位子的修改传播到树的根部,即更新节点内部的连接。这样的重定向可以支持在内存中的增量修改可以支持在固态存储的LSS。
因为bwtree是逻辑的不是固定的物理地址,就可以根据自己需要制定node的page。
2.3 增量更新
Page的状态改变是通过在原来的page前加一个增量记录来实现的。使用CAS指令把增量记录的物理内存地址放到mapping table的page物理地址栏中。如果成功增量记录地址会变成的page 的新物理地址。这个策略被使用在数据修改,也被使用在树的结构修改。
间歇的来固化page(创建一个新的page把所有的增量修改合并),减少链的长度,提高查询的性能。固化的方式也是通过CAS指令实现,之前的page也会被回收。
在增量更新的同时,可以支持同时在bwtree中做latch-free的访问并且能够防止update-in-place保护cpu cache。Mapping table是bwtree重要的特性,可以隔离直接对node更新。
2.4 bwtree结构修改
Latch并不会对做结构修改的page进行保护,如page split。
为了解决这个问题,就把SMO放在一个顺序的原子化操作中,每个操作都是通过CAS进行。为了保证没有线程等待SMO。如果一个线程看到一个未完成的SMO,会在执行自己的线程前先去完成它。
2.5 日志结构化存储(LSS)
Page批量的顺序写入,大大减少了IO次数。因为回收机制,日志结构通常会有额外的写入来重定位page,用来回收日志的存储空间。
当刷新page的时候,只需要刷新增量部分,增量的部分表示从上次刷新到当前的增量修改。通过增加flush buffer的page数量来减少IO的消耗。但是这样会有读惩罚,因为page中的数据不是连续被存放的。
LSS会清理之前的部分flash,这部分flash表示之前的数据。通过清理,LSS把page和它的增量连续的存放,可以提高访问性能。
2.6 管理事务日志
和传统的数据库系统一样,ARS也要在系统crash时保持数据一致性。通过log sequence number(LSN)来表示每个更新操作。
和传统系统一样,page的刷新的懒惰的,并且依赖于 write-ahead log协议(WAL)。不同的是在WAL之前不会堵塞page的flush。因为现在的update生成的基于之前page的增量。
3 内存中Latch Free Page
这里主要介绍内存中的bwtree page,主要讨论:
1.基本的page结构和如何以latch free 方式更新page
2.page 固化是的查询更加高效。
3.使用epoch的内存回收机制。
3.1 灵活的虚拟页
Bwtree存储的信息和b树类似,索引节点包含了以key排序的key,pointer数据对。数据节点包含key,record对。另外还保存了page中保存的最小的key和最大的key,和一个可以指向右边兄弟节点的指针。
bwtree的page是逻辑的,不是固定物理地址,大小也不是固定的,有了两个重要的特性让bwtree比较特殊:
1.使用PID来识别一个page,使用pid转化为物理地址来访问page。
2.page的大小是灵活的,没有限制page的大小。Page的增长通过增量记录来实现。
3.1.1 更新
更新不会是in-place更新,而是通过创建一个增量记录来描述更新,并放置在当前page之前:
1.创建一个增量记录,指向当前page
2.获取page在mapping table上的项。
3.增量记录的物理地址作为page新物理地址,使用CAS指令来实现install。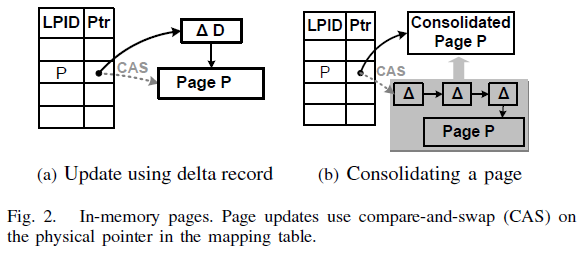
如图,多更新几次之后会形成增量记录链。
3.1.2 叶子级别的更新
在叶子级别,增量分为3种:isnert,update,delete。所有的增量都包含LSN。使用LSN来做还原机制涉及到日志的管理方式必须是WAL。Insert和update增量包含了新的记录,但是delete只要含了要删除的key。
3.1.3 page查询
叶子级别的page查询涉及到增量链的遍历。查询会在第一个查询到的地方停止,若key出现在update,insert就返回,如果是delete那么就查询失败。如果增量链不包含key,查询执行在base page 上的binary查询。
3.2 页固化
随着增量链变成,查询性能会降低,为了避免这种情况,会间歇的执行页固化。会根据增量记录和base page重组生成新的page。页固化会在增量链长度超过阀值是触发。
当固化是线程会做以下操作:
1.创建一个新的page,然后把最新的记录版本写入到page中
2.使用CAS指令install新的page。若成功请求回收老的page,若失败释放新的page。失败并不会重试,后面的线程会继续执行直到完成。
3.3 区间扫描(Range Scans)
区间扫描是对一个指定key区间进行扫描。扫描可以指定顺序还是倒序来获取记录。
扫描维护了一个游标标记扫描的进度。对于新的扫描记录的是lowkey。当扫描碰到第一个在区间内的记录会构建一个向量,并放入向量内。向量用来保存扫描的结果。获取下一行有原子性,但是整个扫描没有。
事务锁会阻止能够看到的记录,但是我们并不知道没有传输的记录。所以在传输之前我们会检查是否有修改。如果有修改,我们会重新构建一个记录向量。
3.4 回收
Latch-free环境不允许排它的访问一个共享数据结构,也就是说即使page在被修改,也可以被访问。我们并不想释放一个任然被访问的内存。比如在固化的时候,线程交换老的page和新的page状态,并回收新状态,但是不能再有线程访问老的page的时候释放。
epoch机制就是为了保护之前有访问的又要释放的对象。
4 bwtree的结构修改
4.1 节点分裂(Node Split)
分裂是由一个后台线程在page的大小超过系统设置的阀值的时候就进行分裂。整个过程分为2个阶段:
1.现在叶子上做split.
2.然后更新父的节点.
如果有必要可以一直向上递归。因为有了blink指向兄弟节点,就可以把split分为2个独立的操作。
4.1.1 子节点分裂(Child Split)
为了分裂节点P,大概分为2步:
1.btree层先分配一个节点Q,然后找到合适的key的位置Kp,把大于Kp的key复制到Q,然后Q的side link指向R。
2.在P之前加入一个Split delta记录,记录包含了2个信息,a.在P中key大于Kp的都不可用。Side link指向Q。这个时候索引还是可用的,尽管父节点O中没有指向Q。所有包含在Q的key都会被指引到P上。到了Split Delta发现key大于Kp那么就会从 side link被指引到Q上。
4.1.2 更新父节点
为了能够直接从父节点O指向到Q,需要在O上加一个delta record,这个delta record包含3个信息:
1.Kp,P和Q的分隔key。
2.一个指向Q的指针
3.Kq,Q的分隔key,原来是P的分隔key。
在delta record出现边界key Kp,Kq是一种优化可以提高查询速度,因为查询必须遍历index节点上的delta chain,若发现要查询的key在Kp和Kq之间就可以马上指向Q没必要在去遍历整个index节点了。
4.1.3 固化
相对于增加delta来说,使用新的base page在split的时候延迟会加大。减少延迟也减少了split的错误。
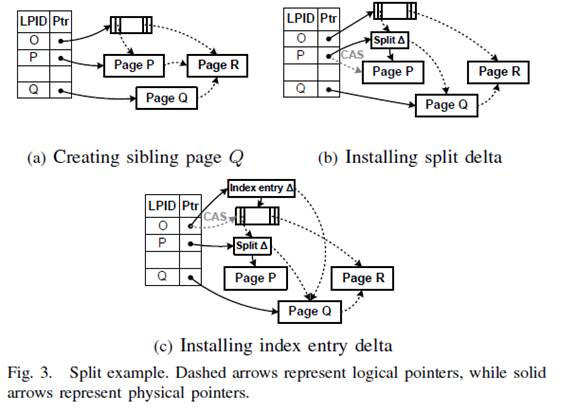
4.2 节点合并(Node Merge)
和分裂类似,节点合并是当node低于一个值的时候就会发生。
1.删除节点,如要合并R,先在R上标记删除,添加一个delta record,表示R已经被删除。如果一个线程要读取R中的数据碰到Remove Node Delta Record,就会应用在左边的兄弟上。
2.合并孩子节点,在L上添加一个node merge delta物理的指向R(使用内存地址),这样就表示R中的数据是在节点L中。R的存储状态被传换成了L,只有当L固化的时候page R才会被回收。当对L查询时,变成对树的查询,可以再L中访问L中和R中的key。为了让这个可用正常,merge delta上会有key的分隔,用于访问正确的节点。
3.更新父节点,通过使用delete delta删除父节点上关于R的索引信息和L的Key信息。
一旦在父节点加上了delta,所有到R的路径就全部被堵塞了。就可以启动机制来回收R了,因为epoch的保护机制,所有直到所有的线程访问完之后才会被回收。
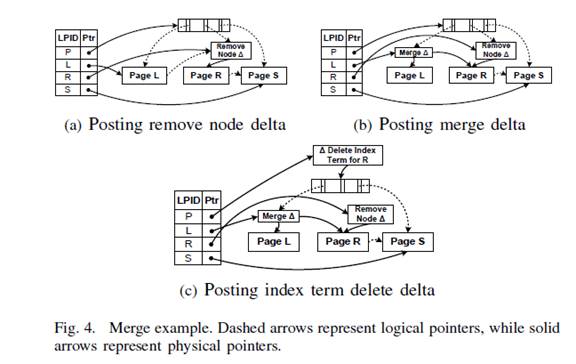
4.3串行结构修改和更新
为了正确的序列化SMOs和数据修改,SMOs和SMOs,我们需要构建一个在bwtree上的序列化调度。我们想要把SMO当成一个原子化操作,并且没有Latch。为了满足这个需求,所以线程必须在更新数据,或者执行自己的SMO之前完成之前的SMO操作。
5 缓存管理
Cache层是负责对读取,刷新和内存与flash之间page交换。维护mapping table提供抽象的逻辑页给bwtree。在mapping table上要不就是内存地址,要不就是flash的偏移。如是flash偏移那么就从LSS上读入到内存中。所有涉及到内存的操作都是通过CAS来完成。
有很多原因会导致内存被刷入到flash中。如,因为bwtree是事务系统的一部分所以flush update可以在事务日志上checkpoint。Page flush也处理page 换出吧flash偏移install到mapping table上,并且回收内存减少内存的使用。
为了跟踪固态存储中page 的版本和位置,我们使用flush delta record,还记录了那些修改被flush了,之后的flush只对应增量即可,若flush page成功,flush delta就会包含新的flash offset,page的状态会被设置为flushed。
5.1 提前写日志协议和LSN
Bwtree是ARS(原子记录存储),可以被包含在事务系统里,若被包含就在事务方面被强化。LSN:记录的插入和修改都会使用LSN来标记,而被flush的最大LSN被记录在flush delta上。事务日志协作:不管什么时候TC(事务控制器)flush到固态存储上,左右一个LSN被称为ESL。所有小于ESL的LSN都会被刷新到固态存储中。然后TC定期的把ESL发送到DC,根据提前写日志协议,DC不能刷新大于ESL的数据。
DC中的page flush是由TC根据redo-scan-start-point(RSSP)来要求的,这样RSSP之前的日志都可以被截断。TC会等待来自DC的通知,表示LSN<RSSP的数据都已经被固化了,因为这样数据被固化,在redo 的时候就没必要再去redo这些日志了。
5.2 Flush页到LSS
LSS提供了一个很到的buffer,里面存放了bwtree的结构修改和数据修改。
5.2.1 page 排列
Cache manager把page中的byte以线性方式写入flush buffer。Page的状态在试图刷新的时候被获取。这个很重要,因为之后的修改可能会和split或者固化冲突。
5.2.2 增量flush
当flushpage,缓冲管理器只排列那些ESL>LSN的增量的记录。增量flush表示刷新的消耗要比刷新整个page 小。日志结构存储有2个好处:
1.flush buffer可以包含更多的update
2.回收不需要很频繁因为消耗不是很大。
5.2.3 Flush活动
Flush buffer聚合了LSS到达一个阀值(1MB)然后写入,这样减少了IO的开销。并且使用双buffer,这样当前的buffer还在处理时,可以准备下一个进程了。
flush buffer IO完成之后,相关page 的状态就会被修改。Mapping table获取flush的结果然后使用flush delta来描述。
缓冲管理监控bwtree的内存使用,超过配置的阀值,会视图把page切换到lss上,一旦page被清空,就会从缓存中被牺牲。被牺牲的page 通过epoch被回收。
6 性能评估
主要介绍 bwtree和其他存储结构的性能对比
6.1 实现和安装
BWtree:bwtree以独立的记录原子存储实现,借用了win32原生的CAS interlockedCompareExchange64。
BerkeleyDB:BerkeleyDB是k-v数据库,我们使用c语言实现了btree模式。
Skip list:跳表可以实现latch-free,可以实现快速插入以及对数级的查询。
测试环境:Intel Xeon W3550,24GB内存
测试数据库:XboxLive,Storage deduplication trace,Synthetic
默认:主要性能的单位是million/sec。为每个工作负荷提供8个工作线程和逻辑内核数一样。
6.2 Bw-tree调整和属性
这节主要介绍2方面对bwtree的性能影响:
1.delta chain的长度对性能影响: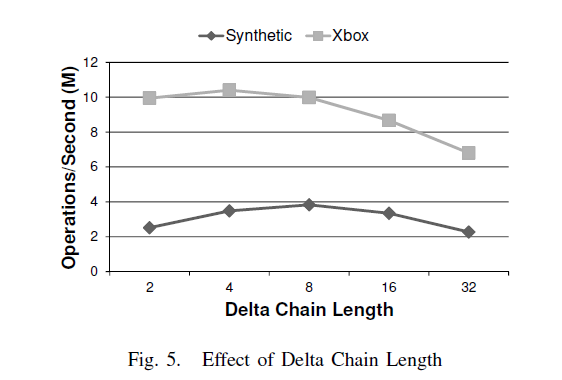
如图,bwtree运行在Synthetic和Xbox不同的delta chain对性能的影响。即consolidation阀值。对于小的阀值,consolidation会频繁出现,影响性能。对于xbox,查询性能在阀值大于4之后开始恶化。虽然顺序扫描,分支预测性能良好,因为xbox行100byte,使得L1的填充率下降。synthetic只有8byte大小,因此delta chain可以更长,性能也不受影响。
2.latch free使用CAS,CAS的错误率:bwtree原生latch-free,在某些情况下会出现更新page状态的错误。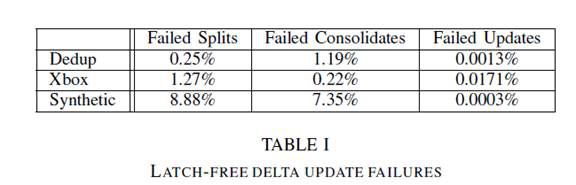
更新错误率很低大概占用0.02%的工作负荷。split,consolidation比update错误率大得多,这个也是在预料中的,因为他们会和update是竞争关系。synthetic是一个极端场景,因为update性能很好,导致split,consolidation的错误率很高。
6.3 bw-tree和传统btree对比
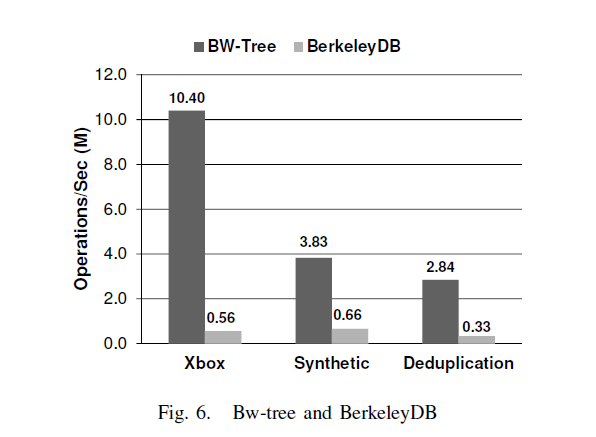
主要导致性呢过问题的有2个原因:
1.latch-free,bwtree没有latch,但是berkelydb确有性能问题。
2.cpu,cache效率,bwtree使用delta record来进行更新,base page不变,cpu cache很少出现不可用的情况。但是BerkeleyDB是in-place update,会导致更多的cpu cache不可用的情况。
6.4 Bwtree和Skip list比较
Skip list可以提供有序的对数查询,并且很容易实现latch free。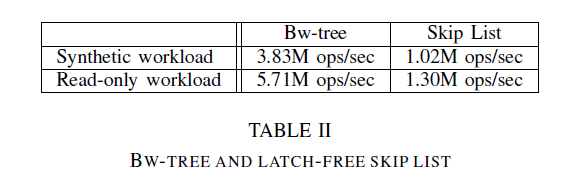
如图比较了在bwtree和skiplist下的性能,bwtree比skiplist性能要好。是因为bwtree的cpu cache的效率比skiplist 要搞。
6.5 Cache的效率
为了更深入的测量和比较bwtree和skiplist,我们使用intel VTune来获取cpu cache的hit。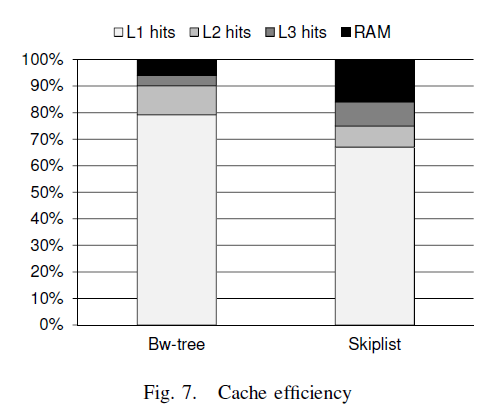
通过如图,会发现bw-tree的cache hit率比skiplist要高,这个也就是为什么bwtree性能比skiplist好的原因。
参考: